BizTalk Integration Development Architecture
Editor’s note: The following post was written by Microsoft Integration MVP Leonid Ganeline
BizTalk Integration Development Architecture
If company uses BizTalk Server extensively over the years, great number of the BizTalk applications are created and scheduled to creation. These applications might be related of each other, might be independent, but they all work in shared BizTalk environment. If we are not applying some sort of discipline in implementation, the BizTalk deployment would be a complete mess.
BizTalk provides broad spectrum of tools and functions out of box. It forces developers use some patterns and implementation methods. But several functions are not covered by BizTalk and developers have to use some techniques to implement this functionality. Also some functionality is implemented inconsistently throughout BizTalk and developer has many ways to use these features.
Architecture here provides some important limitations on the used techniques hence simplifies the implementation, makes it clear and understandable.
One example is the BizTalk deployment. BizTalk provides many ways to deploy the BizTalk artifacts into run-time environments. Without organizing the deployment process, we can easily reach the point where our BizTalk system would looks like jungle. We could not deploy anything without breaking something, we could not fix any bug without risk to break something, and we could not improve our system without changing something unrelated to our modification.
So the architecture would provide us with limitations and rules. The architecture would provide us with shared technological pieces and shared methods and principles. The architecture is a method to greatly simplify development, deployment and management, it is a method to be more productive and create more reliable solutions.
You can find some architecture information into the BizTalk documentation. You find out several tutorials and good amount of samples. Almost all of them related to the infrastructure architecture, i.e. how to create high available systems with clusters, how to scale out the BizTalk systems, etc. I am going to cover development aspects of architecture.
Why am I using here the Integration term in the BizTalk Integration, not the Project, nor the Solution, nor the Application terms? The Project, Solution and Application terms are used for concrete artifacts, but in this case Integration means several Visual Studio Solutions, several BizTalk Applications, and many-many BizTalk Projects. In this context the BizTalk Integration means all BizTalk Applications on single BizTalk computer or cluster.
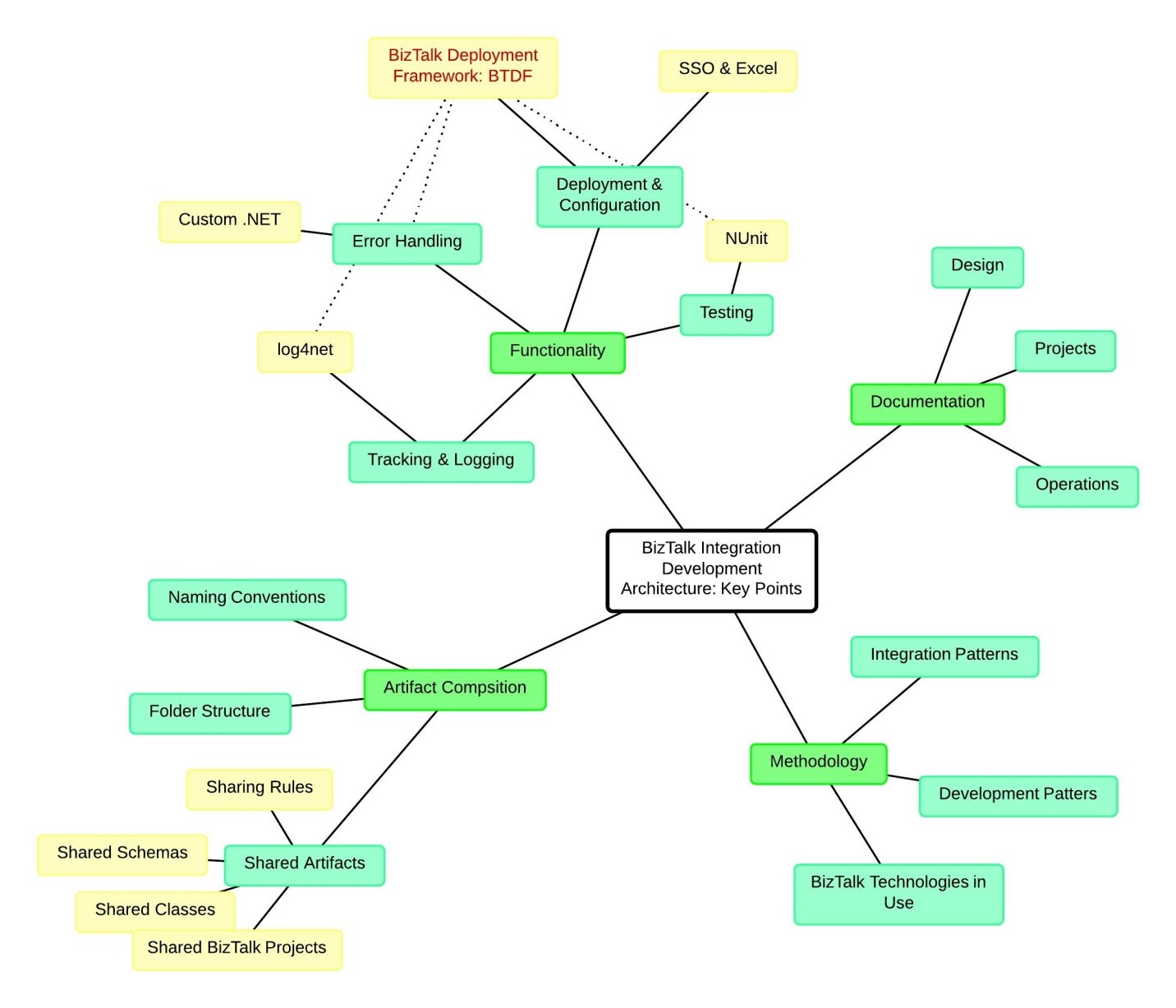
Architecture of typical big BizTalk Integration has several generic parts and architecture points. Big Integration means there are more than 10 BizTalk applications which of course are composed from all sorts of artifacts: schemas, maps, orchestrations, pipelines, pipeline components, helper .NET classes, ports, etc.
As it happens in my experience, big BizTalk Integration is usually architected in these key points:
- Artifact Composition
- o Naming conventions
- o Folder structure
- o Shared Artifacts
- Functionality
- o Deployment and Configuration
- o Tracing and Logging
- o Testing
- o Error Handling
- Documentation: Design, Projects, Operations
- Methodology
- o BizTalk technologies in use
- o Development patterns
- o Integration Patterns
By any means it is not a complete list. In your implementation it might look different and this is OK. It is not a recommended list. It is just a sample of one of possible architecture approach.
The Questions
I am going to focus on several architectural aspects which can be expressed by these questions:
What is wrong with this BizTalk feature?
Here I am going to discuss the Cons of a BizTalk feature. Why we have to create the additional artifacts, why don’t use an existed BizTalk feature?
What are the trade-offs?
There are always several solutions of one problem. The best solution always has drawbacks and we should clearly understand them.
How do we want to improve?
Our improvement should be measured clearly and understandable. The success or failure measurement could not be based on vague perception.
How does a typical implementation look like?
The implementation sample and pattern keeps developer on the right road and speeds up development.
Architecture pieces
The Artifact Composition
Generic Rules
- A Visual Studio solution defines exactly one BizTalk application. A “Visual Studio solution” and a “BizTalk application” terms can be used in the same places without explicit announcement. Both must use the same name. It is prohibited to spread one solution into several applications or one application into several solutions!
- A Visual Studio project defines exactly one .NET assembly. A “Visual Studio project” and a “.NET assembly” terms can be used in the same places without explicit announcement. Both must use the same name. It is prohibited to spread one project into several assemblies or one assembly into several projects!
Naming Conventions
Artifact composition and naming conventions are two sides of one coin, both mirrors the same object hierarchy. We create our architecture model and implement it in the naming conventions. Clear, elegant naming conventions mean clear, elegant model and opposite.
Here I am showing a typical naming convention for the BizTalk Integration. It is little bit boring, so feel free to jump over it. J
Name definitions
Composite names are names composed from several words in Pascal format without separating symbols.
Examples: MySoulution, PatientRecord.
Artifacts can use full names or logical names.
Logical names are composite or single-word names with or without separating symbols [.-_/]. A logical name defines a logical entity within logical hierarchy.
Examples: MyCompany.SeattleOffice, MyDomain-DepartmentA, MySolution_Internal, Schemas.SystemX.
Full names are compounded from logical names separated by separating symbols. Full names express logical hierarchical grouping.
Examples: MyCompany.MyDomain.MySolution.Schemas.
Naming Conventions Syntax
I use these naming conventions as source information.
Generic Naming conventions:
<Word> =:
[A-Z][a-z1-0]*
<CompositeName> =:
<Word>[._]<Word>[[._]<Word>]
<LogicalName> :=
<Word>[.<Word>]
<CompositeName>
<Company> =:
<Domain> =:
<Solution> =:
<LogicalName>
<Namespace> =:
<Company>.<Domain>.<Solution>
Naming conventions for Visual Studio artifacts:
<VSSolutionFullName> =:
<BizTalkApplication> =:
<Namespace>
<VSProject> =:
<Assembly> =:
<DotNetNamespace> =:
<Namespace>.<VSProjectLogicalName>
<SolutionsRootFolder> =: c:\Solutions
<SolutionFolder> =:
<SolutionsRootFolder> \ <Namespace>
<ProjectFolder> =:
<SolutionFolder> \ <Project>
<OrchestrationProject> =:
<Namespace>.Orchestrations
<SchemaProject> =:
<Namespace>.Schemas
<MapProject> =:
<Namespace>.Maps
<PipelineProject> =:
<Namespace>.Pipelines
<PipelineComponentProject> =:
<Namespace>.PipelineComponents
<TargetNamespace> =:
https:// <Domain> . <Company> .com/ <SolutionLogicalName> / <ProjectLogicalName> / <Version>
<Version> =:
<date> [in YYYY-MM-DD format]
Naming Conventions for BizTalk Artifacts:
<Orchestration> =:
<LogicalName>
<Schema> =:
<LogicalName>
<LogicalName>_FF [for Flat File schema]
<Map> =:
<SourceSchema>_to_<DestinationSchema> [for one-to-one map]
<SourceSchema1>_and_<SourceSchema2>_to_<DestinationSchema> [for two-to-one map]
<Pipeline> =:
<LogicalName>
<Port> =:
<Namespace>.<LogicalName>
<ReceiveLocation> =:
<Port>.<TransportType>
Shared Artifacts
This picture does not embrace all BizTalk artifacts but only several most used artifacts.
It shows relations between the BizTalk artifacts:
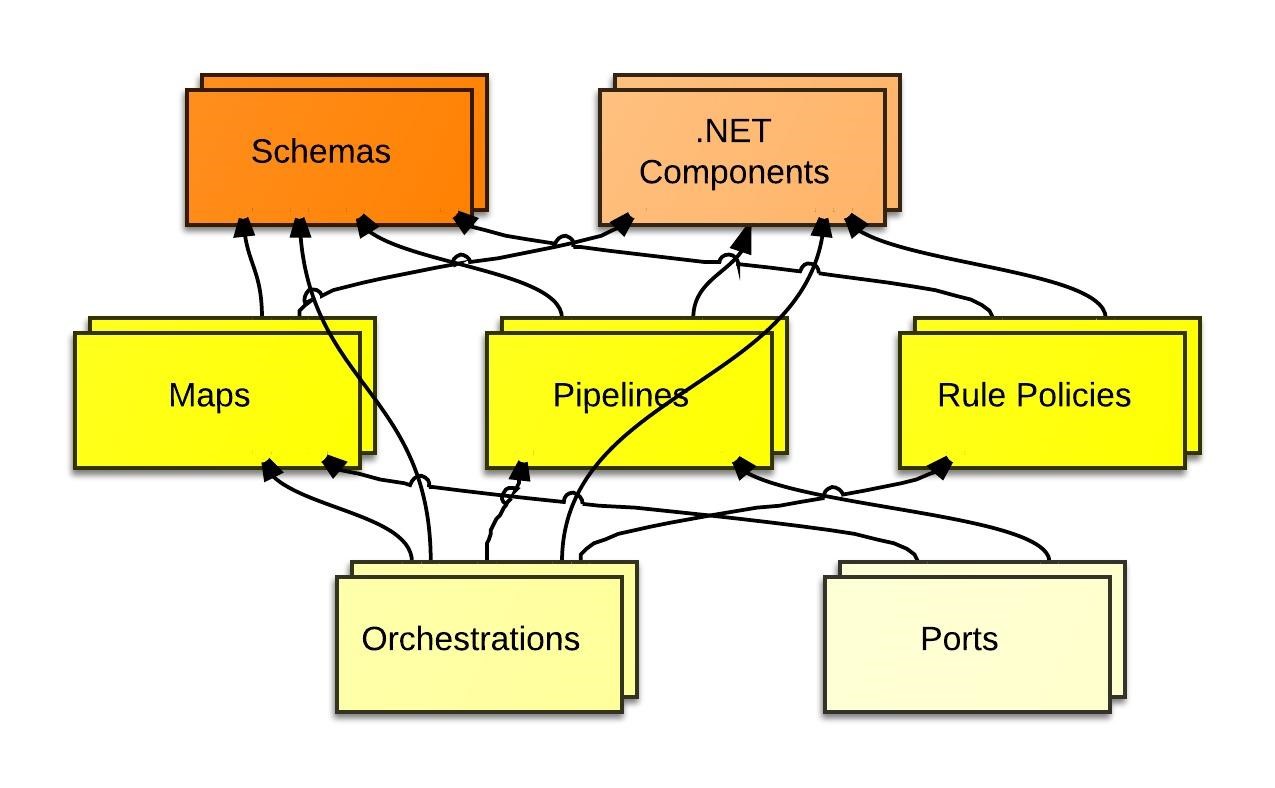
As you can see schemas are the most used and the most elementary artifact. Maps, orchestrations, pipelines use schemas not the opposite. Schemas play one of the most important roles in integration. The distributed systems integration is based on contracts and XML schema is one of the implementation of a contract. If we share only schemas, our artifacts will be loose coupled.
BizTalk and Integrated Systems exchange data usually in strictly defined formats, the contracts. Once defined the contracts should be kept stable and rarely be changed.
This concept forces us to pay a special attention to the schemas in the integration architecture. Also this forces us to use several simple rules:
- Place schemas in a separate project;
- Place independent schemas in separate projects.
Let’s assume the BizTalk application integrates two systems, A and B. Our rules force us to create at last three schema projects: SchemasA, SchemasB, SchemasInternal. AssemblyA (with SchemaA) is exposed to the BizTalk application and to the system A; AssemblyB (with SchemaB) is exposed to the BizTalk application and to the system B; AssemblyInternal (with schemas used only internally) is accessible only for the artifacts of this BizTalk application.
One integrated system in the big BizTalk Integration can be integrated with several BizTalk applications. That is why it is hard to predict if the schemas will be used in one or in several applications.
Makes sense to place all schemas, exposed by integrated systems, to a separate solution. This creates one place where contracts are stored and managed. We will keep our guns in the arsenal under good control.
Here is an example of such solution in the real-life solution:
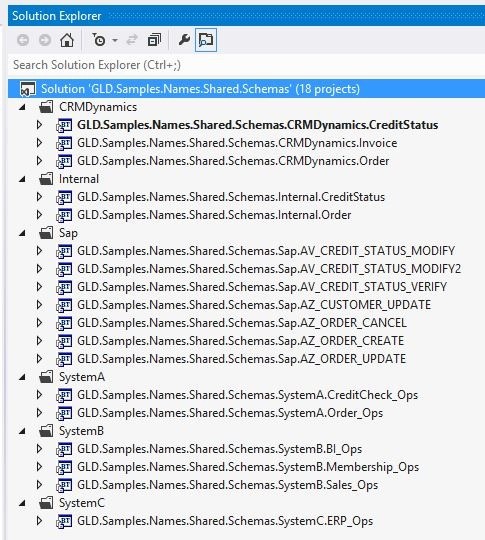
It has the Shared.Schemas name.
Folder Structure
Folder structure should follow the solution structure. Here is an example for the Shared.Schemas solution folder structure:
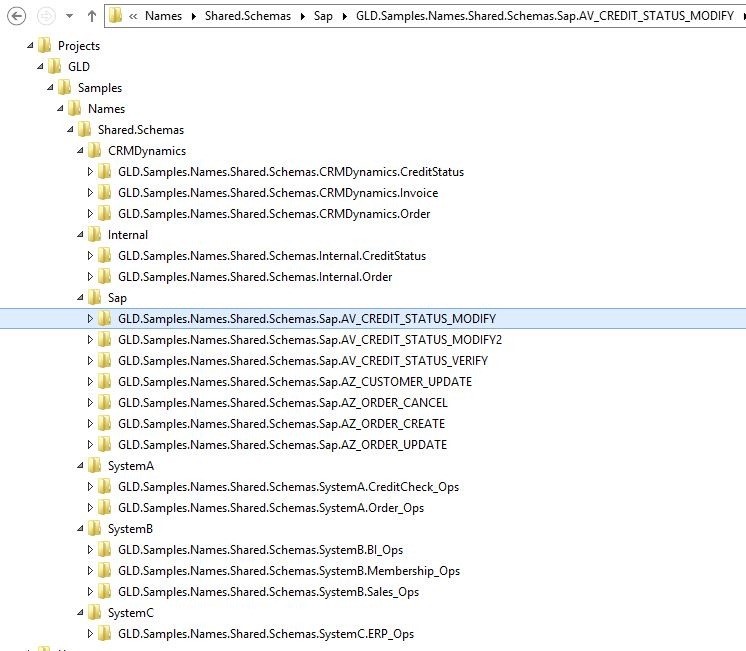
The detailed discussion of the Artifact Composition will be in the next article, “the BizTalk Integration Development Architecture: Artifact Composition”.
Documentation
Documentation is an essential part of the architecture for big BizTalk Integration.
Documentation is a single entry point for all interested people including developers, administrators, and stakeholders.
Big BizTalk Integration is created not as a single project but as several independent projects developed by different teams, with different goals, different requirements, and different skills. It is important to perform the architecture reevaluation of the code base at last once a year. The main part of this job is to keep documentation up to date.
Good documentation means the integration is kept on the architect radar. It means the stakeholders know the present and the future of company integration.
Bad documentation means bad management, lack of resources, and lack of perspective.
I prefer to use hierarchical document model. Document model mirrors the architectural model. A single document, “The BizTalk Deployment Architecture” is on the top of the hierarchy. The document structure has several main parts: the Design documents, the Operation documents, and the Project documents.
Design documents map the main chapters of this document.
Design documents:
- Naming Conventions
- The Artifact Composition
- Deploying
- Tracking and Logging
- Error Handling
- Testing
- Integration Patterns
- Development Patterns
- BizTalk Technologies in Use
- Other Design Information
Operation documents are usually heavily influenced by the corporate standards. So the following document list will probably different for you.
Operation documents:
- Monitoring
- Settings, Tuning up
- Maintenance
- Disaster Recovery
- Other Procedures
A project document describes only information specific for this project. All generic information should be placed in Design or Operation documents. It is not permitted to place the generic information inside the project documents.
Project documents:
- <ProjectName> project
- …
The document templates will be provided in one of the next article, “the BizTalk Integration Development Architecture: Documents”.
Functionality
Detailed Functionality discussion will be provided in one of the next article, “the BizTalk Integration Development Architecture: Functionality”.
Deployment and Configuration
There are many different objects (artifacts) in BizTalk Server with different deployment process. Deployment for orchestrations, business rules, BAM tracking profiles, ports, pipeline components, .NET helper classes, configuration parameters is not the same.
Deployment order is very important. If applications share some artifacts, small fix can force you to redeploy not just single assembly but several of your applications.
Deployment in the multi-server installation adds complexity.
Deployment in several environments (Development, Test, Staging, and Production) makes configuration even more complex.
For big BizTalk Integration we have now only one choice, the BizTalk Deployment Framework (BTDF) . It is a free tool on Codeplex, created by Scott Colestock and Thomas Abraham. This great tool puts together all deployment steps and enormously simplifies deployment and configuration.
It is the mandatory tool for the big BizTalk Integration. Many architectural choices here are made because of the BTDF. For example, BTDF supports log4net and NUnit out-of-box, so these utilities are natural choice.
Tracking and Logging
These two terms are very alike in a BizTalk environment. Logging is different in a way it works all the time and registers important events as the host instance starts or stops. Tracking is something that developers include in code to track information useful for debugging. Logging is small and fast and does not harm performance; it is usually turned on all the time. Tracking is heavier; it produces more information and harms performance. It can be turned on only in special occasions like bug investigations or testing.
I agree, it is not a classic definition of logging and tracking, it is how I use it here.
BizTalk Server implements logging internally for many important events like errors or changing state of run-time artifacts. We cannot manage this logging and there isn’t any API to control it. This internal logging is not the consistent across the events, does not have consistent format. So it is hard to use it for everyday monitoring without additional custom log viewers.
There is a massive implementation of tracking in the BizTalk Server. We can turn on tracking for almost all run-time artifacts, as orchestrations, ports, pipelines. Tracking data consists mostly from the messages and message context. Tracked date stored into tracking databases. Tracking coverage is broad. The bad things about it in BizTalk are the BizTalk doesn’t have good tools to dig through the tracking data, it doesn’t have an API to access the tracking data, and tracking harms performance badly. So usually BizTalk tracking is turned on only for short period of time and looking though the tracked data is slow process and requires long learning. As a result the BizTalk tracking is not good for development and testing but only for the bug investigations.
One of the possible solutions for tracking and logging is to use standard logging library like Enterprise Library Logging block, or NLog, or log4net. The EL is not competitor here because of several drawbacks. It is the most complex package in our list, it is the slowest, and the most important drawback is the EL is used inside the ESB Toolkit which creates versioning problems. NLog is the most contemporary library. But log4net is chosen because it is supported by the BizTalk Deployment Framework.
Log4net is used for both tracking and logging. Only limited set of events is registered in logging mode, the events that are important for the everyday monitoring and error handling. In tracking mode additional information is registered including message bodies and message flow. Log4net output is easily tuned up. Development effort to use log4net is minimal.
Logging data is written into the log files and into the Windows event log for the data auditing, into notification emails for immediate error handling.
Tracking data is written additionally into the debug output for testing and debugging.
Error Handling
Error sources
Errors raised in BizTalk Server in several main places: orchestrations and ports. Other artifacts are usually included in orchestrations or in ports, so an error in a map, for example, will be raised by an orchestration or by a port, which nests this map.
- Ports: here is a standard way to handle errors on ports. We set up the “Enable routing for Failed Messages” option on the ports. This promotes several special context properties on the failed message. We use these properties to subscribe to the failed messages. A typical error handling is to create a failed message subscriber: a send port or an orchestration, which receives failed messages, created a well-formatted notification and send it as a record to the database and/or an email to the interested parties. Without such this option set up, the failed messages are suspended.
- Orchestration: this case a little bit more complex. Whey error raised, we are usually interested in all existed messages of this orchestration. If a port fails there is only one message, if an orchestration fails there can be many messages in failed orchestration. It would be great, if we compound all those messages and send them as single message to the error subscribers.
The BizTalk Server has the ESB Toolkit with special Exception Handling features. Using ESB Toolkit API we can attach all messages to single fault message and publish it. Processing of this message can be the same as for ports or using ESB Toolkit again. Fault message (a single fault message or a fault message with several attached messages) can be saved in the ESB Toolkit Exception database and processes on the Exception Portal.
We have to decide which way is preferable: create the custom error handling code or use ESB Toolkit.
The log4net utility is also used for logging the errors and raising the error notifications.
Before start to implement error handling we should classify our errors and decide how to process different sorts of errors.
Testing
BizTalk has several options for the functional testing. There is a good tooling for the map testing. But there is nothing for the application testing. Typical testing done with additional file send test ports and file receive locations. Unfortunately there is any two-way file port which makes challenging the testing for the two-way endpoints like most of the WCF and enterprise ports.
There are several options to create tests for the BizTalk applications, the Visual Studio test functionality and the old NUnit, which is luckily supported by BTDF.
Visual Studio test functionality is abundant. Cons of it, it is hard to deploy test harnesses from Development environment to other environments. It creates too many relations in the deployment package and too many pieces should be deployed. This is a real problem for the Production environment where the Visual Studio is not installed.
NUnit requires only couple additional libraries, which is the key argument for using NUnit. Moreover NUnit is luckily supported by the BizTalk Deployment Framework. So our decision is to use NUnit.
There is also additional BizUnit library. BizUnit is good test library but it is not mandatory. The newest .NET Framework libraries cover most of the BizUnit features. One drawback with BizUnit is, the BizUnit documentation is scarce and you spent a lot of time learning.
It is hard to implement continuous integration in the BizTalk Integration but it is desirable.
Methodology
Detailed Methodology discussion will be provided in one of the next article, “the BizTalk Integration Development Architecture: Methodology”.
About the author

With 9+ years BizTalk Server experience Leo is working as a BizTalk Developer, Architect, and System Integrator.
He got awards: The Microsoft Most Valuable Professional [MVP] Awards 2007, 2008, 2009, 2010, 2011, and 2012 in BizTalk Server; The Microsoft MVP Award
2013 in Microsoft Integration.
Leo is a Moderator of the BizTalk Server General forum on the Microsoft MSDN site, he is a blogger [https://geekswithblogs.net/LeonidGaneline/ and https://ganeline.wordpress.com/] and
author of the Microsoft TechNet articles and MSNS Gallery/Samples.
About MVP Monday
The MVP Monday Series is created by Melissa Travers. In this series we work to provide readers with a guest post from an MVP every Monday. Melissa is a Community Program Manager, formerly known as MVP Lead, for Messaging and Collaboration (Exchange, Lync, Office 365 and SharePoint) and Microsoft Dynamics in the US. She began her career at Microsoft as an Exchange Support Engineer and has been working with the technical community in some capacity for almost a decade. In her spare time she enjoys going to the gym, shopping for handbags, watching period and fantasy dramas, and spending time with her children and miniature Dachshund. Melissa lives in North Carolina and works out of the Microsoft Charlotte office.