SQL Server: Auto Statistics Cleanup
Editor’s note: The following post was written by SQL Server MVP Ami Levin
Abstract
SQL Server creates statistics objects automatically to enable the Query Optimizer to make the right plan
choices based on estimated costs. This is an intelligent and useful feature that takes away some of the burden of manually managing statistics. However, when these statistical objects start accumulating over time, they may start incurring unnecessary performance hits. In this article we will investigate this little-known issue and build a solution that will help you clean up your database.
Background
What are statistics objects in SQL Server?
Statistics objects are (surprise…) a collection of statistical information about data in a particular column or set of columns from a table or an indexed view. Statistics objects include a histogram of the distribution of the values in the first column and may include additional information about the correlation statistics (densities) of values among the columns.
For a detailed discussion of statistics, see https://msdn.microsoft.com/en-us/library/ms190397.aspx
What are statistics used for?
SQL Server’s query optimizer uses that statistical information to estimate the selectivity of a query. The selectivity is estimated based on the actual data value distribution from the statistics objects. This estimate of the expected number of rows for each operator of the query is used to estimate the associated costs of potential plan choices. This information is crucial to the query optimizer’s ability to choose the lowest
cost, optimal execution plan and run your workload at peak performance.
How do statistics get created?
Statistic objects are created automatically for every index created on the table. You can create additional statistics by using the CREATE STATISTICS statement. Statistics objects are so important for the operation of the SQL Server engine that Microsoft decided to help users by minimizing the need to manually create them. By default, the query optimizer will create statistics whenever it encounters a query for which a column’s distribution of data may have an impact on the plan operator costs. These statistics are known as “auto created statistics” or “auto-stats” in short. You can control this feature by setting
the database option AUTO_CREATE_STATISTICS using the ALTER DATABASE … SET statement. You can easily distinguish auto-stats by their unique naming
convention:
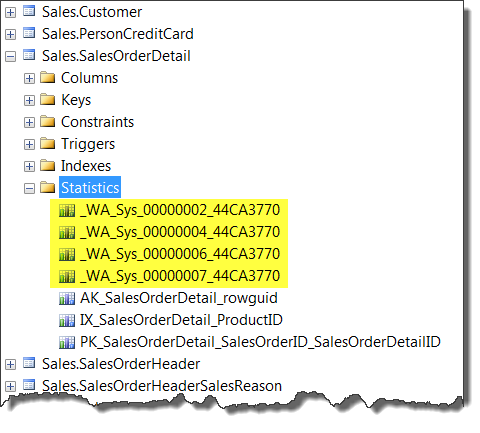
Figure 1 - Auto Stats in SSMS Object Explorer
Note: You can download the AdventureWorks 2012 database used for the examples in this article from https://msftdbprodsamples.codeplex.com/releases/view/55330.
The naming convention is actually quite simple – the _WA_Sys_ is s fixed prefix, the next number represents the column’s ordinal number in the table and the last section is a hexadecimal representation of the table’s object ID. If you prefer T-SQL, you can use the sys.stats DMV:
SELECT O.Name AS Table_Name,
S.Name AS Stat_Name
FROM sys.stats AS S
INNER JOIN
sys.objects AS O
ON S.[object_id] = O.[object_id]
WHERE S.auto_created = 1
AND
O.is_ms_shipped = 0
Should statistics be maintained?
As the data in the table changes, statistics become obsolete. Out of date statistics can fool the optimizer into choosing sub optimal plans which may significantly impact performance. Statistics can be explicitly updated by using the UPDATE STATISTICS statement. By default, SQL Server will update the statistics automatically whenever the data in the table has passed a certain change threshold, meaning
that enough values for the given index columns have changed, added or deleted. You can control this feature by setting the database option AUTO_UPDATE_STATISTICS using the ALTER DATABASE … SET statement. SQL Server chooses the sample size automatically based on the number of rows in the table. Sample size used to create the statistics may range from less than 1% for very large tables and up to 100%, or
a full scan, for smaller tables.
The Challenge
Auto stats accumulate over time
Since auto-stats are created implicitly and quietly behind the scenes, most DBAs are unaware of how many really exist. For every query that any client ever issued against the database, there may be a remaining statistics object created just for it. Even if it was a test query, issued once many years ago and never again. The statistics objects are persistent and will remain in the database forever until explicitly dropped. I’ve seen databases containing tens of thousands of such auto created statistics and one with > 300,000!
So what?
Statistics updates are expensive
The process of updating statistics consists of sampling a certain number of rows, sorting them and building a histogram of values with aggregate information per histogram step. If you run profiler and capture the SQL:BatchCompleted and the Showplan XML events and issue the following statement:
USE AdventureWorks2012;
GO
UPDATE STATISTICS sales.salesorderdetail
You will see that several plans are created, one for update of each statistics object, and each may look something similar to the plan
diagram in figure 2:

Figure 2 – Typical Statistics Collection Plan
You can see that it involves fetching data from the table into memory, segmenting it into steps, sorting and aggregating. For tables like SalesOrderDetail in our example, which are less than ~8MB, the statistics update doesn’t use sampling but scans the entire table. Of course, for larger tables only a small percentage of the rows is sampled by default. However, since each individual statistics gets updated independently of others, the costs add up as more and more objects need to be maintained. I’ve seen many cases where statistics updates for a single column took several seconds to complete. For some workloads, the default sampling is not good enough and a full scan sampling must be performed to produce accurate enough statistics which in turn lead to optimal plan choices. For those workloads, these costs increase dramatically.
Accumulating + Expensive = Trouble…
“A few seconds to complete” for a statistic update may not sound like much but for frequently modified OLTP systems, with many tables and columns, it may be detrimental. I’ve seen many cases where the DBAs resorted to switching off automatic update of statistics during daytime workload (at the risk of getting sub-optimal plans) and running custom scripts at off-peak hours to maintain statistics up to date.
And what do auto stats have to do with that?
Well, auto stats have to be maintained like any other statistics. It’s a price you must pay to get better plans which means better performance. However, what performance gains do these auto stats provide? For databases that have been around for a while, it is safe to assume that at least some auto stats exists which were created to serve a query pattern used long ago but no longer exists. Some of those statistics become redundant as data changes. Index tuning efforts over the years may have created indexes on columns which already had auto stats on them and now both are maintained.
The big question is – how do we know which one can we drop and which one should we keep?
The Solution
“Just drop ‘em all Jack”.
This may sound like a radical idea at first, but think about it. What do you have to gain or lose? Dropping all auto stats will place some temporary stress on the system. As queries come in, the query optimizer will begin recreating those statistics that we just dropped. Every query that adheres to a certain pattern that requires a statistics to be created, will wait. Once. Soon, typically in a matter of minutes for highly utilized systems, most of the missing statistics will be already back in place and the temporary stress will be over. But now, only the ones that are really needed by the current workload will be re-created and all the redundant ones just came off the expensive maintenance tab.
TIP: If you are worried about the impact of the initial statistics creation, you can perform the cleanup at off-peak hours and ‘warm-up’ the database by capturing and replaying a trace of the most common read only queries. This will create many of the required statistics objects without impacting your ‘real’ workload.
How many are redundant? There is no way to tell unless you try… The risk is very low, so why not see for yourself?
Run the following query to count how many auto stats you have in your database:
USE [Master];
GO
SET NOCOUNT ON;
-- Table to hold all auto stats and their DROP statements
CREATE TABLE #commands
(
Database_Name SYSNAME,
Table_Name SYSNAME,
Stats_Name SYSNAME,
cmd NVARCHAR(4000),
CONSTRAINT PK_#commands
PRIMARY KEY CLUSTERED (
Database_Name,
Table_Name,
Stats_Name
)
);
-- A cursor to browse all user databases
DECLARE Databases CURSOR
FOR
SELECT [name]
FROM sys.databases
WHERE database_id > 4;
DECLARE @Database_Name SYSNAME,
@cmd NVARCHAR(4000);
OPEN Databases;
FETCH NEXT FROM Databases
INTO @Database_Name;
WHILE @@FETCH_STATUS
= 0
BEGIN
-- Create all DROP statements for the database
SET @cmd = 'SELECT N''' + @Database_Name + ''',
so.name,
ss.name,
N''DROP STATISTICS [''
+ ssc.name
+'']''
+''.[''
+ so.name
+'']''
+ ''.[''
+ ss.name
+ ''];''
FROM [' + @Database_Name + '].sys.stats AS ss
INNER JOIN ['
+ @Database_Name + '].sys.objects AS so
ON ss.[object_id] = so.[object_id]
INNER JOIN ['
+ @Database_Name + '].sys.schemas AS ssc
ON so.schema_id = ssc.schema_id
WHERE ss.auto_created = 1
AND
so.is_ms_shipped = 0';
--SELECT @cmd -- DEBUG
-- Execute and store in temp table
INSERT INTO #commands
EXECUTE (@cmd);
-- Next Database
FETCH NEXT FROM Databases
INTO @Database_Name;
END;
GO
At this point, switch the query results output to “text” by clicking Ctrl + T or from the Query menu, select “Results to” and “Text”.
WITH Ordered_Cmd
AS
-- Add an ordering column to the rows
to mark database context
(
SELECT ROW_NUMBER() OVER (
PARTITION BY Database_Name
ORDER BY Database_Name,
Table_Name,
Stats_Name
) AS Row_Num,
*
FROM #commands
)
SELECT CASE
WHEN Row_Num = 1
-- Add the USE statement before the first row for the
database
THEN REPLICATE(N'-',50) + NCHAR(10) + NCHAR(13)
N'USE [' + Database_Name + '];'
+ NCHAR(10) + NCHAR(13)
ELSE ''
END
+ cmd
FROM Ordered_Cmd
ORDER BY Database_Name,
Table_Name,
Stats_Name;
-- CLEANUP
CLOSE Databases;
DEALLOCATE Databases;
DROP TABLE #commands;
Select all the rows from the results pane and you now have a script that you can paste back into the query window, modify, schedule it, and segment it to run by database that will remove all existing auto created stats
from all databases on your server.
NOTE: I recommend running the DROP statements at off-peak hours. These statements may deadlock on schema locks with concurrent sessions. If it happens and you see deadlock errors, just run the script again
to finish the job.
Conclusion
SQL Server creates statistics objects automatically to enable the Query Optimizer to make the right plan choices based on estimated costs. While this is a very useful feature that eliminates manual creation and maintenance of statistics, it can grow to present undesirable overhead on systems in which these auto-created statistics are not periodically culled. The utility script include in this brief paper provides an easy mechanism to assess how many auto-created statistic objects are present, and optionally delete them via the same T-SQL script.
The author would like to thank Tom Huguelet and MVP Douglas
McDowell for their technical review.
About the author

Ami Levinis a Microsoft SQL Server MVP and a Mentor with SolidQ. He has been consulting, teaching, and speaking about SQL Server worldwide for the
past 15 years. Ami’s areas of expertise are data modeling, database design, T-SQL and performance tuning. Follow him on Twitter.
About MVP Monday
The MVP Monday Series is created by Melissa Travers. In this series we work to provide readers with a guest post from an MVP every Monday. Melissa is a Community Program Manager, formerly known as MVP Lead, for Messaging and Collaboration (Exchange, Lync, Office 365 and SharePoint) and Microsoft Dynamics in the US. She began her career at Microsoft as an Exchange Support Engineer and has been working with the technical community in some capacity for almost a decade. In her spare time she enjoys going to the gym, shopping for handbags, watching period and fantasy dramas, and spending time with her children and miniature Dachshund. Melissa lives in North Carolina and works out of the Microsoft Charlotte office.