Nemeth Braille—the first math linear format
The 6-dot Nemeth braille encoding was created by Abraham Nemeth for mathematical and scientific notation and is general enough to encode almost all of the Microsoft Office math notation. He started working on his encoding in 1946 and it was first published in 1952 by the American Printing House for the Blind. It’s a little like the UnicodeMath linear format. Like UnicodeMath, spaces play important roles and Nemeth braille is a globalized notation, so localization isn’t needed except for embedded natural language. Also both formats strive to make simple things easy and concise at the cost of additional syntax rules. But because a mere 64 codes (including the space) are used to encode virtually all of math notation plus a variety of other things, the semantics of the codes depend heavily on their contexts. This level of complexity contrasts with UnicodeMath which has the luxury of the exhaustive Unicode math symbol set. Accordingly, encoding math expressions can become quite tricky as revealed in the full specification. For a less daunting intro, see this Nemeth Code Cheat Sheet. Nemeth recounts some history in this 1991 interview. The present post describes aspects of Nemeth braille and compares how Nemeth braille, UnicodeMath, and TeX express subscripts/superscripts, fractions and integrals. Nemeth braille does have some multidimensional constructs for compound fractions, matrices, long division, etc. This post doesn't deal with such constructs.
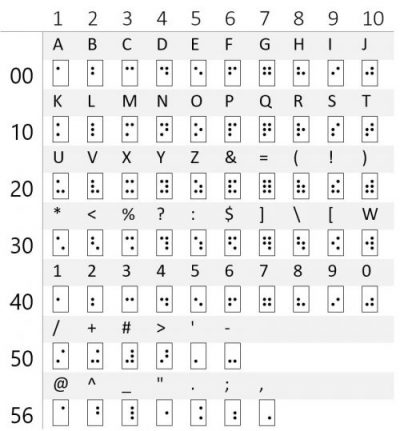
First note that Nemeth Braille can be displayed in 6-dot ASCII Braille as shown in this table
The dots are numbered 1..6 starting from the upper left, going down to 3 and continuing with 4..6 in the second column. The letters and numbers look like themselves as do the / and (). The braille cells for 1..9 are the same as those for the letters A..I, but shifted down one row. The cells for the letters K..T are the same as those for A..J but with a lower-left dot (dot 3). Letters are lowercase unless prefixed by a cap prefix code (solo dot 6) or pair of cap prefixes for a span of uppercase letters.
A simple table look up converts Nemeth braille codes to 8-dot Unicode Braille in the U+2800 block. The braille cells for 6-dot braille are the first 64 characters of Unicode braille block. With a little practice you can enter braille codes into Word, OneNote, and WordPad by typing 28xx <alt+x>, where xx is the hex code given by the braille dots. To do this, read dots as binary 1’s and missing dots as 0’s, sideways from right to left, top to bottom. So ⠮ is 1011102 = 2E16 and the corresponding Unicode character is U+282E.
To get a feel for simple Nemeth braille math, consider the expression 12x2+7xy-10y2. In ASCII Braille it displays as
#12x^2"+7xy-10y^2_4
In Nemeth Braille it displays as

In UnicodeMath and TeX, it displays as 12x^2+7xy-10y^2.
It’s tantalizing that the superscript code ⠘ has the ASCII braille code ‘^’ used by UnicodeMath and [La]TeX. But the subscript code is ⠰, which has the ASCII braille code ‘;’ instead of the ‘_’ used by UnicodeMath and TeX. These braille codes also work differently from the UnicodeMath and TeX superscript/subscript operators in that they are script level shifters that must be “cancelled” instead of being ended. So in the formula above, the Nemeth ‘^’ for the first square is cancelled by the ‘"’, while the ‘+’ terminates the superscript for UnicodeMath and a TeX superscript consists of a single character or an expression of the form {…}. The following table compares how the three formats handle some nested superscripts and subscripts
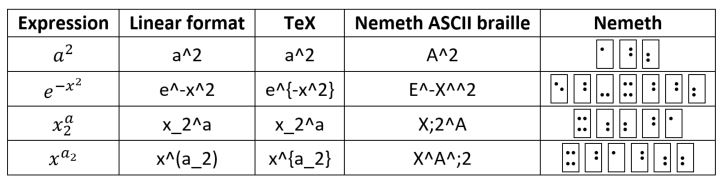
Here to keep the Nemeth braille code sequences simple, I’ve omitted the Nemeth math italic, English-letter prefix pair ⠨ ⠰ before each math variable. Hopefully there’s a way to make math italic the default, as it is in UnicodeMath, MathML, and TeX, but I didn’t find such a mode in the full specification. A space before literary text terminates the current script level shift, that is, it initiates base level. This is also true for a space that indicates the next column in a matrix, but it’s not true for a function-argument separator as illustrated in the table below. Spaces can also be used for equation-array alignment (you need to think in terms of a fixed-width font).
Simple fractions are written in a fashion similar to TeX’s {<numerator>\over <denominator>}. For example,
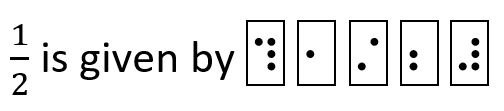
or in ASCII braille as ?1/2#. The ⠹ and ⠼ work as the curly braces do in TeX fractions as in {1\over 2}. In UnicodeMath, the fraction is given by 1/2. Fractions can be laid out in a two-dimensional format emulating built-up fractions but using Nemeth braille. Nested fractions require additional prefix codes (solo dot 6). For single-line braille devices it seems worthwhile to use the linear display since the fraction delimiters can be nested to any depth. Stacked, slashed, and linear fractions can be encoded and correspond to those structures in UnicodeMath and in TeX.
The Nemeth alphabets are similar to the Unicode math alphanumerics discussed in Sections 2.1 and 2.2 of Unicode Technical Report #25. One difference is that math script and math italic variants exist for English, Greek, Cyrillic, and German (Fraktur) alphabets, whereas in Unicode math script variants are only available for the English alphabet. We may need to generalize Unicode’s coverage in this area, since TeX also has the ability to represent more math alphabets (see, for example, Unicode Math Calligraphic Alphabets).
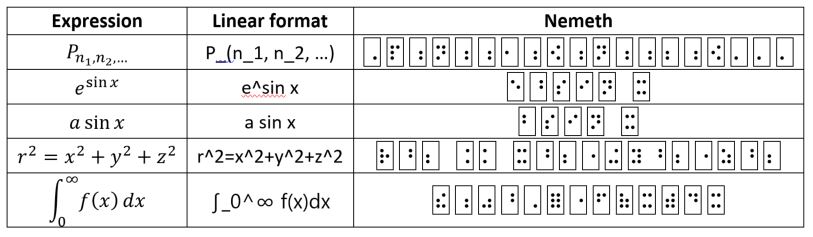
At some point, I hope to give a listing of correspondences between UnicodeMath and Nemeth Braille. It’s a long topic, so as a start the following table gives some more examples. Note the spaces needed around the equals sign (and other relational operators), but the lack of a space between the 'a' and "sin" in "a sin x" . The Nemeth notation is ambiguous with respect to using asin for arc sine.
The Unified English Braille code can handle quite general mathematics as well. See the UEB Guidelines for Technical Material. UEB math braille tends to be less compact than Nemeth math braille, but that disadvantage is offset somewhat by having fewer rules to learn. Nemeth math zones can be embedded into UEB documents as discussed in Guidance for Transcription Using the Nemeth Code within UEB Contexts.
One possible way to reduce the large number of rules governing Nemeth braille would be to use an 8-dot standard in which math operators could be encoded with the aid of bottom row dots. This would work with current technology since Braille displays let you read and enter all possible 8-dot Braille codes. In fact, dot 7 is sometimes used to change lower case into upper case, thereby not needing an upper-case prefix code (solo dot 6) for upper-case letters.
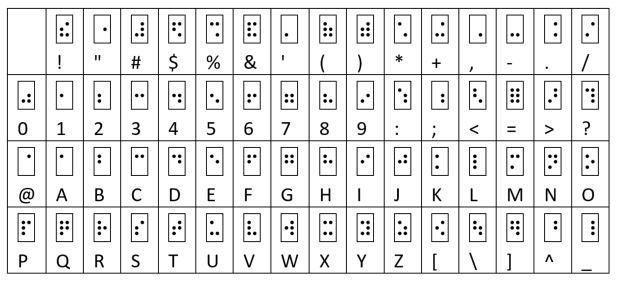
Here's a Braille ASCII table that's in the original braille order. Compare the 00 line with the lines 10-40 to see how the braille codes are related. Each code is assigned a number. For example, the $ cell has number 36. The numbers index the symbols tables in Appendix B of the full specification. This indexing is very useful for studying how the codes are used to represent mathematical symbols.