Designing Composite Indexes
When it comes to creating composite indexes there are two questions I get asked most often by the ISVs I work with as well as their customers.
1. What is the optimal number of columns to include in a composite index?
2. What should the order of those columns be?
While in most cases the answer is “it depends’, there are a handful of considerations which help in defining optimal composite indexes. This BLOG attempts to offer some guidance on these and also elaborate on some of the tradeoffs.
To start with let’s make sure we’re all on the same page with the definition of a composite index: “A composite index is one which is created across two or more key columns”. Composite indexes are often also referred to as ‘multi-column’ index. For example, an index (idx1) created on table (TabA) columns (col1, col2, col3 (CREATE CLUSTERED INDEX idx1 ON TabA (col1, col2, col3);). Index columns refer only to key columns of the index; although INCLUDED columns are part of the physical index structure, they are not part of the index key and therefore not considered to be a part of a composite index for the purpose of this discussion.
Now let’s drill into at the answers to the two questions individually.
1. Optimal number of columns to include in a composite index
As mentioned earlier, there is no one answer for this question, every query and table situation is different and needs to be evaluated on a case by case basis. That being said there are a few rules of thumb that can be used to effectively determine which columns to include in the composite index.
a. Only include columns that are selective. Columns that have just a few, or in an extreme case just 1, values across the entire table add little or no value in index search operations and should not be included in an index even if they are used as query predicates.
b. Volatile columns (columns that are frequently updated) should not be indexed. When the value of the column that’s part of an index is modified, it usually results in the index needing to be reorganized as well. This results in the database engine having to perform multiple writes and thereby having additional overhead. For example if a volatile column (col1) is included in a non-clustered index, every time any data in col1 changes, the database engine has to perform two writes, one to update the col1 data itself and the other to update the non-clustered index that includes col1. If the table has more than one non-clustered index that includes col1, then for every change equal to the number of such non-clustered indexes need to be performed.
c. Columns included in query predicates. Columns that are commonly used as query predicates in multiple frequently executed queries should be included in the composite index as long as they qualify the checks mentioned in 1.a and 1.b above.
d. Limit the number of columns. While SQL Server limits the maximum number of columns in an index key to 16, in my opinion that limit is of little significance as in most cases you should be able to create an optimal indexes with far fewer columns. As a rule you should use the fewest number of columns in a composite index as required to give you optimal performance. For example, if the combination of two columns (col1 and col2) results in uniquely qualifying every row of the table, there is little value in adding additional columns to the composite index to make the index seek operations more efficient. In most cases I have seen well designed applications to have composite indexes built across no more than 6 columns. Every column in a composite index has disk space, performance overhead related to disk I/O and index maintenance overhead associated with it. To yield a net positive gain from having the index you should make sure that the benefit of having a column in a composite index outweighs the overheads. Therefore the fewer the columns in a composite index the lower the overhead and higher the probability of a net gain. This is particularly applicable to clustered indexes because the length of the index key length will affect all the non-clustered indexes.
e. Use INCLUDED columns. Scenarios where a column is added to a composite index for the sole purpose of creating a ‘covering index’ (an index where the SELECT clause is fully serviced by the index itself and the underlying table doesn’t need to get referenced) can be made to use INCLUDED columns instead. The INCLUDED columns provide the same benefits as far as covering indexes go, but do not have the index maintenance overhead associated with the actual composite index columns. You can get additional information on INCLUDED columns as well as read some of the other advantages they offer by referring to: https://msdn.microsoft.com/en-us/library/ms190806.aspx.
f. Index key record size limited to 900 bytes. In SQL Server 2008 the sum of the lengths of all columns in an index key cannot exceed 900 bytes (this limit does not apply to XML indexes or spatial indexes). When using composite indexes you need to make sure that you do not exceed this limit. For covering index case where you need to have indexes whose total length is greater than 900 bytes, you can consider the use of INCLUDED columns as explained above. For cases where the limit is exceeded due to the number and sizes of the columns, you have no choice but to either eliminate some of the previously selected columns, or change the data types of some of the columns if possible.
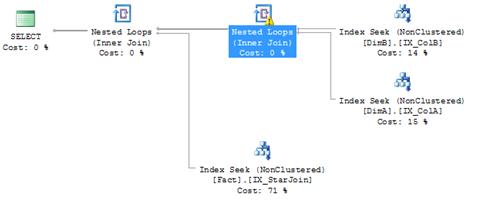
g. Star join optimization. There are some queries, especially in data warehouse workloads, where creating a composite index on two dimension columns in the fact table increases performance by the use of the ‘safe crossjoin’ star join optimization. In such cases, the database engine is able to crossjoin and apply combined selectivity of the two dimensions before digging into the fact table, potentially yielding a significant reduction in I/O. For example, in the following query:
SELECT Fact.* FROM Fact
JOIN DimA ON Fact.SK_A = DimA.SK_A
JOIN DimB ON Fact.SK_B = DimB.SK_B
WHERE DimA.Col IN (42, 13, 7)
AND DimB.Col IN (13, 42, 7);
a composite index on columns SK_A, SK_B (CREATE INDEX IX_StarJoin ON Fact (SK_A, SK_B)) enables the use of the ‘safe crossjoin’ star join optimization as can be seen in the corresponding query plan below.
2. Order of columns in a composite index
Once we’ve determined which indexes to include in a composite index, the next challenge is to determine the optimal order for these columns. As with the previous question, there is no clear-cut answer here either, but the points below should help provide guidance around the key factors to consider.
a. Ensure that the leading columns are selective. This has a two-fold benefit: (1) the effectiveness of index seek operation is increased; and (2) since the intra-query parallelism with which an index create or rebuild operation is executed is limited to the selectivity of the first column, having a selective leading column ensures that the database engine can execute the operation with the highest degree of parallelism possible on the server at the given time. For example, if the first column of an index only has one data value (example: all values are ‘Region001’), the index rebuild operation can at most be executed with a parallelism of 1, i.e. it is executed with a serial query plan. I have seen real-world customer deployments where the design of the database has been such that the leading columns of certain large tables have had low (all values the same) selectivity and because of this their index rebuild operations were executed with a serial query plan. This resulted in the task taking a really long time to complete even though they had a relatively lightly loaded 32-core server and had all the other database server configurations (‘max degree of parallelism’, ‘cost threshold for parallelism’) set correctly.
One possible exception to this point may arise with regards to index fragmentation. When selecting the leading column of an index (clustered index especially) you should take into consideration potential for fragmentation, and any column for which you are inserting data values all over key range should preferably not be placed as the leading column, especially if there's a high insert or update activity on the table.
b. Specify columns used in inequality predicate towards the end of the list. When creating composite indexes for queries that use a mix of equality and inequality (>, <, !=, BETWEEN) predicates, the columns corresponding to the selective equality predicates should specified first in the composite index, followed by the inequality predicates. This is because the depth with which an index seek operation is performed is limited to the occurrence of the first inequality predicate. For example, if the following query was to execute and use the idx1 index defined above, the index seek operation would only be able to seek on the first column (col1) of the index even though there are valid equality predicates for col3.
SELECT col1 FROM TabA
WHERE col1 > 28
AND col2 = 99
AND col3 = 0;
GO
The query execution plan text (viewed using SET SHOWPLAN_TEXT ON) for this query would look like:
|--Clustered Index Seek(OBJECT:([tempdb].[dbo].[TabA].[idx1]), SEEK:([tempdb].[dbo].[TabA].[col1] > CONVERT_IMPLICIT(int,[@1],0)), WHERE:([tempdb].[dbo].[TabA].[col2]=CONVERT_IMPLICIT(int,[@2],0) AND [tempdb].[dbo].[TabA].[col3]=CONVERT_IMPLICIT(int,[@3],0)) ORDERED FORWARD)
In this case you can notice that the index is not optimally used due to the SEEK operation only being executed on col1 while the predicate values of col2 and col3 are filtered out using a WHERE clause (SCAN operation).
If the index idx1 was primarily created to help the performance of this query it may help to reorganize the index columns such that the one (col1) which is used in the inequality predicate is specified towards the end (right-most column) in the composite index, i.e. the order should be: col2, col3, col1. This would permit the database engine to optimally SEEK into columns col2, col3 and col1 as can be seen in the query execution plan text below.
|--Clustered Index Seek(OBJECT:([tempdb].[dbo].[TabA].[idx1]), SEEK:([tempdb].[dbo].[TabA].[col2]=CONVERT_IMPLICIT(int,[@2],0) AND [tempdb].[dbo].[TabA].[col3]=CONVERT_IMPLICIT(int,[@3],0) AND [tempdb].[dbo].[TabA].[col1] > CONVERT_IMPLICIT(int,[@1],0)) ORDERED FORWARD)
After making this index change you will notice that there is no WHERE clause in the query plan text and the number of logical read operations (observed via SET STATISTICS IO ON) decrease.
NOTE: You cannot view these internal index operations using the graphical showplan available in SQL Server Management Studio.
If a query has more than 1 inequality predicate it is best to specify the most selective inequality predicate immediately following any equality predicates.
c. Specify appropriate ascending or descending column order. The columns in an index can be specified to be ascending (ASC) or descending (DESC). For composite index, qualifying the column order to match the ORDER BY clause in a query optimizes the use of the index. For example, for the query below it would help to specify the order of the index columns as col1 ASC, col2 DESC, col3 ASC.
SELECT col1, col2, col3 FROM TabA
ORDER BY col1 ASC, col2 DESC, col3 ASC;
NOTE: SQL Server is able to perform index seeks and scans in either direction; this means that you do not need to create 2 indexes if one query orders the result set using “ORDER BY col1 ASC” and the other uses “ORDER BY col1 DESC”.
Once you’ve created the composite index, you can use the SQL Server built-in stored procedure sp_spaceused to view the total size of all the indexes present on a table. For example: sp_spaceused [dbo.TbA] displays:
name rows reserved data index unused
TabA 869088 187288 KB 158032 KB 29192 KB 64 KB
In this output we can see that the total space used by all the indexes in TabA is 29.19 MB.
If you’re interested in drilling in further, you can use the following query to view details about each index level of every index for the table (TabA).
SELECT OBJECT_NAME(OBJECT_ID), *
FROM sys.dm_db_index_physical_stats (DB_ID(),NULL, NULL , NULL, 'SAMPLED')
WHERE OBJECT_ID=OBJECT_ID('TabA')
Please refer to SQL Server Books OnLine for details about each of the columns displayed (https://msdn.microsoft.com/en-us/library/ms188917.aspx).
The points mentioned above apply equally to clustered as well as non-clustered composite indexes, unless explicitly stated, and therefore no distinction has been drawn between them.
NOTE: It is a SQL Server best practice to have a clustered index on all tables, please refer to the SQL Server Best Practices Article: ‘Comparing Tables Organized with Clustered Indexes versus Heaps’ ( https://sqlcat.com/whitepapers/archive/2007/12/16/comparing-tables-organized-with-clustered-indexes-versus-heaps.aspx ) for additional information on this topic.