Identifying Medical Personas in Social Media through DL
Pharmaceutical companies use social media platforms for two specific reasons - drug marketing or pharmacovigilance (monitoring the effects of drugs on patients). Both these endeavors require accurate identification. Drug companies need to be able to differentiate medical professionals from regular users for commercial and regulatory reasons.
Similarly, drug companies need to ascertain whether a social media user is a genuine patient talking about the effects and experience of using one of their drugs. Pharmaceutical companies can use this information to market to the right audience and reach out to industry thought leaders. The feedback and experiences of genuine patients can be used to modify the formulations, deal with the side effects and provide assistance.

Granular data on medical professionals and patients can help drug companies collaborate for better medical research, identify patients willing to undergo drug trials, and inform journalists of the latest breakthroughs in the field.
Gathering information on this level requires a high degree of accuracy and sophistication. Social media is brimming with personal information, but not all users openly declare their professions, medical credentials, or medical problems. This makes accurate identification difficult. Also, each persona has several users and may itself contain heterogeneity. This is where deep learning (DL) can help.
Mining social media with DL
Microsoft researchers teamed up with the research teams at IIIT-Hyderabad and IIIT-Delhi to see if a neural network could dig under the surface and reveal hidden information from social media. Their study applied a highly engineered and sophisticated neural network to identify one specific group of people purely from their social media posts – user groups in healthcare.
Researchers Nikhil Pattisapu (PhD candidate, Information Retrieval and Extraction Lab, IIIT-Hyderabad), Manish Gupta (Principal Applied Researcher at Microsoft, and Adjunct Faculty at IIIT-Hyderabad), Ponnurangam Kumaraguru (Associate Professor, IIIT-Delhi) and Vasudeva Varma (Dean R&D, IIIT-Hyderabad and Head of the Information Retrieval and Extraction Lab, IIIT-Hyderabad), worked together on a simple premise - identifying medical personas based solely on their posts and interactions. Their paper titled, “Medical Persona Classification in Social Media,” details how a neural network based architecture can sift through an ordinary post on social media and identify the user’s persona.
This problem is modelled as a ‘supervised multi-label text classification’ task. In other words, the researchers have tried to use an algorithm to crawl through a text-based post, eliminate the noise, identify useful words, and use those words to see if they offer clues on the user’s persona. The study focused exclusively on classifying users into one of seven categories:
{Patient, Caretaker, Consultant, Journalist, Pharmacist, Researcher, Other}
The algorithm for the study was tasked with two objectives - identify the author of each post and identify the intent. The top features guiding the algorithm included parts-of-speech tags, document statistics, HTML tags, common words and phrases, acronyms, and industry jargon.
The dataset was created using a set of 50 queries overall. For each query, a set of 50 blog posts and 30 tweets were obtained. Irrelevant tweets and noisy posts that lacked crucial information were eliminated in the initial stages. The algorithm was then deployed on the dataset to try and classify all the posts with the results regressed against an evaluation set generated by human annotators who worked on the same task.
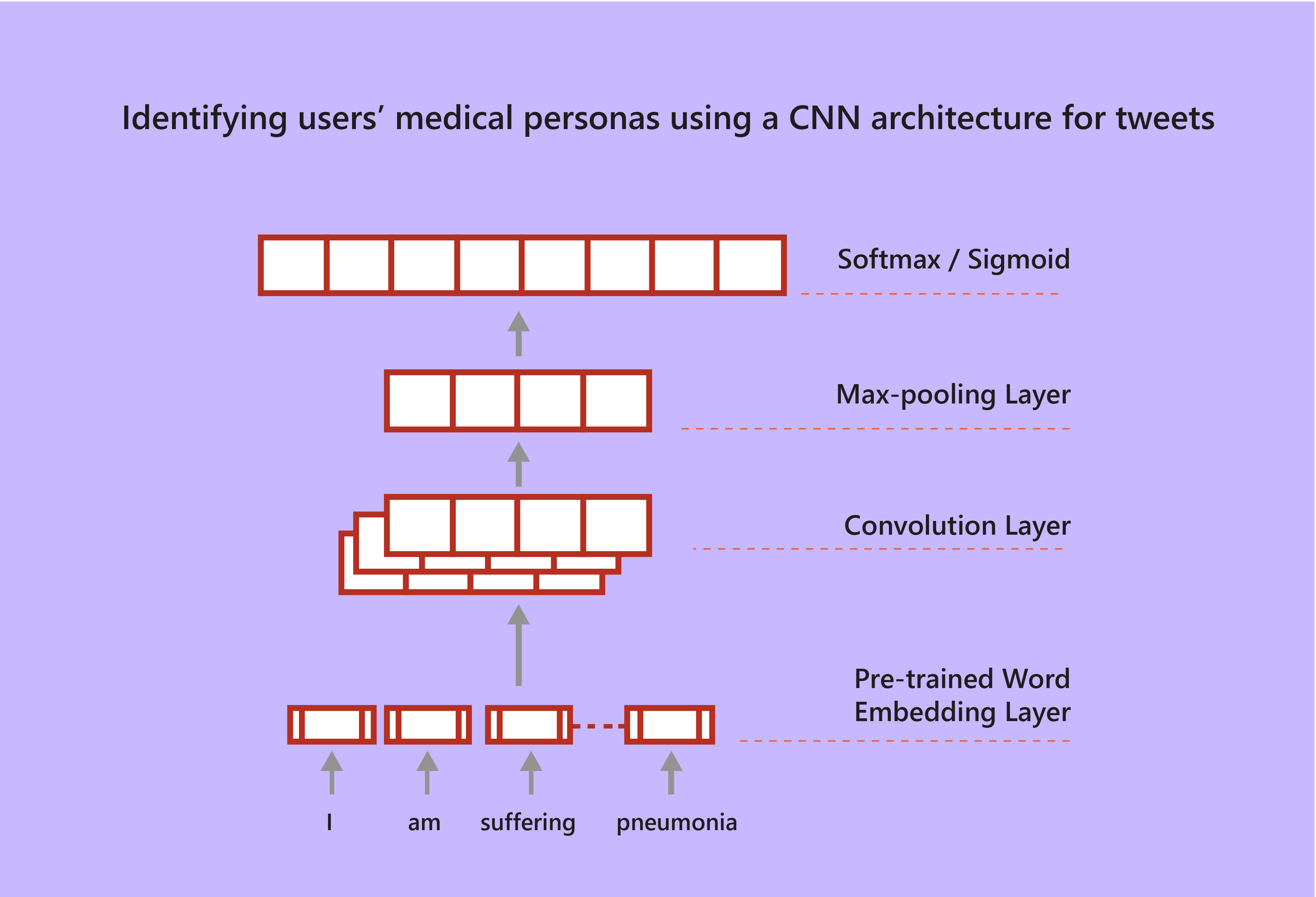
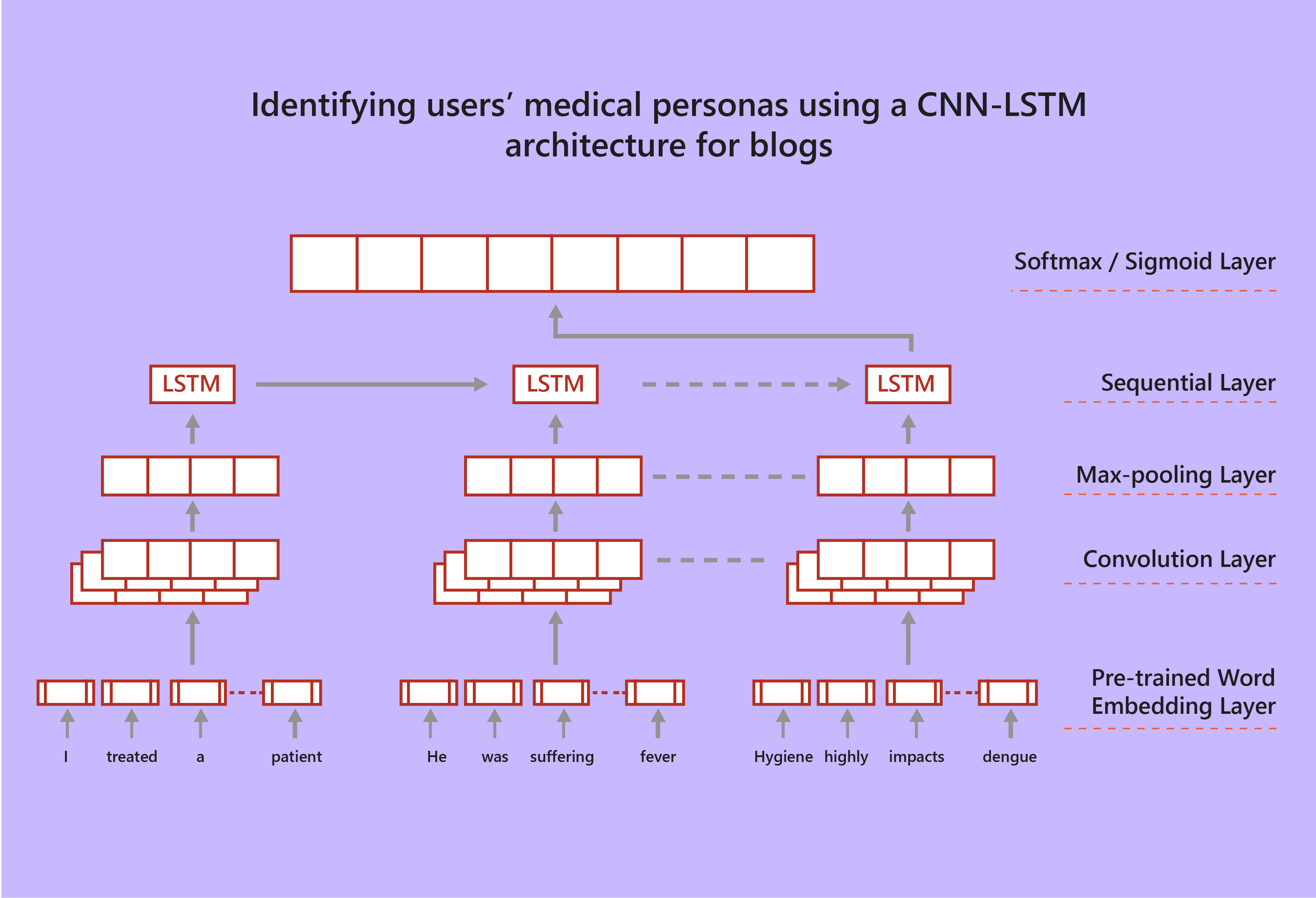
The objective of the study was to find out if this neural network-based architecture was better than traditional methods of data classification.
The results
Based on F-measures, the neural network used for the study showed a 5% improvement for Tweets and a 7% improvement for blogs classification over traditional manual-feature engineered solutions. In other words, the neural network-based approach is statistically better than the traditional approach for this specific task.
Furthermore, the study’s DL architecture was able to deduce surprising characteristics of different personas and their social interactions. For instance, it discovered that researchers were more likely to mention percentages in their blogs, consultants were more likely to talk about consultation fees, consultants were 1.6 times more likely to use adjectives, and pharmacists had longer blog posts than patients.
A testament to the power of DL
Vital results obtained through deep learning could help medical professionals and pharmaceutical companies develop better strategies for marketing and pharmacovigilance on social media platforms. The data could be used to improve medicines, identify appropriate medical test subjects, provide caregivers with relevant information, and reach out to a relevant audience.
At Microsoft, we envision a world where granular identification and classification allows innovative companies to offer customer-centric services and personalized solutions to everyday needs. As the technology improves, the applications could be boundless.