從車聯網範例學習使用 Azure 雲平台實現物聯網(IoT)精神:(2) 資料轉換及建立預測模型
前言
Azure 雲平台提供了許多開發軟體、系統或服務的平台元件,而在最近熱門的資料分析、物聯網(IoT, Internet of Things)、機器學習等議題方面,Azure 也有許多針對這領域的需求提供相關的服務,這裡我們就以一個「車聯網」(Connected Car)的情境來說明如何運用 Azure 上的這些服務來建構一個資料分析或是物聯網的解決方案。
從這裡可以下載或啟用本文所使用的範例。
系列文章
這個範例將會分成三個部份來做介紹,分別是:
- 接收並儲存大量遙測資料
- 資料轉換及建立預測模型
- 建立資料視覺化圖表
這篇文章是第二個部份,範例情境請參考第一部份說明。
轉換資料格式
原始資料的樣貌
在第一部份中,我們已經接收資料,並且有一部份是儲存在 Azure Blob Storage 中,我們可以運用 Microsoft Azure Storage Explorer 這類工具來看一下資料是如何被存起來的,如果你打開這個範例所建立的 Steam Analytics 服務內的設定,你可以發現它將資料儲存在 connectedcar 容器中,而前置詞為 rawcareventstream(如此一來,在 Azure Blob Storage 中就會像是資料夾形式組織檔案),所以我們可以在此找到一個 CSV 檔案,就是不斷接收進來的資料:
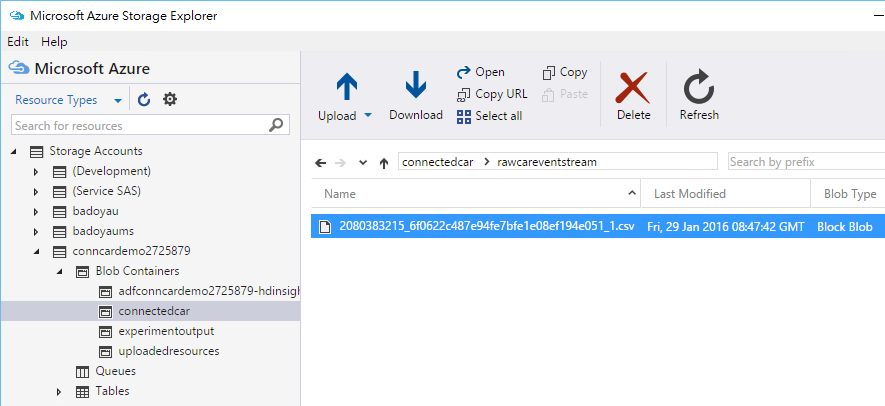
圖: Stream Analytics 將進入 Event Hub 的資料儲存在 Blob Storage 中。
所以我們可以看到資料都是以 CSV 的格式做儲存,下圖是以 Excel 開啟該 CSV 檔案後的結果。
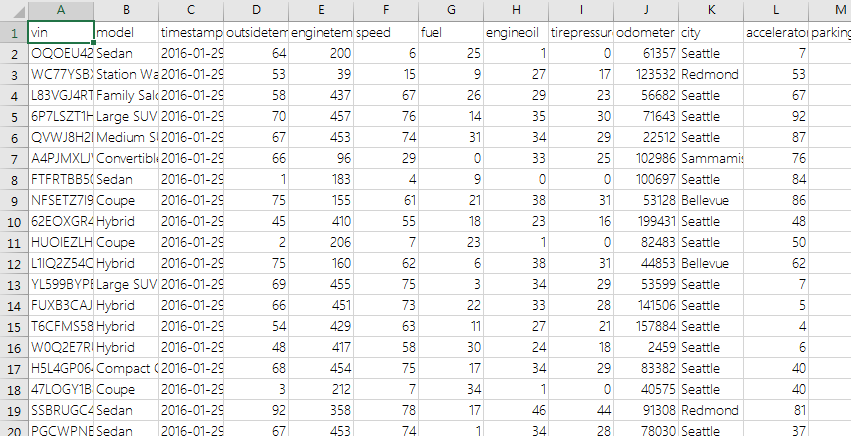
雖然資料內容儲存下來了,但是這樣的資料格式不一定適用於每一種查詢分析、或是與別的資料關聯等等的操作,所以我們同時也需要能夠針對大數據來做資料轉換的工具,這時便能考慮使用 Azure HDInsight (Hadoop) 或是 Azure Data Factory 的服務。在這個範例中,主要是以 Azure Data Factory 為主,而其中也用到了 Azure HDInsight 的服務來進行運算。
資料轉換
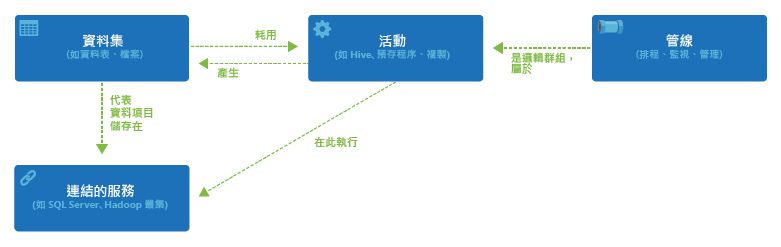
上圖是 Azure Data Factory 的運作模式,在 Data Factory 裡面我們定義四種資源:
- 資料集 (data set) : 原始資料或是轉換過的資料模型,它可能是資料庫或是檔案等,上述的 CSV 原始資料就是一個資料集。
- 活動 (activity) : 這裡定義了轉換資料的所有操作,包括簡單的檔案複製,或是透過 Azure HDInsight (Hadoop) 做 Hive 查詢等等,Azure Data Factory 就是靠這裡定義的操作依據需求來轉換資料。
- 連結的服務 (linked service) : 因為 Azure Data Factory 本身不做資料的儲存或是計算的工作,這些都要仰賴外部的服務來完成,所以為了讓定義的活動能夠順利執行,以及資料能從正確的位置讀取,這裡就要定義會使用到的服務。以此例來說,至少就要連結 Azure Blob Storage 以便資料集能抓取資料,以及 Azure HDInsight 來執行活動中定義的 Hive 查詢等。
- 管線 (pipeline) : 在 Azure Data Factory 中您可以將管線視為一個完整的任務,而這個任務中可能就會包含一連串的「活動」,所以也可以在邏輯上看作是一個群組,當我們在 Azure Data Factory 上進行排程、監控等操作時,都是以管線為單位來做管理。
關於 Azure Data Factory 的觀念介紹可以參考這份文件。
大致瞭解 Azure Data Factory 的用途之後,就能看懂這個範例是如何使用它的,首先是連結的服務,我們看到的設定有:
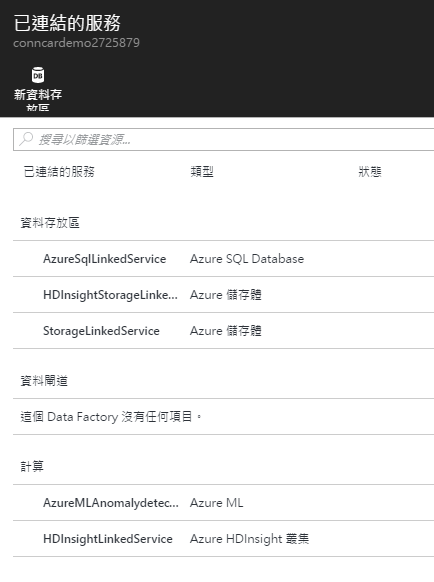
我們看到它定義了資料以及計算相關的服務,資料的部份有從 Stream Analytics 送進的資料,也有提供給 HDInsight 操作的資料區域,還有一個 SQL 資料庫;而計算方面則是用了 Azure HDInsight 以及 Azure Machine Learning 的服務。
而資料集的部份,定義了之後要做資料視覺化以及供 Machine Learning 建立預測模型的資料表結構:
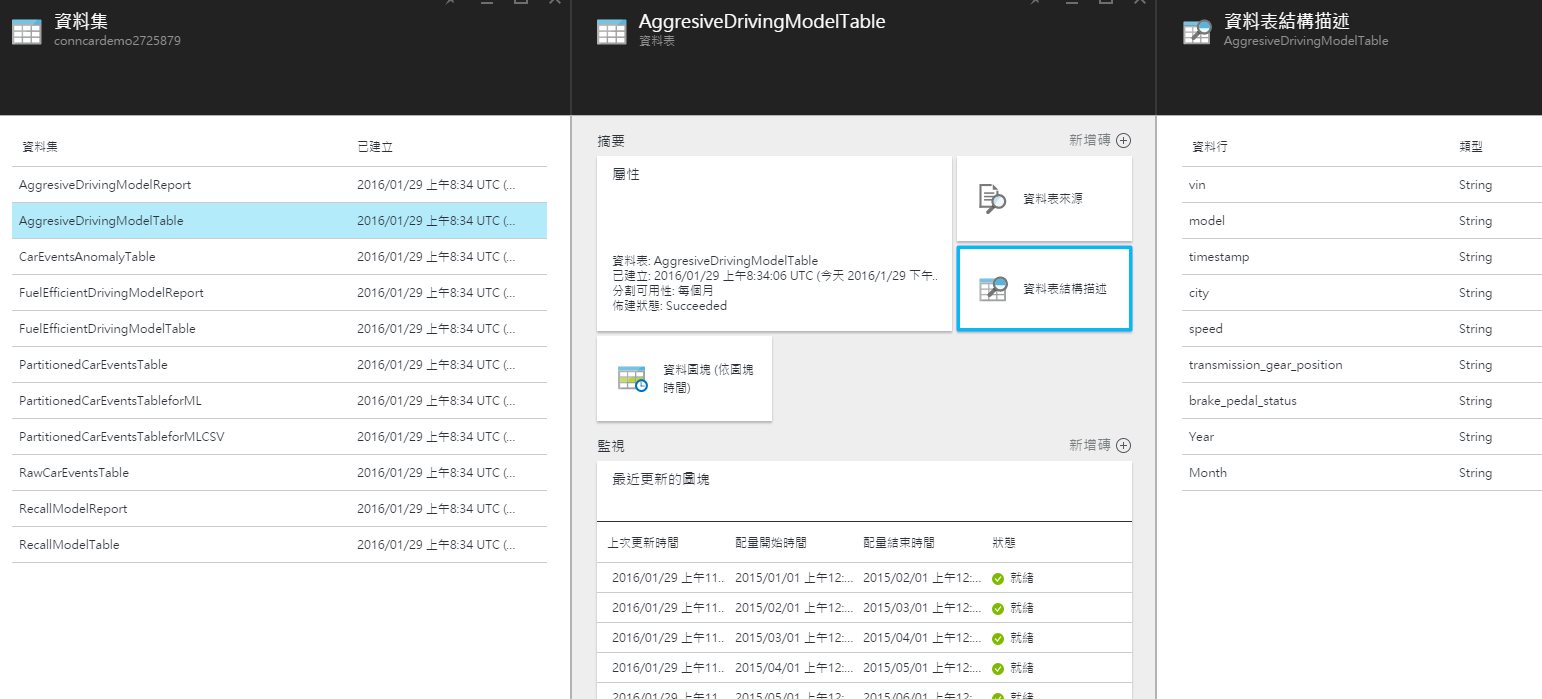
以及要讓 Data Factory 執行資料轉換的管線:
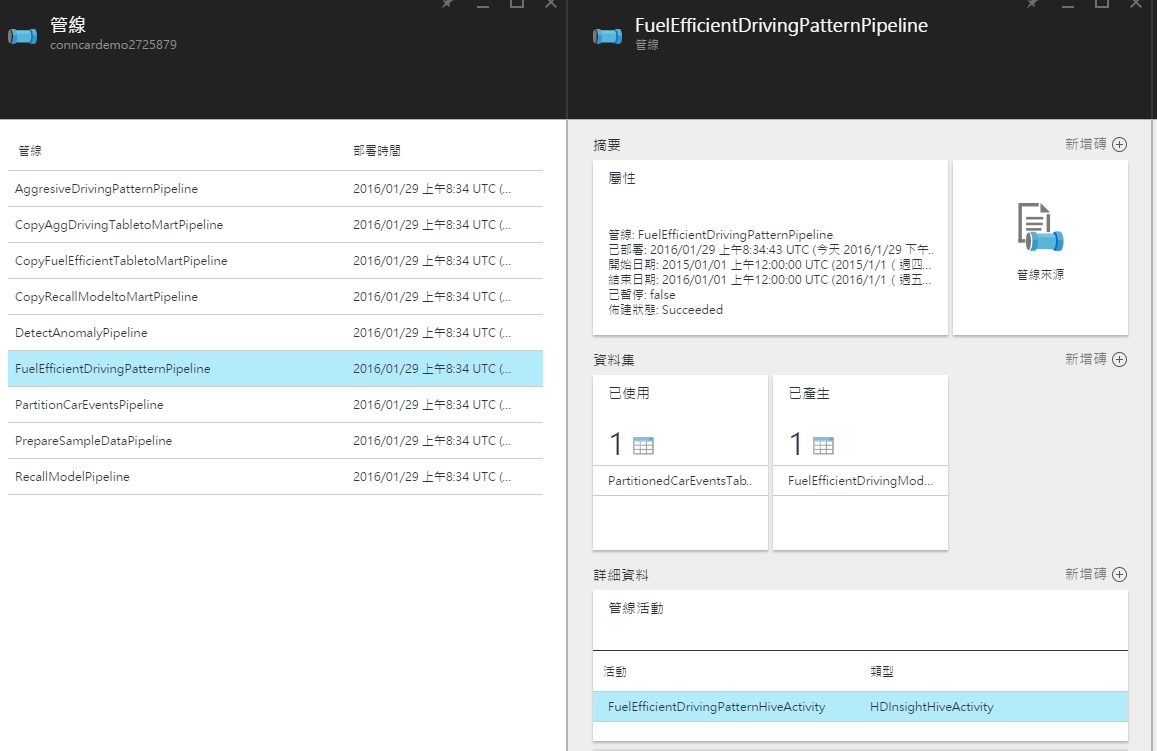
還有管線中包括的活動,像下圖的例子就是一個 HIVE 查詢的活動,而這個活動就會送到連結的 Azure HDInsight 來進行運算
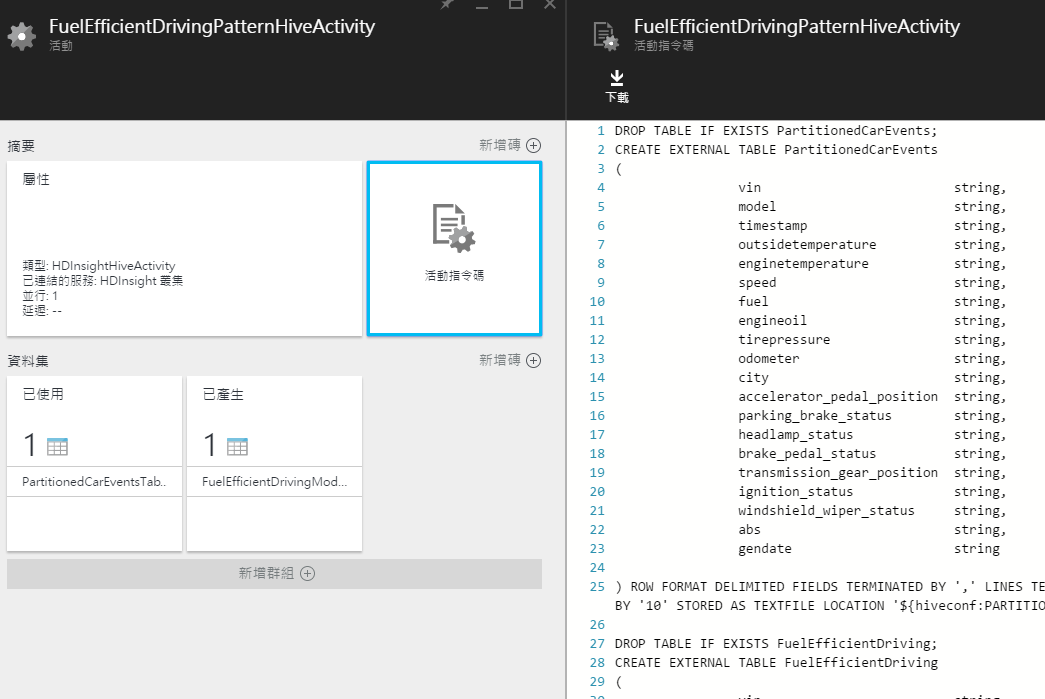
定義好了之後,你也可以把這些管線像是這樣串接起來:
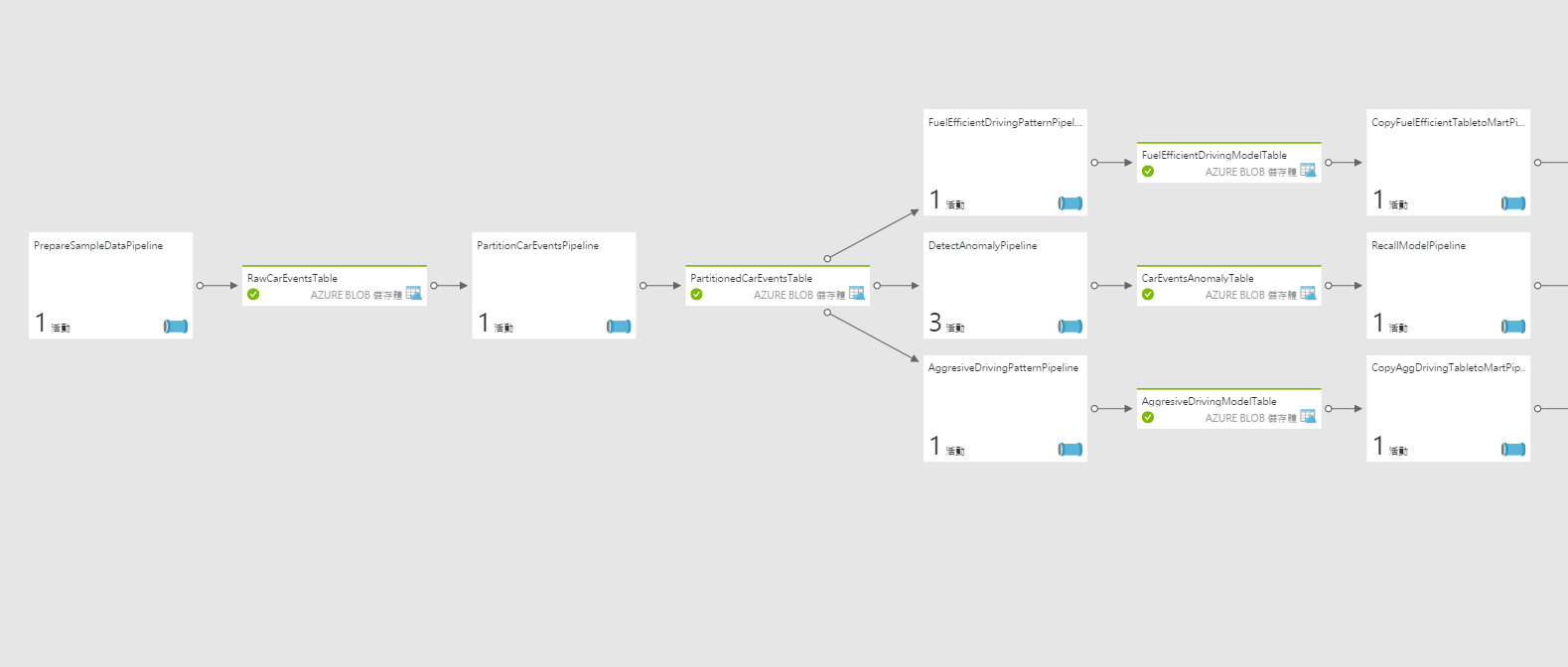
這樣當然資料進入資料集時,整個管線就會把資料按照定義轉換完成。
關於 Azure Data Factory 的相關參考資料:
- Azure Data Factory 的產品頁面(含定價、參考文件的入口)。
- Azure Data Factory 學習地圖
建立預測模型
在這個範例中,希望能先運用機器學習的技術,建立兩個預測模型:需要維護的異常預測、需要召回的異常預測,一旦有這兩個預測模型,接下來透過這些車輛回傳的資料,很快就能預測出哪些車輛需要維修或是召回。所以這個範例先用 Azure 機器學習(Azure Machine Learning, AzureML) 服務建立了一個實驗,事先準備好一些車輛維修與召回的相關資料,在 Azure 機器學習服務中選好學習演算法,就可以讓這個服務啟動計算,完成模型的訓練。
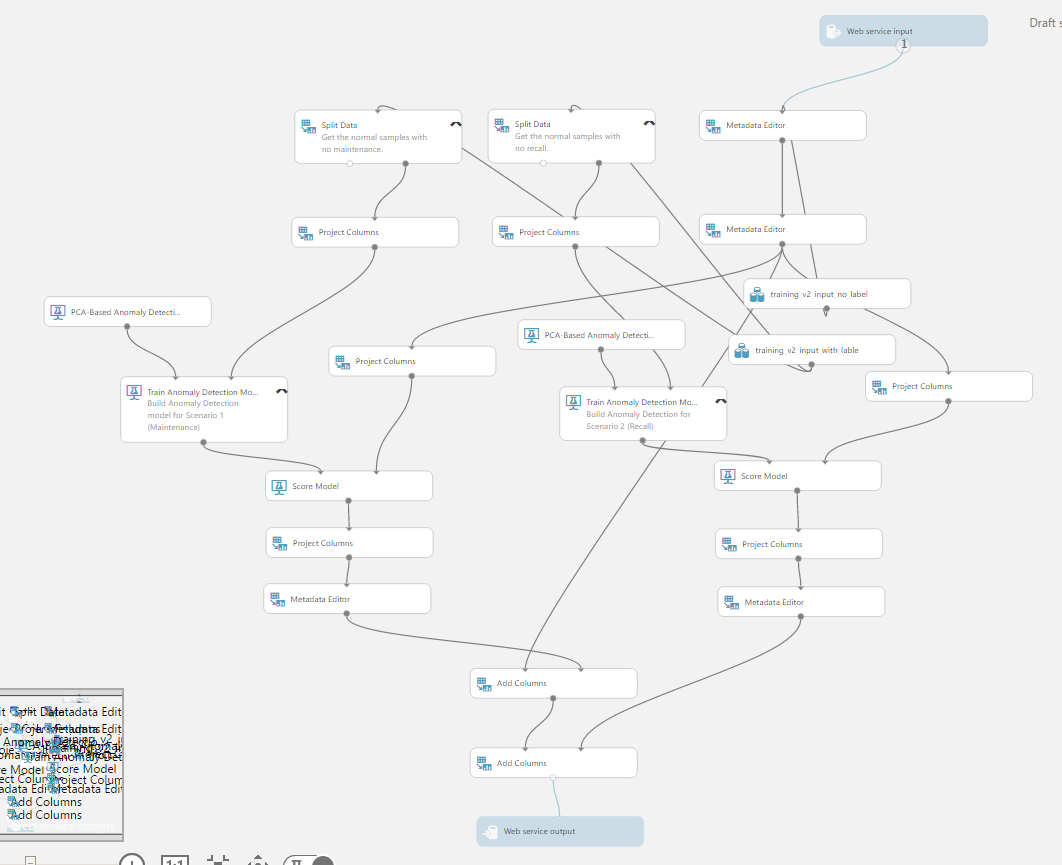
訓練好的兩個模型(model),可以把它儲存起來,然後再建立另外一個實驗,把這兩個預測模型做成 Web Service 供其它服務串接。在這個例子中,就是把車輛相關的資料輸入(前面提到的資料轉換就有將資料準備好給 Azure ML 來使用的資料格式),接著就會預測這些車輛是否需要維修或是召回。
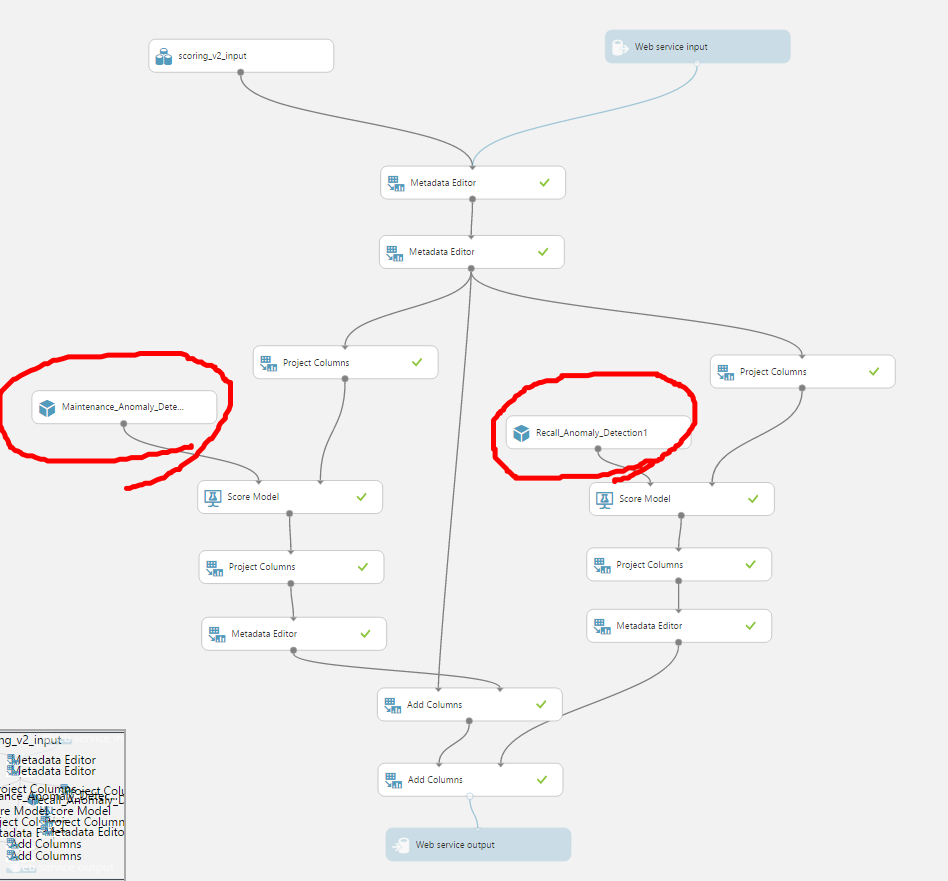
從這個例子可以看得出來,只要有資料、有想要解決的問題、選對演算法就可以做完機器學習的工作,而且這個服務平台也是能支援大數據的運算,學習演算法也是由微軟研究院多年的研究而成,可以減少很多實作演算法或是處理大數據的時間。
我們學會了什麼?
在這部份的文章中,我們瞭解如何將原始資料透過 Azure Data Factory 結構化、自動化的方式進行資料轉換或是合併處理,整理後的資料就更方便用在報表、資料視覺化、或是套用機器學習等智慧操作,而 Azure 機器學習服務也提供了一個非常容易上手的平台,將你的資料轉化為具有智慧的預測模型。
下一部份,我們將介紹這些轉換過的資料如何以視覺化的圖表呈現,提供商業決策的分析參考。
原始文章發佈於「開發者之魂」部落格