How to recover SharePoint document once deleted from recycle bin
In the scenario whereby a document has been deleted from both levels of the SharePoint recycle bin, you may have a request to recover it. Assuming you have a SQL database backup of the content database which hosted the document, you can get it back with minimal effort by following the steps below.
Important: Do not run these steps on the production SQL Server deployment. The idea is that this is done on a development or testing SQL Server environment where the content database which holds the document you wish to extract is restored to. This is because these steps are not officially supported by Microsoft.
Step 1: Get TextCopy utility and make sure it works
The textcopy utility comes with the SQL Server 2000 resource kit and is designed to run on SQL Server 2000. However it can be used on SQL Server 2005. Get textcopy.exe from the resource kit and place it in a folder on the SQL Server 2005 machine e.g. C:\Temp. Also add into this folder a file from a SQL Server 2000 installation called ntwdblib.dll. Both of these files need to be in the same folder to work.
Run textcopy.exe to ensure it works, you should see a list of textcopy commands.
Step 2: Determine the content database to use for extracting the document
In order to extract the document you need to know where the document was located in the site structure. For example, below we see a document titled “CoreIOModels”, which is hosted in the sub site “Docs” in the root site collection of https://moss.litwareinc.com web application. The document is in the documents document library.
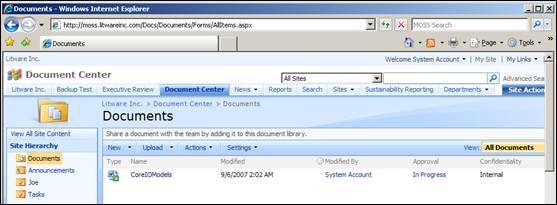
You now need to determine which content database holds the document. This is done easily through Site Collection List option in the central administration application. Here you can see that the root site collection for https://moss.litwareinc.com is found in the content database WSS_Content_MOSS. You need the name of the content database because SQL scripts (and textcopy) will run against this database. Also, you now know which database to restore to a test / development environment instead of restoring all you SQL databases.
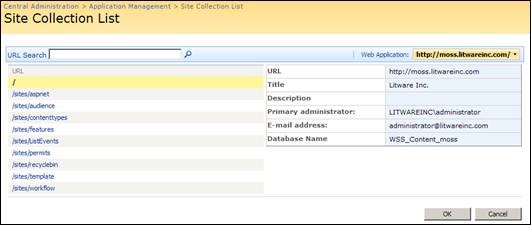
Step 3: Determine the record which holds the binary image of the document to extract
Run the following script on the database, using SQL Query Analyser in SQL Server 2005. This script will return all the records which hold document that you are looking. You may get more than one record returned, as their might be several previous versions of the document.
USE [@database]
SELECT AllDocStreams.Id, AllDocStreams.[Content], AllDocStreams.Size, AllDocs.Version, AllDocs.TimeLastModified, AllDocs.CheckoutUserId,
AllDocs.CheckoutDate, AllDocs.IsCurrentVersion, AllDocs.DirName, AllDocs.LeafName, AllDocs.[Level]
FROM AllDocs INNER JOIN
AllDocStreams ON AllDocStreams.Id = AllDocs.Id AND AllDocs.[Level] = AllDocStreams.[Level]
WHERE (AllDocs.DirName = @dirname) AND (AllDocs.LeafName = @leafname)
Variables
@leafname = filename
@dirname = directory name of file
For example in my scenario above this would be
USE WSS_Content_MOSS
SELECT AllDocStreams.Id, AllDocStreams.[Content], AllDocStreams.Size, AllDocs.Version, AllDocs.TimeLastModified, AllDocs.CheckoutUserId,
AllDocs.CheckoutDate, AllDocs.IsCurrentVersion, AllDocs.DirName, AllDocs.LeafName, AllDocs.[Level]
FROM AllDocs INNER JOIN
AllDocStreams ON AllDocStreams.Id = AllDocs.Id AND AllDocs.[Level] = AllDocStreams.[Level]
WHERE (AllDocs.DirName = 'docs/documents') AND (AllDocs.LeafName = 'coreiomodels.doc')
This returns the following records in my case:
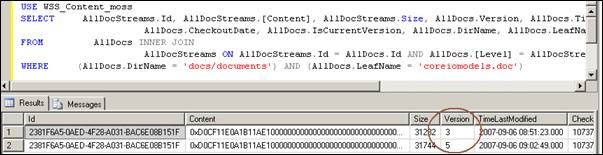
If you get multiple records returned, you will want to use the Version field and the isCurrentVersion and perhaps the TimeLastModified fields to determine which record in the one you want to extract.
Take note of the ID of the record any other unique field data from the AllDocStreams table so that you can uniquely identify the record in the AllDocStreams table.
Step 4: Extract the document using Textcopy
From the command prompt run the textcopy.exe command to extract the document (from the content field) in the AllDocStreams table.
Example TextCopy cmd to extract file:
textcopy /s @server /u @user /P @password /d “@database" /t docs /c content /F c:\temp\filename /O /Z /W "where ID= ‘@IdofRecord’ and Level=’@levelofrecord’”
Variables
@database = content database
@server = name of SQL Server machine to use
@leafname = filename
@dirname = directory name of file
@IdofRecord = Id of the content record to extract
@levelofrecord = level of content record to extract
For example, in my scenario this would be:
textcopy.exe /S MOSS /D wss_content_moss /T alldocstreams /C content /U sa /P pass@word1 /F c:\temp\coreidmodels.doc /O /Z /W "where ID='2381F6A5-0AED-4F28-A031-BAC6E08B151F' and Level='255'"
This will dump the file into the C:\Temp folder and allow me to email or place the file onto the site for the user who needs it.