Getting started with GPU acceleration for MicrosoftML's rxNeuralNet
MicrosoftML's rxNeuralNet model supports GPU acceleration. To enable GPU acceleration, you need to do a few things:
Install and configure CUDA on your Windows machine.
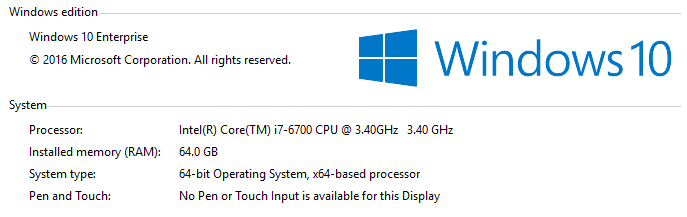
For the purpose of this setup and later performance comparison, this is the machine used in this blog.
There is an excellent old blog on how to do this. However, it's slightly out of date for the purpose of our setup, so the steps are repeated here with updated product versions.
(If you were to get a Deep Learning toolkit for the DSVM which comes with R Server, Visual Studio 2015 and CUDA Toolit 8.0 preinstalled, then all you is the four dlls, basically step 3, 5 and 6. Update: Not needed any more for Deep Learning toolkit for the DSVM. )
- Check to make sure your graphic card is CUDA-enabled. To find what graphic card you are using, there are two ways. One is press Win+R, type dxdiag and look under the Display tab(s). The other is open device manager and look under display adapters. Then see if it's on the list of CUDA-enabled products.
- Install Visual Studio Community 2013.
- Install NVidia CUDA Toolkit 6.5.
- This step is optional. Use Visual Studio 2013 to build deviceQuery_vs2013.sln found in C:\ProgramData\NVIDIA Corporation\CUDA Samples\v6.5\1_Utilities\deviceQuery and bandwidthTest_vs2013.sln found in C:\ProgramData\NVIDIA Corporation\CUDA Samples\v6.5\1_Utilities\bandwidthTest, you need to set solution configuration to release and solution platform to x64. Once these two solutions are built successfully, open command line from C:\ProgramData\NVIDIA Corporation\CUDA Samples\v6.5\bin\win64\Release and run deviceQuery.exe and bandwidthTest.exe. Make sure the results are pass.
- Copy cublas64_65.dll, cudart64_65.dll and cusparse64_65.dll from C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v6.5\bin to MicrosoftML's libs directory. MicrosoftML's libs directory can be found by calling
system.file("mxLibs/x64", package = "MicrosoftML"). - Download NVidia cuDNN v2 Library (It's free but you need to register). Extract somewhere. Copy cudnn64_65.dll from the extracted files into MicrosoftML's libs directory.
Experiment: Performance analysis of rxNeuralNet in Microsoft ML with OR without GPU through a simple example
(By performance here we simply mean the training speed. )
We make a 10,000 by 10,000 matrix composed completely of random noise and another column of 10,000 random 0s and 1s. They are combined together as our training data. Then we simply build two rxNeuralNet models for binary classification. One with GPU acceleration and the other without. The parameter miniBatchSize is the number of training examples used to take a step in stochastic gradient descent. The bigger it is, the faster progress is made. But large step sizes can lead to difficulty for the algorithm to converge. We used ADADELTA here as our optimizer here as it can automatically adjust the learning rate. miniBatchSize is only used with GPU acceleration. Without GPU acceleration, it's by default set to 1.
Output fromrxNeuralNet with GPU acceleration
Output from rxNeuralNet with SSE acceleration
|
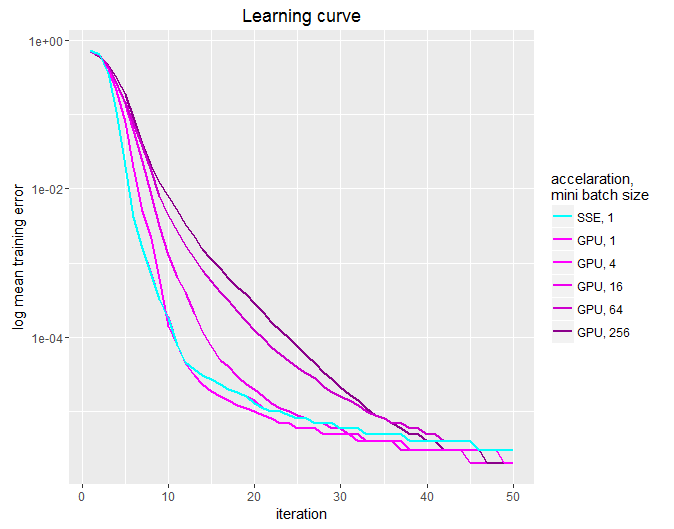
Both models achieved similar training errors by the end of 50 iterations. (In fact, the GPU accelerated model did slightly better.)
With GPU acceleration, the training time is 2'16'' compared to 19'57'' without GPU acceleration. The performance boost is almost 9X.
We can also see in Net Definition the structure of our neural nets. Here both models are using a neural net of an input layer of 10,000 nodes (the number of nodes in the input layer is always either equal to the number of input variables or plus one node for a bias term), a single hidden layer of 100 nodes and an output layer of one node for this binary classification problem.
In rxNeuralNet the number of nodes in the hidden layer defaults to 100. For a single hidden layer, it's usually recommended to be between the number of nodes in the input layer and number of nodes in the output layer. MicrosoftML also supports user-defined network architectures like convolution neural networks using the NET# language.
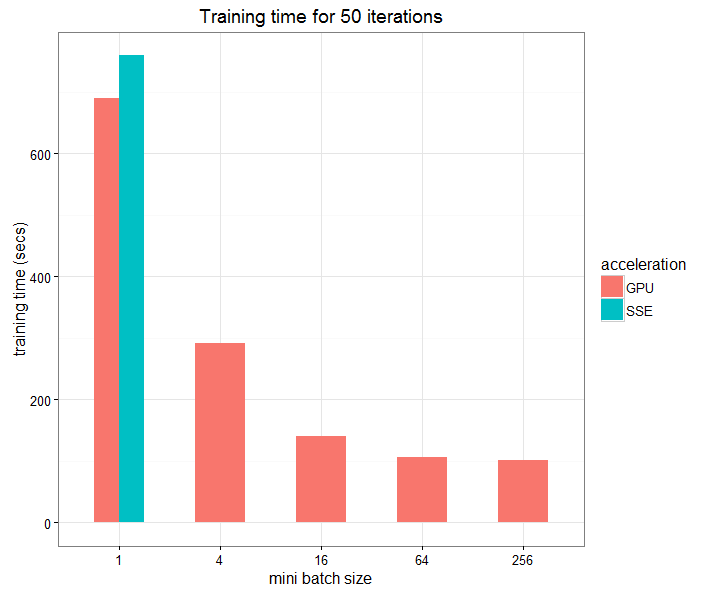
Training time vs. mini batch size
Further experiments for the same data give the following relation between training time and miniBatchSize:
Along with the learning curve for the same combinations of acceleration and miniBatchSize above.
REFERENCES
MicrosoftML manual
Install and Configure CUDA on Windows CUDA Installation Guide for Microsoft Windows