Data Wrangling in XDF files using ScaleR Functions
The RevoScaleR package provides a set of over one hundred portable, scalable, and distributable data analysis functions. In this article, we will see some examples of using ScaleR Functions to do Data Wrangling in XDF files. For all the following examples, we will be using input XDF files from the SampleData Directory in Microsoft R Server.
- Create rollup/aggregate variables in the same dataset
- Columnar operations like Min/Max of rows/columns
- Roll ups and data consolidations
- Merge more than 2 XDF Files
- Merge two datasets, renaming primary key in one dataset
- Using rowsPerBlock and blocksPerRead parameters in rxSummary
Create rollup/aggregate variables in the same dataset
In this example, we will see how to add summary information like Min,Max,Mean as columns to the original dataset using dplyrXdf. We will find out the summary information of CRSDepTime grouped by the DayOfWeek.
OUTPUT : 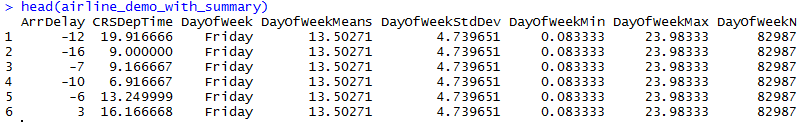
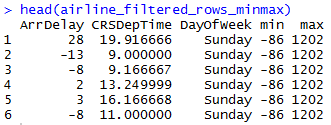
Columnar operations like Min/Max of rows/columns
We will use rxDataStep function to find out the min/max of single column, multiple columns, set of rows, filtered rows. The output min/max is appended as a column to provide an output similar to the original dataset.
OUTPUT : 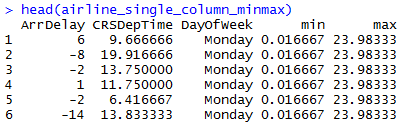
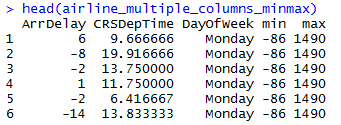
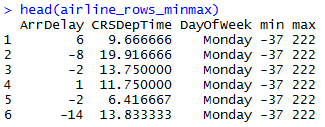
Roll ups and data consolidations
To count the number of rows in a table with group by operation on one of the columns, aggregate() function can be used. In the below example, we use the claims
data-set and group the type of claim and sum the cost for each type. aggregate() works only on data frame, so xdf needs to be converted into data frame type.
OUTPUT :
RowNum age car.age type cost number
1 1 17-20 0-3 A 289 8
2 2 17-20 4-7 A 282 8
3 3 17-20 8-9 A 133 4
4 4 17-20 10+ A 160 1
5 5 17-20 0-3 B 372 10
6 6 17-20 4-7 B 249 28
OUTPUT :
> print(res)
Group.1 x
1 A 6392
2 B 7062
3 C 6861
4 D 9015
Merge more than 2 xdf files
rxMerge() can be used to merge two or more .xdf files.
In this example, we will merge claims.xdf multiple times.
Data Source Information about claims.xdf:
File name: C:\Program Files\Microsoft SQL Server\130\R_SERVER\library\RevoScaleR\SampleData\claims.xdf
Number of observations: 128
Number of variables: 6
Number of blocks: 1
Compression type: zlib
To merge two xdf files, just supply the name of the two files to inData1 and inData2 parameters.
OUTPUT :
File merge progress at row: 128
File merge progress at row: 128
Time to merge data file: 0.016 seconds
RxXdfData Source
"claims_merged_twice.xdf"
fileSystem:
fileSystemType: native
More than two xdf files, can be merged by passing the list of the rxXdfData objects to inData1, keeping inData2 as NULL.
OUTPUT :
File merge progress at row: 128
File merge progress at row: 128
Time to merge data file: 0.017 seconds
File merge progress at row: 128
File merge progress at row: 256
File merge progress at row: 128
Time to merge data file: 0.018 seconds
RxXdfData Source
"multiple_claims_merged.xdf"
fileSystem:
fileSystemType: native
Check the number of observations using rxGetInfo():
File name: C:\Users\madraju.REDMOND\Documents\Teradata_Tests\DC_debug\multiple_claims_merged.xdf
Number of observations: 384
Number of variables: 6
Number of blocks: 3
Compression type: zlib
Merge two datasets, renaming primary key in one dataset
Here we have two xdf files with different key names, we will merge them renaming the key in one of the files.
OUTPUT : 
Using rowsPerBlock and blocksPerRead parameters in rxSummary
rowsPerBlock means the maximum number of rows per block in the byGroupOutFile which contains the summary result. blocksPerRead is the number of blocks per read from input xdf data. if your xdf data is too large you can set blocksPerRead as a small one, suppose you have many blocks in your input xdf file.
OUTPUT : 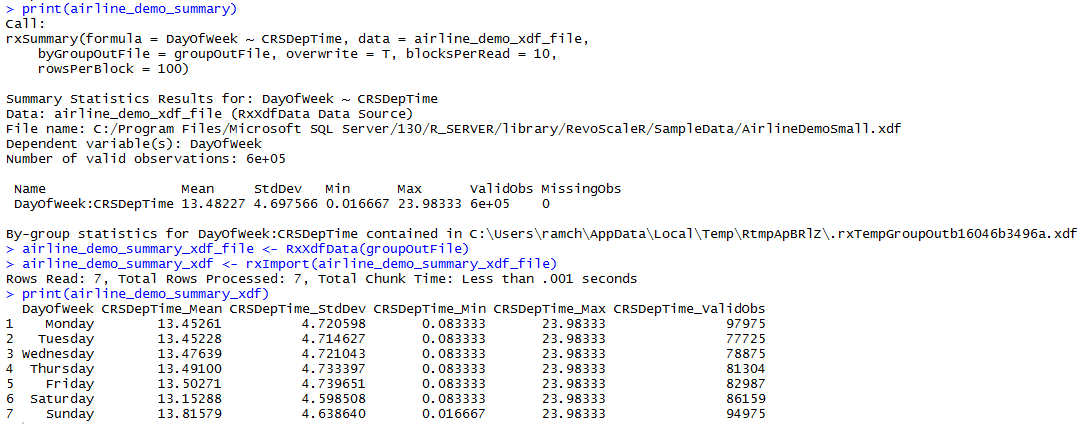
REFERENCES
RevoScaleR Functions Comparison of Base R and ScaleR Functions A simple Big Data analysis using the RevoScaleR package in Revolution R