Une introduction aux nouveaux SDKs d’Azure Machine Learning – 1ère partie
La récente conférence Microsoft Ignite 2018 qui s'est tenue à la fin du mois de septembre dernier a été riche en annonces. C'est le moins que l'on puisse dire comme en témoigne le « Book of News » de Microsoft Ignite 2018 qui reprend l'ensemble des annonces faites.


Le Service Azure Machine Learning - qui a fait l'objet de toute une série de billets sur ce blog depuis le lancement de sa version préliminaire publique en septembre 2017 à l'occasion de la précédente édition de cette même conférence Ignite - n'y fait pas exception et continue d'évoluer :-) pour toujours mieux répondre à l'attente des scientifiques des données ou data scientists. La section § 2.1.3 « New Azure Machine Learning capabilities » du livret précédent lui est dédiée.
Si, au chapitre de de ces évolutions, nous trouvons de nouvelles mises à jour importantes du service qui incluent :
- le Machine Learning automatisé afin d'identifier les algorithmes les plus efficaces et optimiser les performances du modèle,
- dans le même registre, l'optimisation intelligente des hyperparamètres,
- des modèles supplémentaires bénéficiant d'une accélération matérielle pour les FPGAs (Field-Programmable Gate Arrays) pour des scénarios de reconnaissance et de classification d'images à très haute vitesse et à faible coût,
Nous avons souhaité mettre l'accent l'espace de ce billet – comme son titre l'indique – sur les nouveaux kits de développements (SDKs) en Python qui rendent ainsi le Service Azure Machine Learning accessible à partir des environnements de développement intégrés (IDEs) et autres notebooks populaires de Python.
Une question se pose alors de prime abord : Qu'advient-il de l'application Azure Machine Learning Workbench ?
À propos d'Azure Machine Learning Workbench…
Dans la pratique, si les fonctions principales d'Azure Machine Learning allant des expérimentations au déploiement du modèle n'ont pas fondamentalement changé è à certains ajouts près, l'application Azure Machine Learning Workbench et certaines autres fonctionnalités antérieures se trouvent désormais dépréciées dans la version de septembre 2018.
Cette évolution vise à améliorer au final l'architecture d'Azure Machine Learning et les flux de travail associés comme décrits dans l'article Architecture and concepts: How does Azure Machine Learning service work?.
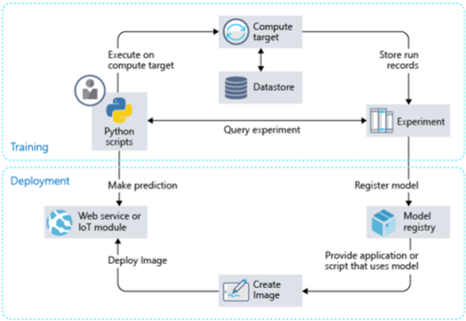
Les SDKs que nous allons aborder tout de suite après ainsi qu'une nouvelle extension Azure CLI (Command Line Interface) pour le Machine Learning permettent d'accomplir concrètement toutes nos tâches de Machine Learning et pipelines qu'il était possible de réaliser au travers de l'application Azure Machine Learning Workbench.
Si l'on revient un instant sur les récentes innovations en matière de Machine Learning, la plupart d'entre elles se produisent dans la sphère du langage Python. C'est pourquoi Microsoft a fait le choix d'exposer les fonctionnalités clé du service via un SDK Python et de façon à pouvoir bénéficier pleinement de tout l'écosystème associé.
Pour plus d'informations, vous pouvez consulter l'article What is happening to Workbench in Azure Machine Learning (preview)?
Si vous avez installé l'application Azure Machine Learning Workbench (et/ou que créé des comptes d'expérimentation et de gestion de modèles), vous pouvez par ailleurs vous reporter à l'article Migrate to the latest version of Azure Machine Learning service afin de migrer vers cette version la plus récente.
Ce nécessaire « point de situation » étant partagé, il est désormais temps de passer aux nouveaux SDKs d'Azure Machine Learning ;-)
SDK principal d'Azure Machine Learning SDK en Python
Le SDK principal d'Azure Machine Learning en Python est destiné à être utilisé par les data scientists et les développeurs d'IA afin de créer et exécuter des flux de travail de Machine Learning avec Azure Machine Learning.
Il s'agit concrètement de pouvoir rapidement construire, entraîner et déployer vos modèles de Machine Learning et de Deep Learning pour différents domaines.
Pour cela, ce SDK comprend dans la pratique un ensemble de packages, avec à la clé différents modules et classes dont vous pouvez tirer parti pour vos flux de travail de Machine Learning :
- azureml-core
- azureml-train-core
- azureml-train-widgets
- azureml-pipeline-core
- azureml-pipeline-steps
- azureml-train-automl
- azureml-telemetry
- azureml_webservice-schema
Comme le souligne Eric Boyd, Corporate Vice President, AI Platform, qui a dirigé cette « ré-imagination » du Service Azure Machine Learning :
"We heard users wanted to use any tool they wanted, they wanted to use any framework, and so we re-thought about how we should deliver Azure Machine Learning to those users. We have come back with a Python SDK that lights up a number of different features."
Ces fonctionnalités comprennent notamment l'apprentissage profond distribué (Distributed Deep Learning), qui permet aux développeurs de construire et d'entrainer des modèles plus rapidement avec des clusters de GPUs (Graphical Processing Units), et d'avoir l'accès aux FPGAs pour l'image scénarios de reconnaissance et de classification à haute vitesse évoqués en introduction sur Azure.
Comme évoqué précédemment, vous pouvez interagir avec ce SDK depuis n'importe quel environnement Python, y compris Jupyter notebook comme avec Azure Notebooks, un service gratuit qui peut être utilisé pour développer et exécuter du code dans un navigateur utilisant Jupyter, ou d'autres IDEs de Python, à l'image de PyCharm, de Visual Studio Code, ou encore d'Azure Databricks et ses notebooks.
Pour plus Visual Studio Code d'informations, vous pouvez consulter l'article What is the Azure Machine Learning SDK for Python?
SDK de préparation des données d'Azure Machine Learning
Comme nous avons pu l'illustrer sur ce blog, la préparation des données constitue une part importante d'un flux de travail de Machine Learning.
Vos modèles seront plus précis et efficaces s'ils ont accès à des données propres dont le format est facile à utiliser.
Le SDK de préparation des données d'Azure Machine Learning en Python permet de charger des données dans différents formats, de les transformer pour être plus facilement utilisable et d'écrire ces données à un emplacement afin que vos flux de travail de Machine Learning et vos modèles dans ce contexte puissent y accéder.
A l'instar du SDK précédent, vous pouvez interagir avec ce SDK depuis n'importe quel environnement Python.
Le SDK de préparation des données d'Azure Machine Learning présente certains avantages par rapport à d'autres bibliothèques populaires dans le domaine de la préparation des données, comme par exemple la bibliothèque d'analyse de données Pandas :
- La lecture intelligente. Le SDK peut détecter automatiquement tous les types de fichiers pris en charge. On n'a donc pas besoin d'utiliser de lecteurs de fichiers spéciaux pour CSV, texte, Excel, etc., ni de spécifier des paramètres de délimiteur, d'en-tête ou de codage.
- Le passage à l'échelle en streaming. Plutôt que de charger toutes les données en mémoire, le moteur du SDK fournit les données en continu ; ce qui lui permet de s'adapter et de mieux fonctionner sur les grands volumes de données.
- Une fonctionnalité multi-plateforme avec un script de code unique. Votre code Python est écrit sur la base d'un seul SDK et vous pouvez l'exécuter sous Linux, MacOs, Spark ou Windows avec une évolutivité verticale (mode « scale-up ») ou horizontale (mode « scale-out »). Lors de l'exécution en mode « scale-up », le moteur tente d'utiliser tous les threads matériels disponibles. Lorsqu'il exécute en mode « scale-out », il permet au planificateur distribué d'optimiser l'exécution.
Pour plus d'informations, vous pouvez consulter les articles suivants :
- What is the Azure Machine Learning Data Prep SDK for Python?
- Load and read data with Azure Machine Learning
- Transform data with the Azure Machine Learning Data Prep SDK
- Write data using the Azure Machine Learning Data Prep SDK
Ces articles vous donneront une bonne compréhension de l'API ainsi mise à disposition par le SDK de préparation des données d'Azure Machine Learning en Python.
Pour ce qui est d'une référence API à proprement parlé, la documentation des différents modules du package azureml-dataprep
ici.
La présentation de certaines évolutions clé du service Azure Machine Learning étant désormais chose faite avec en point principal la disponibilité de nouveaux SDKs d'Azure Machine Learning en Python, nous vous proposons d'aborder dans la seconde partie de ce billet une illustration concrète de ceux-ci au travers de la réalisation d'un flux de travail complet de Machine Learning avec le Service Azure Machine Learning.