Une mise en perspective…
Annoncés en cascade depuis l'automne 2017, à commencer par la refonte d'Azure Machine Learning et ses nouveaux services (service d'expérimentation, packages Azure Machine Learning, service de gestion des modèles, et application Workbench) – celle-ci a donné lieu à toute une série de billets sur ce même blog, de nombreux services, Framework et outils de Machine Learning de Microsoft traduisent de façon concrète la politique de Microsoft de s'investir (toujours plus) dans les technologies d'Intelligence Artificielle (IA).
Dans l'actualité récente, citons en particulier :
- D'abord ONNX (Open Neural Network Exchange), un format open source de modèles de Machine Learning et de réseau de neurones, développé par Microsoft en coopération avec notamment Facebook et Amazon.
- Ensuite ML.NET, un Framework de Machine Learning à part entière qui permet de simplement créer ses propres modèles dans un environnement .NET.
- Et finalement Windows ML, une plateforme pour les applications Windows qui permet d'y apporter des fonctionnalités de Machine Learning.
Vous pouvez vous renseigner plus en détail sur ces outils en consultant les différents billets qui leur sont dédiés sur ce même blog (ONNX, ML.NET et Windows ML).
Au-delà de leurs capacités intrinsèques multiples et en évolution continue, il nous semble important de mettre en perspective les possibilités offertes par une utilisation conjointe de ces outils ; d'où l'idée de profiter de l'espace de ce billet pour présenter un exemple possible d'utilisation de ces outils ensembles.
Je tiens à remercier Pierre Lataillade actuellement en stage de fin d'étude au sein de Microsoft France pour cette contribution.
Une petite démonstration
Comme évoqué ci-avant, l'idée même de cet exemple consiste à illustrer et suivre l'emboitement naturel de chacun de ces outils afin de créer un exemple cohérent et auto-suffisant.
Cette succession naturelle peut se traduire comme suit :

- Commencer par d'abord entrainer un modèle de Machine Learning sur ML.NET,
- Puis l'exporter sous format ONNX.
- Et enfin l'utiliser dans une application UWP grâce à la plateforme Windows ML.
Le code source de cet exemple est disponible sur GitHub sur ce repo.
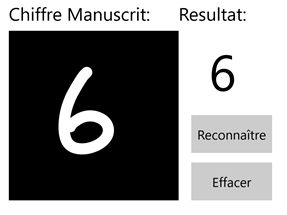
L'utilisation finale de cet exemple est la suivante : on veut pouvoir utiliser une application UWP pour reconnaitre des chiffres manuscrits qui y sont dessinés.
La capture d'écran ci-dessous donne une idée de l'application de cet exemple.
Pour arriver à ce résultat, nous allons donc utiliser les outils mentionnés précédemment.
Chez ML.NET
Commençons par le début et donc un programme utilisant ML.NET pour entrainer un modèle de Machine Learning à reconnaitre des chiffres manuscrits.
Pour l'entrainer, nous nous somme basé sur le jeu de donnés classique : MNIST.
Celui-ci a été modifié pour être facilement traitable par un Framework de Machine Learning et peut se trouver sous la forme de deux fichiers dans le dossier mldotnetMNIST : train.csv et test.csv.
Dans cette partie du projet, nous allons procéder en trois étapes pour aboutir à notre résultat désiré, à savoir un modèle de Machine Learning adapté entrainé sur notre jeu de donnés.
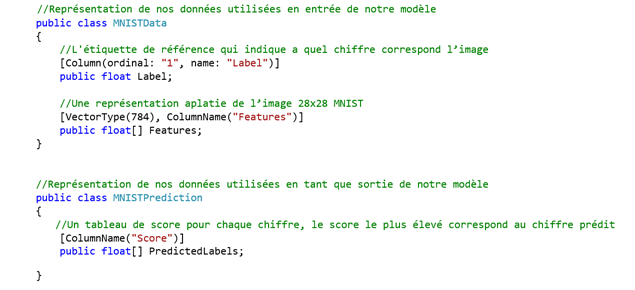
Il s'agit en premier lieu de définir le format d'entrée et de sortie de notre modèle pour pouvoir correctement y lier les données.
C'est l'objet des classes contenues dans le fichier MNISTData.cs.
Ensuite, lorsque l'on lance le programme principal, il convient de créer le pipeline d'apprentissage en utilisant les formats définis ci-dessus, de charger les données d'entrainement et de les lier à notre pipeline d'apprentissage.
Ici, pour les besoins de l'illustration, notre pipeline d'apprentissage est composé de deux étapes : i) l'analyse d'un fichier d'entrée pour en extraire nos données sous le format d'entrée voulu, puis ii) un classifieur multi-classes de régression logistique.
Il s'agit d'un classifieur classique dont on sait qu'il est adapté aux problèmes de reconnaissances de caractères (et donc notamment de chiffres) manuscrits.
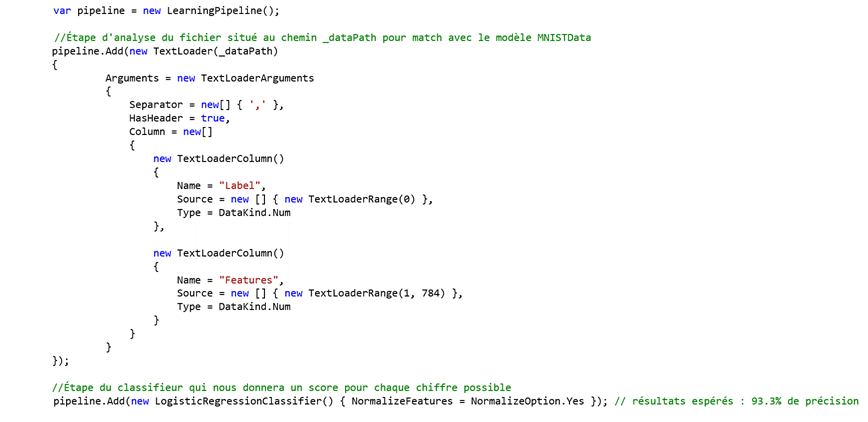
Finalement, on lance l'apprentissage et on exporte le modèle dans le format ONNX voulu. Et voilà !
Les deux premières étapes de notre exemple sont ainsi couvertes.

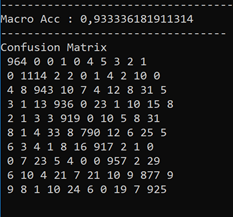
On peut alors effectuer des mesures de test et de validation sur notre modèle pour déterminer si on en est satisfait du résultat.

Ce qui nous donne ces résultats a priori satisfaisants :
Du côté de Windows ML
Il est temps de passer à la troisième et dernière étape de notre exemple.
Pour pouvoir maintenant utiliser le modèle ONNX de Machine Learning ainsi produit dans une application UWP, on s'intéresse naturellement à l'utilisation de la plateforme Windows ML.
Pour les besoins de notre illustration, notre application UWP est dans la pratique une reprise et une modification du code mis à disposition par Microsoft sur ce repo GitHub. Il s'agit comme la capture d'écran précédent le suggère d'une application qui se veut très simple quant à l'utilisation d'un modèle de Machine Learning pré-entrainé pour reconnaitre des chiffres manuscrits dessinés par l'utilisateur.
La solution Visual Studio MNIST_Demo.sln résultante est disponible dans le dossier windowsmlMNIST. (Vous pouvez télécharger gratuitement Visual Studio 2017 Community ici.)
De manière parallèle au cas de ML.NET il s'agit d'abord de définir le format du modèle ainsi que le format de ses entrées et de ses sorties. Comme souligné dans le billet précédent de ce blog, la génération de ces informations s'effectue de manière automatique à partir du modèle ONNX.
Deux opérations sont ensuite nécessaires pour utiliser notre modèle.
Il faut tout d'abord charger le modèle en mémoire. Ceci a lieu au lancement de l'application (fichier MainPage.xaml.cs).

Ensuite, dès que l'on souhaite appliquer le modèle à une donnée, c'est-à-dire, ici, reconnaitre un chiffre manuscrit, il faut lier l'entrée du modèle avec la donnée réelle, ici le contenu d'un canevas), puis appeler la prédiction du modèle.

Ceci nous affiche alors (93% du temps) le bon chiffre manuscrit.
En guise de conclusion
Malgré leurs sorties récentes, ML.NET, ONNX et Windows ML permettent d'ores et déjà de s'agencer entre eux de manière assez intuitive comme nous avons souhaité l'illustrer ici de façon pratique. On arrive alors à produire des résultats satisfaisants à partir d'implémentations somme toute assez minimales.
Avec l'arrivée de nouvelles versions (toujours plus abouties) de ces outils, cette fluidité devrait continuer à s'améliorer, tout en gardant cette simplicité d'implémentation ! :-)