Créer et interroger votre service web avec Azure ML
Azure Machine Learning Studio permet depuis ses débuts de déployer un service web pour pouvoir interroger votre modèle préalablement entrainé. Vous pouvez bien évidement faire de même avec le service de gestion des modèles d'Azure Machine Learning (Azure ML).
C'est ce que nous vous proposons d'aborder dans ce billet qui s'inscrit dans la continuité de la série de billets que nous avons initiée depuis cet automne sur les nouveaux services d'Azure ML.
J'en profite pour remercier Paul Jenny actuellement en stage de fin d'étude au sein de Microsoft France pour cette contribution.
Le service de gestion des modèles
En complément du service d'expérimentation d'Azure ML, ce nouveau service vous permet de gérer, comme son nom le suggère, différentes versions de vos modèles, de les déployer dans différents environnements que ce soit sous forme de conteneurs Docker ou de service web HTTP pour être facilement réutilisable via un simple appel de type REST. Comme mentionné ci-avant, nous nous intéressons ici au second cas de figure.
Dans la pratique, 4 étapes sont nécessaires pour pouvoir créer tel un service web :
- Enregistrement du modèle auprès du service de gestion des modèles ;
- Création d'un manifeste spécifiant les dépendances associées à un modèle ;
- Création de l'image docker basé sur un manifeste ;
- Déploiement du conteneur docker sous forme de service web en temps réel.
Quelques prérequis
Pour pouvoir déployer vos modèles, vous devez avoir, au préalable, préparer un environnement de déploiement. Si vous ne l'avez pas encore fait, nous vous invitons à lire la partie « Préparation de l'environnement de déploiement » dans le billet Mise en place d'un environnement de cette série.
Vous devez avoir aussi, bien évidemment, sauvegardé votre modèle entrainé sous forme d'objet Python sérialisé dans un fichier.
Le fichier de score du service
La première étape consiste à créer le fichier de score qui permettra à votre service web de donner un score aux données reçues en entrée. Celui-ci doit être composé d'au moins deux fonctions indispensables :
init() : cette fonction est appelée au démarrage du service web pour pouvoir, par exemple, récupérer le modèle entrainé ou encore activer la fonctionnalité de collecte des données d'entrée et de sortie du service pour archivage des entrées / sorties.
def init():
from sklearn.externals import joblib
global model, inputs_dc, prediction_dc
# Chargement d'un modèle entrainé sur scikit-learn (plus rapide que pickle)
model = joblib.load('model.pkl')
# Activation de la collecte de données en entrée
inputs_dc = ModelDataCollector('model.pkl',identifier="inputs")
# Activation de la collecte de données en sortie
prediction_dc = ModelDataCollector('model.pkl', identifier="prediction")
- run() : cette fonction est utilisée à chaque réception d'une requête HTTP en entrée. La validation du format de la requête est effectuée en amont de celle-ci si vous avez généré le schéma (Cf. section suivante). Celle-ci doit retourner la réponse du service web, c'est-à-dire la prédiction :
def run(input_df):
global clf2, inputs_dc, prediction_dc
try:
# Prédiction du modèle
prediction = model.predict(input_df)
# Collecte des données d'entrée
inputs_dc.collect(input_df)
# Collecte de la prédiction
prediction_dc.collect(prediction)
return prediction
except Exception as e:
return (str(e))
La création du schéma du service web (optionnel)
Il est possible de demander au service de valider automatiquement les entrées et les sorties de votre service web pour vous assurer du bon fonctionnement de celui-ci. Pour cela, il faut spécifier les formats attendus dans un fichier JSON.
Il est préférable de le générer directement depuis votre fichier score dans la fonction main(), par exemple, pour pouvoir conserver un format à jour.
Tout d'abord, il est nécessaire d'importer 3 bibliothèques d'Azure ML dans un fichier Python :
from azureml.api.schema.dataTypes import DataTypes
from azureml.api.schema.sampleDefinition import SampleDefinition
from azureml.api.realtime.services import generate_schema
Ensuite, vous devez spécifier le type de données attendu avec un exemple de données d'entrée :
Pour un tableau Numpy :
inputs = {"input_array": SampleDefinition(DataTypes.NUMPY, yourinputarray)}
Pour un tableau Spark :
inputs = {"input_array": SampleDefinition(DataTypes.SPARK, yourinputarray)}
Pour un tableau Pandas :
inputs = {"input_array": SampleDefinition(DataTypes.PANDAS, yourinputarray)}
Et enfin, il convient de générer le schéma associé :
generate_schema(run_func=run, inputs=inputs, filepath='service_schema.json')
Remarque : le paramètre run_func correspond à la fonction run() d'un fichier de score d'un service web. C'est pourquoi il est préférable d'ajouter ces lignes directement dans celui-ci.
L'enregistrement de son modèle
Une fois le fichier de score créé, vous pouvez enregistrer votre modèle auprès du service de gestion des modèles. Cela permet de le sauvegarder dans le cloud pour une utilisation future et de le déployer dans différentes cibles (notamment en tant que service web).
Pour effectuer cette opération, vous devez utiliser le CLI intégré dans Visual Studio Code (si l'extension Visual Studio Tools for AI est installée) ou depuis Azure ML Workbench.
La commande est suivante :
az ml model register
–model [chemin vers le modèle .pkl - requis]
–name [nom du modèle - requis]
–description [description du modèle - optionnel]
–tag [libellé associé à ce modèle – optionnel]
Dans le résultat de la commande, vous obtiendrez l'identifiant du modèle. Celui-ci vous permettra de le réutiliser dans la suite de cet article.
Une fois cette commande effectuée, vous pouvez apercevoir une nouvelle version de votre modèle via l'utilisation d'Azure CLI avec la commande az ml model list ou du portail de gestion Azure :
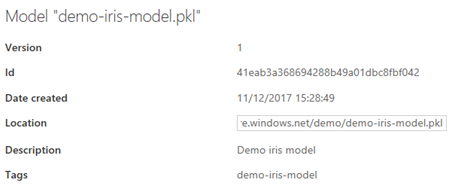
La création du manifeste du/des modèle(s)
Le manifeste représente le lien entre un ou plusieurs modèles, les dépendances associées, le fichier de score ainsi que le schéma des données en entrée et en sortie du service web.
Celui-ci est ensuite utilisé pour construire l'image Docker associée.
Il se crée, lui aussi, à l'aide d'une commande via l'utilisation d'Azure CLI comme suit :
az ml manifest create
--manifest-name -n [nom du manifeste – requis]
-f [chemin vers le fichier de score - requis]
-r [python | pyspark – requis]
--model-id -i [identifiant du modèle – requis]
--conda-file -c [chemin vers un fichier YML contenant les dépendances Conda - optionnel]
--dependency -d [Fichiers et répertoires requis par le service - optionnel]
--manifest-description [description du manifeste – optionnel]
--schema-file -s [chemin vers le schéma du service web – optionnel]
Plusieurs modèles et plusieurs dépendances peuvent être spécifiés dans un même manifeste en multipliant les arguments -i et -d respectivement. Dans le résultat de la commande, vous obtiendrez l'identifiant du manifeste qui est utile pour la suite de ce billet.
Tout comme les modèles enregistrés dans le service de gestion des modèles, vous pouvez apercevoir votre manifeste dans le portail Azure ou en utilisant Azure CLI avec la commande az ml manifest list :
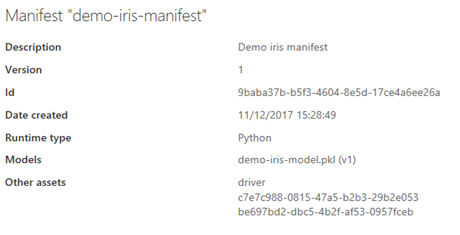
La création de l'image Docker du manifeste
Une fois le manifeste créé, pour pouvoir déployer le modèle dans différents environnements, il est nécessaire pour cela de créer l'image Docker associée.
Remarque : Cette opération peut aussi être effectuée depuis le portail Azure dans votre ressource de gestion des modèles en cliquant sur le manifeste qui sera utilisé pour créer une image puis Create Image :
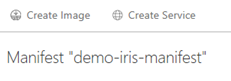
La commande à utiliser pour créer une image Docker est la suivante :
az ml image create
--image-name -n [image name - requis]
--manifest-id [identifiant du manifeste - requis]
--image-description [description de l'image – optionnel]
Le résultat de la commande contient l'identifiant de l'image qui peut être utilisé ensuite pour pouvoir créer un service web.
De plus, tout comme les modèles et les manifestes enregistrés, vous pouvez apercevoir la création de l'image dans le portail Azure ou avec la commande az ml image list :
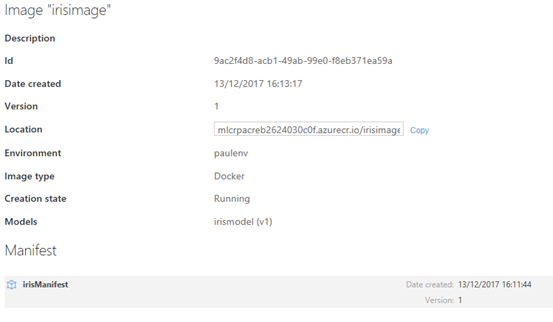
Le déploiement sous forme de service web
Une fois l'image créée, il ne reste plus qu'à la déployer sous forme de conteneur dans Azure.
Remarque : Cette opération peut aussi être effectuée depuis le portail Azure dans votre ressource de gestion des modèles en cliquant sur le manifeste ou l'image qui sera utilisé(e) pour créer le service web puis Create Service :
Pour créer un service avec une image Docker déjà enregistrée auprès du service de gestion des modèles comme dans notre cas de figure, la commande Azure CLI à utiliser est la suivante :
az ml service create realtime
-n [nom du service web – requis]
–image-id [identifiant de l'image à utiliser – requis]
–autoscale-enabled [mise à l'échelle automatique selon les besoins, désactivé par défaut. True | False – optionnel]
–autoscale-max-replicas [si mise à l'échelle automatique activée, nombre max de répliques – optionnel]
–autoscale-min-replicas [si mise à l'échelle automatique activée, nombre min de répliques – optionnel]
--autoscale-refresh-period-seconds [si mise à l'échelle automatique activée, intervalle de temps pour évaluer si mise à l'échelle nécessaire - optionnel]
–collect-model-data [collecte des données en entrée et en sortie, désactivé par défaut. True | False – optionnel]
–cpu [nombre de cœurs CPU réservés par réplique (fraction autorisée) – optionnel]
–enable-app-insights -l [métriques sur les requêtes, désactivé par défaut ; true | false – optionnel]
–memory [mémoire réservée par réplique en M ou G (1M ou 10G) – optionnel]
–z [nombre de répliques pour un service Kubernetes - optionnel]
Remarque : Nous vous recommandons d'activer les métriques sur les requêtes ainsi que la collecte et l'archivage des données en entrée et en sortie pour pouvoir monitorer votre service web et ainsi réagir en cas d'erreurs.
Le service web est automatiquement déployé dans votre environnement de déploiement configuré dans votre Azure CLI.
Encore une fois, vous pouvez accéder à votre service web dans le portail Azure ou via Azure CLI avec la commande az ml service list realtime :
La consommation du service web
Pour pouvoir consommer un service web, il faut au préalable récupérer les informations à propos de celui-ci comme l'URL avec la commande :
az ml service usage realtime -i [identifiant du service web]
Pour tester le service web, la commande à utiliser est la suivante :
az ml service run realtime -i [identifiant du service web] -d "vos données en entrée en format JSON"
Si vous souhaitez consommer le service web via un appel HTTP depuis un programme, vous devez au préalable récupérer les clés d'authentification du service :
az ml service keys realtime -i [identifiant du service web]
La clé d'authentification est à insérer dans l'en-tête d'authentification sous la forme "Authorization : Bearer [clé d'authentification du service]".
Vous devez aussi paramétrer l'en-tête Content-Type en application/json.
Si vous avez aviez soumis un schéma du service web lors de sa création, vous pouvez récupérer le document Swagger associé situé à :
https://<ip>/api/v1/service/<service name>/swagger.json
Vous pouvez retrouver des exemples de scripts en C# et Python dans la documentation officielle (en anglais).
La surveillance du service web
La surveillance de l'utilisation du service
Si vous avez activé les métriques sur les requêtes via l'argument –enable-app-insights lors de la création du service web, vous pouvez surveiller son utilisation directement depuis le portail Azure en accédant à votre service web via votre service de gestion des modèles avec le service Azure Application Insights.
Vous pouvez récupérer l'URL d'Azure Application Insights directement depuis Azure CLI avec la commande :
az ml service usage realtime -i [identifiant du service web]
La récupération des données d'entrée et de sortie du service
Si vous avez activé la collecte et l'archivage des données d'entrée et de sortie de votre service web via l'argument –collect-model-data lors de sa création , vous pouvez récupérer alors ces données pour les étudier en cas de problèmes.
Pour cela, vous pouvez les récupérer depuis le portail Azure puis aller dans la catégorie Comptes de stockage. Si celle-ci n'est pas présente, vous pouvez la retrouver en utilisant la recherche dans Tous les services.
Pour déterminer le compte de stockage associé à votre environnement de déploiement, vous devez entrer la commande az ml env show -v et lire le paramètre storage_account.
Une fois dans le compte de stockage, accédez à la section Parcourir les objets blob puis accédez au conteneur modeldata. L'ensemble des données archivées sont dans un fichier CSV sous l'URL suivante :
/modeldata/<subscription_id>/<resource_group_name>/<model_management_account_name>/<webservice_name>/<model_id>-<model_name>-<model_version>/<identifier>/<year>/<month>/<day>/data.csv
Les données provenant d'Azure Blob peuvent être consommées de différentes façons :
- Azure Machine Learning Workbench ;
- Microsoft Excel ;
- Microsoft Power BI (création de graphiques) ;
- Et d'autres…
Remarque : Les données peuvent mettre jusqu'à 10 minutes après la requête pour être propagées dans votre compte de stockage.
En guise de conclusion
A travers ce billet, vous avez pu découvrir - si tel n'était pas encore le cas - le service de gestion des modèles d'Azure ML qui permet, entre autres, la création d'un service web basé sur un modèle entrainé en quelques étapes seulement.
Néanmoins, vous pouvez aussi déployer votre modèle dans des périphériques en bordure avec Azure IoT Edge. Ce point sera traité dans un autre billet de cette même série prochainement.
Enfin, si vous avez le moindre problème lors du déploiement de vos modèles, vous pouvez vous référer au Guide de résolution des problèmes liés au déploiement ici.