Ask Learn
Preview
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign inThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Pour utiliser les nouveaux services d'Azure Machine Learning (Azure ML), il convient au préalable créer un compte et les ressources associées sur Azure. Après avoir abordé les évolutions d'Azure ML dans un précédent billet, ce billet vise à vous présenter une vue d'ensemble de la mise en place d'un environnement de travail complet Azure ML en intégrant bien sûr l'installation de l' « établi » Azure ML Workbench et l'outillage en mode ligne de commandes. De plus, dans ce contexte, ce billet est l'occasion de s'intéresser votre environnement de développement intégré (IDE) pour Azure ML Workbench avec Visual Studio Code, la mise en œuvre de la technologie de Docker, etc. pour la science des données.
J'en profite pour remercier Paul Jenny actuellement en stage de fin d'étude au sein de Microsoft France pour cette contribution.
 L'application Azure ML Workbench peut être installée sur les plateformes suivantes pour le moment :
L'application Azure ML Workbench peut être installée sur les plateformes suivantes pour le moment :
Qui dit services managés dans Azure, dit abonnement Azure. Si vous n'avez encore de compte Azure, vous pouvez créer un compte gratuit ici.
Nous supposons que vous disposez à ce stade d'un tel compte.
Vous devez au préalable vous connecter au portail Azure avec vos identifiants de compte Azure :
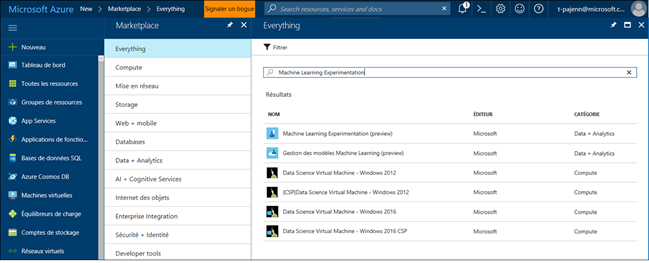
Sélectionnez Machine Learning Experimentation (preview) .
Cliquer ensuite sur Créer.
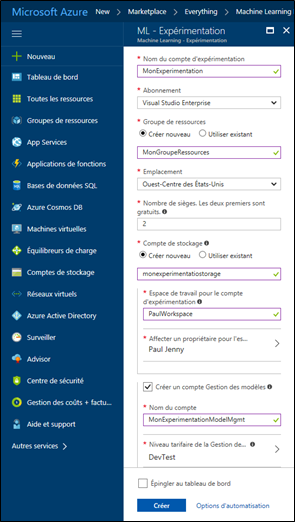
Un panneau (blade en anglais) ML – Expérimentation s'ouvre. Remplissez le formulaire correspondant en s'aidant des indications ci-dessous :
Cliquez enfin sur Créer pour créer votre compte d'expérimentation (et le compte Gestion des modèles si vous avez coché la case – ce que nous suggérons ici -)
Attendez le déploiement effectif des services qui sera indiqué par une notification :
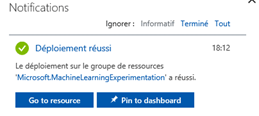
Si vous avez pour projet de déployer des modèles de Machine Learning en production via le service de gestion des modèles d'Azure, vous devez au préalable créer un compte Machine Learning Compute. Ce compte permet la création d'un environnement virtuel pour déployer les modèles.
Remarque : Pour déployer les modèles, vous devez aussi avoir créé un service de gestion des modèles auparavant.
Remarque : Si vous utilisez un abonnement Azure avec une limite de dépense prépayée, vous ne pourrez pas déployer d'environnement Machine Learning Compute. Vous devez ajouter un moyen de paiement et supprimer la limite de dépense sur Azure Subscriptions.
Vous pouvez accéder aux instructions pour pouvoir créer votre compte en accédant à votre compte d'expérimentation sur le portail Azure (en le recherchant ou cliquant sur l'icône sur le tableau de bord si vous l'avez épinglé). Enfin, cliquez sur l'icône « Découvrez comment configurer Machine Learning Compute pour la Gestion des modèles » :

Un volet s'ouvre sur la droite avec l'ensemble des opérations nécessaires pour créer l'environnement.
Remarque : Si vous avez déjà installé azure-cli-cml et azure-cli sur votre ordinateur personnel, vous n'avez pas besoin d'effectuer les 5 commandes suivantes
Vous devez au préalable créer un environnement virtuel Python pour exécuter les commandes Python dans Azure Shell.
Remarque : Cette opération n'est à effectuer qu'une seule fois pour votre abonnement Azure !
virtualenv -p /usr/bin/python3 <nom_de_votre_projet>
Ensuite, il faut éditer le fichier .bashrc pour ajouter des variables d'environnement à votre terminal. Pour cela, vous pouvez utiliser n'importe quel éditeur de texte (par exemple, nano, vim…) et rajoutez les deux lignes suivantes à la fin :
export PATH="<chemin_vers_l_environnement_virtuel>/bin":$PATH
export PYTHONPATH="<chemin-vers_l_environnement_virtuel>/bin"
Une fois ceci fait, il faut recharger vos variables d'environnement avec la commande source :
source ~/.bashrc
Il faut maintenant passer à l'installation des paquets Azure-CLI et Azure-CLI-ML
<chemin_vers_l_environnement_virtuel>/bin/pip installl azure-cli
<chemin_vers_l_environnement_virtuel>/bin/pip install azure-cli-ml
Remarque : Si vous êtes sur votre ordinateur personnel avec Azure-CLI et Azure-CLI-ML déjà installés, vous devez reprendre à partir de cette étape.
Une fois les paquets installés, il ne reste plus qu'à créer l'environnement Machine Learning Compute distant :
az ml env setup -n <nom-environnement-compute-en-minuscules> -l <emplacement_ressources> -c
Remarque : L'emplacement des ressources est un code correspondant à la région Azure dans laquelle vous souhaitez que l'environnement Machine Learning Compute soit déployé (eastus, westus, westeurope, etc…)
Remarque : Par défaut, Azure vous crée un groupe de ressources avec un nom dépendant de celui de l'environnement. Si vous souhaitez utiliser un groupe existant ou en créer un avec un nom désiré, vous pouvez ajouter l'argument -g
Le déploiement de l'environnement peut mettre plusieurs minutes pour pouvoir être pris en compte. Vous pouvez à tout moment voir le statut de celui-ci avec la commande :
az ml env show -g <nom_groupe_de_ressources_du_cluster> -n <nom_environnement_compute>
Remarque : Si le déploiement échoue, vérifiez que vous n'avez pas de limite de paiement sur votre abonnement Azure.
Une fois approvisionné, vous pouvez définir d'utiliser cet environnement Machine Learning Compute pour vos prochains déploiements :
az ml env set -g <nom_groupe_de_ressources_du_cluster> -n <nom_environnement_compute>
Votre environnement est maintenant prêt !
Comme indiqué en début de ce billet, Azure ML Workbench est disponible pour Windows 10 et Windows Server 2016.
Pour procéder à l'installation de l' « établi » en environnements Windows, téléchargez et exécutez le programme d'installation d'Azure ML Workbench via l'explorateur de fichiers. L'installation inclut les dépendances nécessaires comme Python, Miniconda, Azure CLI (avec Azure ML CLI). Elle peut prendre une trentaine de minutes pour se terminer.
L' « établi » Azure ML Workbench est installé dans le répertoire suivant :
C:\Users\<user>\AppData\Local\AmlWorkbench
Azure ML Workbench est actuellement disponible pour MacOS Sierre et supérieur.
Pour procéder à l'installation de l' « établi » sur MacOS Sierra, téléchargez la dernière version d'Azure ML Workbench puis installer en utilisant Finder (l'installation depuis le navigateur peut poser des problèmes). L'installation inclut les dépendances nécessaires comme Python, Miniconda, Azure CLI (avec Azure ML CLI). Elle peut prendre une trentaine de minutes pour se terminer.
L' « établi » Azure ML Workbench est installé dans le répertoire suivant :
/Applications/AmlWorkbench.app
Pour pouvoir utiliser le nouveau service d'expérimentation d'Azure ML dans un contexte local (c.à.d. pouvoir entraîner un modèle dans un conteneur Docker local), vous devez, au préalable, installer la technologie Docker.
Actuellement, Docker n'est supporté que sur les versions 64 bits de Windows 10 Pro, Entreprise et Education à jour et MacOs El Capitan (ou plus récent).
Remarque : Le service Docker a besoin d'une quantité importante de mémoire vive (RAM) pour pouvoir fonctionner. Si la mémoire est insuffisante, vous serez amené(e) à désactiver ou éteindre des applications au préalable.
Un environnement de développement intégré (IDE) est nécessaire pour pouvoir développer vos projets. Parmi les environnements pris en charge par l' « établi », nous vous conseillons l'utilisation de Visual Studio Code, un éditeur multi-plateformes développé par Microsoft sous licence Open Source MIT. Celui-ci, au-delà de ses caractéristiques intrinsèques, s'accompagne d'un écosystème important d'extensions pour étendre la liste s'il en était besoin des fonctionnalités proposées.
Vous pouvez récupérer la dernière pour MacOS et Windows ici. Une fois le logiciel installé, il faut installer les différentes extensions utiles pour la science des données disponibles depuis la place de marché (Marketplace) des extensions, et en particulier :
Remarque : L'ensemble de ces extensions peuvent être installées directement depuis Visual Studio Code. Pour cela, appuyez sur CTRL + Shift + X pour afficher la fenêtre des extensions. Vous pourrez ensuite rechercher les différentes extensions ci-dessus.
La palette des commandes de Visual Studio Code est affichable en appuyant sur CTLR + Shift + P ou en allant dans Afficher / Palette de commandes… . Par exemple, pour accéder aux commandes pour l'IA, vous pouvez taper « AI » :
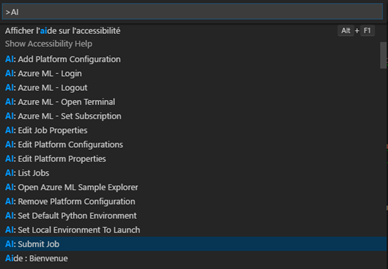
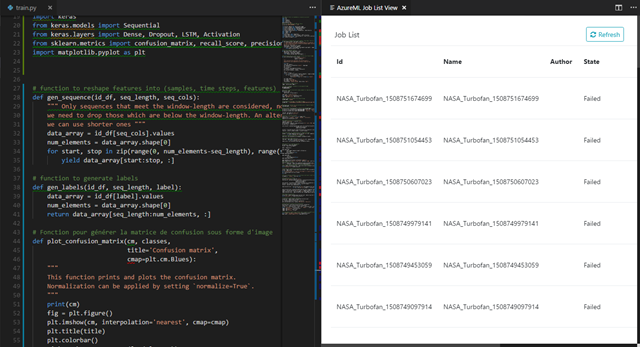
En sélectionnant AI : List Jobs, vous pourrez par exemple accéder à toutes les différentes expérimentations de votre projet directement depuis Visual Studio Code :
Si vous n'avez pas cliqué sur le bouton Launch Workbench à la fin du programme d'installation d'Azure ML Workbench ou si vous avez fermé l'application, vous pouvez double-cliquer sur l'icône sur votre bureau pour pouvoir la lancer :
Azure ML Workbench n'est pas un éditeur de texte. Il est déconseillé d'éditer directement des fichiers depuis le logiciel malgré la présence de fonctionnalités basiques pour l'édition. Visual Studio Code vient donc en complément des nouveaux services pour fournir un environnement de développement de solutions de science des données complet.
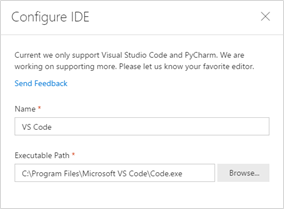
Depuis Azure ML Workbench, accédez au menu File puis Configure Project IDE. Un menu s'ouvre sur la droite de l'application.
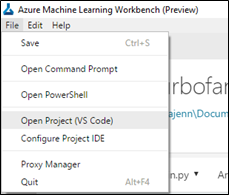
Une fois paramétré, lorsque vous aurez sélectionné au préalable un projet dans Azure ML Workbench, dans le menu File, vous aurez Open Project (VOTRE EDI) :
En cliquant sur Open Project, Visual Studio Code s'ouvre dans le répertoire de votre projet Azure ML Workbench. Vous pourrez ainsi éditer les fichiers depuis l'éditeur de Visual Studio.
Votre environnement Azure ML est à ce stade installé et configurer sur votre machine. Vous pouvez maintenant utiliser Azure ML Workbench ou les outils en ligne de commande pour interagir avec les nouveaux services. Abordons la partie « Docker ».
Afin d'accélérer la remontée des informations de votre exécution par télémétrie, il est conseillé d'activer le partage de votre disque local. De plus, ce paramétrage est nécessaire si vous souhaitez utiliser le répertoire partagé entre votre hôte et votre conteneur (Cf. La Gestion des fichiers dans votre projet Azure ML ci-dessous).
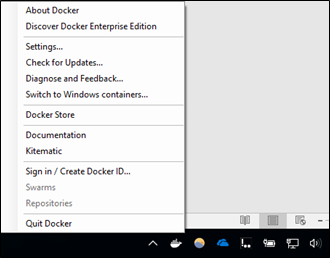
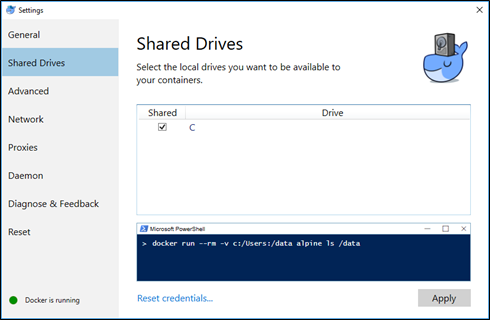
Pour modifier le paramètre, une fois Docker lancé, vous pouvez atteindre le panneau de configuration de Docker en effectuant un clic-droit sur l'icône Docker située dans votre zone de notifications pour Windows puis Settings :
Une fois la fenêtre, vous devez aller dans Shared Drives puis cocher la case située à gauche de votre lecteur (sur lequel est situé Azure ML Workbench dans un contexte local de préférence) puis Apply :
Grâce aux nouveaux services d'Azure ML, vous pouvez aisément exécuter vos scripts d'un projet dans différents contextes, qu'ils soient distants (Docker, HDInsight, etc.) ou locaux (Docker, Python ou R). Néanmoins, cette facilité d'opérationnalisation des projets apporte certaines subtilités quant à la gestion des fichiers (lecture, écriture). En effet, pour respecter les principes de reproductibilité et portabilité (quel que soit le contexte de calcul de l'exécution précédente, si vous exécutez le même script deux fois, vous obtiendrez le même résultat), certaines contraintes ont été ajoutées, étant donné qu'à chaque expérimentation, l'ensemble de votre projet est copié dans le contexte d'exécution.
Ainsi, stocker des fichiers lourds dans votre projet est fortement déconseillé. Une limite est actuellement mise à 25 Mo pour forcer l'utilisation d'alternatives. Il existe actuellement 3 solutions (cumulables) :
Voyons ce qu'il en est.
La première option consiste à utiliser un répertoire prévu dans le fonctionnement des services d'Azure ML. Les fichiers situés dans ce répertoire sont versionnés et peuvent être récupérés ultérieurement (grâce au service d'expérimentation). Par exemple, on pourrait imaginer stocker un modèle entrainé qui a été produit par le script ou encore un graphique (une matrice de confusion, etc.)
Attention : En versionnant des fichiers, vous utilisez du stockage dans Azure. Cela peut entraîner un (très léger) surcoût .
En bref, cette option s'avère préférable pour les conditions suivantes :
Pour recourir à cette option, vous devez écrire les fichiers que vous désirez garder dans un répertoire nommé outputs situé à la racine de votre projet. Le service d'expérimentation détectera automatiquement les fichiers et effectuera le traitement nécessaire pour les versionner. Les fichiers pourront ensuite être téléchargés depuis l'interface d'Azure ML Workbench ou via la ligne de commande Azure CLI suivante :
az ml asset download
La seconde option conste à utiliser le répertoire partagé entre les expérimentations d'Azure ML. A la différence du répertoire précédent, les fichiers dans ce répertoire ne sont pas versionnés et ne peuvent être téléchargés. Par conséquent, les fichiers situés dans ce répertoire ne peuvent être utilisés que par les scripts s'exécutant dans un même contexte.
En conséquence, il est préférable d'utiliser cette solution dans les cas suivants :
Pour recourir à cette option, vous devez utiliser la variable d'environnement AZUREML_NATIVE_SHARED_DIRECTORY dans votre script et configurer l'emplacement du répertoire dans le fichier de configuration .compute de votre contexte d'exécution avec le paramètre nativeSharedDirectory. Par défaut, il est fixé à :
Il existe un cas particulier où vous devez paramétrer une variable supplémentaire. En effet, lorsque vous procédez à une exécution dans un contexte Docker qu'il soit local ou distant, vous devez ajouter la variable sharedVolumes à true :
Depuis Docker, ce répertoire partagé entre l'hôte et le conteneur est toujours défini comme étant /azureml-share/ . Néanmoins, pour des soucis de compatibilité future, il est conseillé d'utiliser la variable d'environnement AZUREML_NATIVE_SHARED_DIRECTORY au lieu du chemin absolu vers ce répertoire.
Remarque : Pour utiliser ce paramètre sous Docker, vous devez activer le partage du disque local avec vos conteneurs dans Docker. Cf. section « La configuration de Docker avec AzureML ».
La dernière option consiste à utiliser un espace de stockage externe pour persister des données à travers vos différentes expérimentations (support externe physique comme une clé USB accessible par le contexte de calcul, espace de stockage en ligne, etc.). Il est préférable d'utiliser cette alternative dans les cas suivants :
Une des solutions est d'utiliser un stockage Blob dans Azure. Vous devez, au préalable, avoir créé pour cela un compte de stockage Azure dans votre abonnement Azure. Pour cela, vous devez naviguer vers le portail Azure puis aller dans Comptes de stockage et Ajouter :
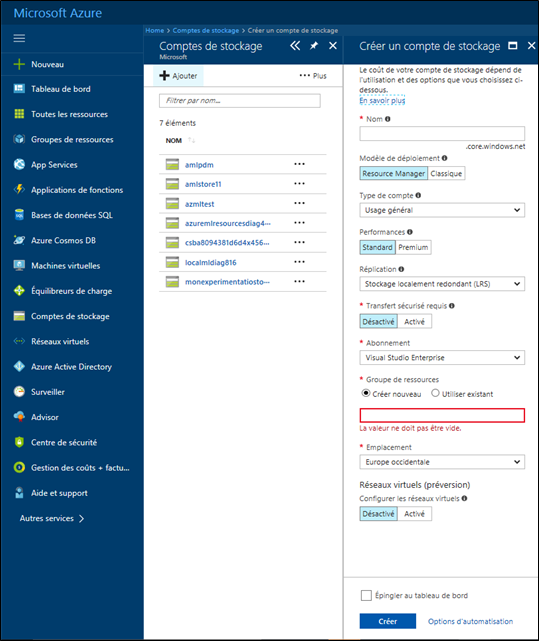
Les fichiers contenus dans le stockage Blob sont situés dans des conteneurs. Ci-dessous, vous pourrez trouver un exemple pour créer et téléverser des fichiers en Python ici (d'autres langages sont disponibles dans la documentation).
Votre environnement Azure ML est à ce stade installé et configuré. Vous possédez une large palette d'outils pour développer des solutions de Machine Learning et de Deep Learning.
Dans le prochain billet, vous apprendrez à utiliser les services avec un cas d'exemple de bout-en bout : la maintenance prédictive.
En attendant, vous pouvez parcourir la documentation officielle ici ;-)
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign in