Quand le Deep Learning permet l’apprentissage par renforcement des robots industriels – 3ième partie
Dans les précédents billets, nous avons posés les fondements nécessaires à la mise en œuvre d'une intelligence artificielle permettant à un robot industriel KUKA de type LBR iiwa 7kg d'opérer des tâches de tri sélectif de manière autonome.
Pour mémoire, ces tâches consistent à déterminer le « bon » bac de recyclage pour les canettes, bouteilles d'eau et gobelets en papier. Nous allons nous intéresser dans ce billet à la mise en œuvre à proprement parler du modèle de Deep Learning. (Le billet Une première introduction au Deep Learning publié sur ce même blog vous propose comme son titre l'indique une première introduction.)
L'application d'une intelligence artificielle basée sur un algorithme de Deep Learning n'est pas quelque chose de nouveau. A titre d'exemples, les différents services/APIs RESTful de la suite Microsoft Cognitive Services
(ex Project Oxford) reposent sur l'utilisation de tels algorithmes. Ces services/APIs RESTful couvrent un large panel de cas d'utilisations classiques des algorithmes du Deep Learning, allant de la reconnaissance d'image et de texte, à la compréhension de la voix. (Le billet Rendez vos applications plus intelligentes avec les services cognitifs publié sur ce même blog revient sur les possibilités offertes par Microsoft Cognitive Services.)
De même, Skype Translator constitue un autre cas d'utilisation novateur où intervient le Deep Learning et permet d'obtenir des résultats très satisfaisant.
Nous allons voir ici comment utiliser ce genre d'algorithmes afin de déterminer automatiquement, et sans traitement en amont, le bon bac de recyclage en fournissant à l'algorithme uniquement l'image de l'objet à trier, dans le cas présent une canette, une bouteille d'eau ou un gobelet en papier.
Le domaine de l'apprentissage profond, ou Deep Learning, permet d'obtenir des résultats bluffant, notamment dans le domaine de la vision par ordinateur. Le graphique ci-dessous, témoigne de l'impact qu'on eût ces algorithmes au travers du challenge ImageNet, challenge visant à entrainer un modèle capable de prédire la classe de certains objets.
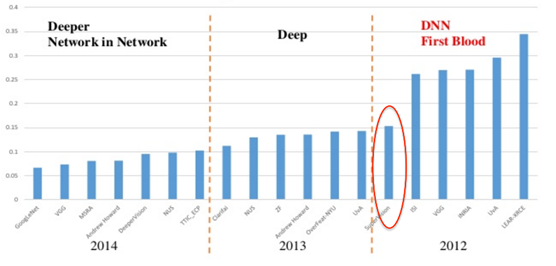
Dans ce domaine, les réseaux de neurones se voient doter d'opérateurs de convolutions, lesquels agissent tels des extracteurs de l'information pertinentes résidants dans une image.
L'autre particularité de ces réseaux de convolution réside dans la manière dont les neurones sont connectés à la couche suivante. Dans le cas de réseaux de neurones dits « classiques », chaque neurone d'une certaine couche est connecté à l'ensemble des neurones de la couche suivante. On parle de couche complètement connectée (fully-connected). Dans le cas présent, les opérateurs de convolutions sont connectés aux neurones spatialement voisins de la couche suivante.
Cette connectivité restreinte permet à ces derniers d'extraire et d'agréger de l'information connexe à chaque couche, réduisant l'espace de recherche pour les couches suivantes. L'information est donc traitée par des processus hiérarchiques et pertinents, comme représenté dans la figure suivante.
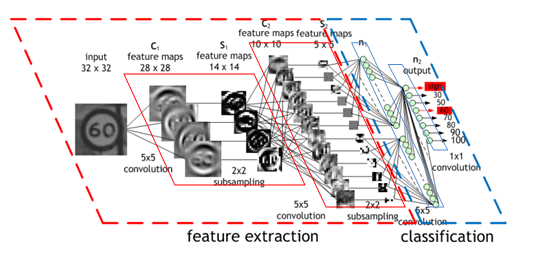
Figure 2 : Schéma complet d'un réseau de convolution (Source : Nvidia blog)
Le nombre important de neurones intervenant au sein de ce genre de topologies est propice à l'apparition de phénomènes de sur-apprentissage.
C'est pourquoi l'entrainement de ces réseaux requiert une grande quantité de données, afin de pouvoir généraliser au mieux.
La récupération du jeu de données d'apprentissage
Afin de pouvoir entrainer notre modèle de Deep Learning, la première étape consistait à mettre en place un jeu de données cohérent avec la tâche que nous souhaitions réaliser, à savoir la détermination du « bon » bac de recyclage.
Pour réaliser cela, nous nous sommes intéressés au challenge ImageNet mentionné ci-avant, et notamment à sa base de données d'images. Pour information, ImageNet est un challenge international, où des chercheurs et des entreprises confrontent leurs modèles de classification dans des tâches de vision par ordinateur, notamment dans la reconnaissance d'objet et la localisation d'objet.
ImageNet propose deux modes d'accès aux données de sa base :
- Un accès direct aux images et au métadonnées. Simple, mais la licence accordée est limitée au cadre de la recherche, ou à un cadre non commercial. Ce type de licence n'était donc pas adapté à notre cas.
- Accès aux URLs sources des images. Un peu plus long et complexe à mettre en œuvre, mais la licence est libre. Nous nous sommes donc tournés vers ce second mode.
Les données dans la base sont organisées en fonction de leur classe, laquelle, dans le jargon d'ImageNet, se nomme un « WordNet ». Il est possible de visualiser l'intégralité des images accumulées dans la base, via l'API, naviguer dans l'arborescence, et enfin, récupérer les différents WordNet à savoir des images qui constitueront notre jeu de données. Pour cela, nous avons utilisé un simple script Windows PowerShell (disponible ici sur le repo de la forge communautaire GitHub), afin de télécharger les différentes images et générer notre fichier contenant le chemin de l'image et sa classe de prédiction.
Le résultat est à ce stade un jeu de données d'environ 6000 images, uniformément réparties entre les différentes classes, nous permettant de commencer à constituer une base de données d'apprentissage suffisamment importante pour réaliser la tâche qui nous incombe ;-)
La topologie du réseau de neurones
La base pour l'apprentissage étant disponible, nous allons pouvoir nous intéresser à la manière d'utiliser notre réseau de neurones pour réaliser la tâche de classification supervisée proposée, à savoir trier les objets à jeter dans le bon bac de recyclage.
Dans le cas actuel, trois approches sont envisageables que nous allons détailler dans les sous parties suivantes :
- L'apprentissage par transfert.
- L'apprentissage basé sur une topologie personnelle.
- L'apprentissage basé sur une topologie existante.
L'apprentissage par transfert
L'apprentissage par transfert repose sur l'idée que :
Si un modèle déjà entrainé possède une bonne capacité de généralisation,
Alors il est possible de réutiliser ce modèle afin de transférer ses compétences vers un autre modèle, en lui servant de base.
Ce genre de transfert se fait en général afin de spécialiser un modèle déjà entrainé pour une tâche plus vaste afin d'en réduire le domaine de sortie. Prenez par exemple un modèle entrainé pour le challenge ImageNet, lequel dispose d'un domaine de sortie de 1000 classes. En utilisant ce procédé, nous sommes en mesure d'utiliser le modèle appris pour 1000 classes, et d'en ajuster finement les paramètres pour qu'il puisse prédire plus précisément nos 3 classes (bouteilles, canettes, tasses).
Cette approche possède des avantages certains, dont le temps nécessaire pour ré-entrainer un modèle spécifique de Deep Learning. La quantité de données nécessaire est elle aussi réduite via l'utilisation d'un modèle très généraliste. De même, le phénomène de sur-apprentissage est moins à-même d'apparaitre.
Cependant, une telle approche nécessite d'avoir accès au modèle entrainé et de pouvoir dynamiquement modifier celui-ci.
L'apprentissage basé sur une topologie personnelle
Une autre approche d'appréhender notre problème consiste à redéfinir entièrement une topologie complète pour notre réseau de neurones.
Cependant, i) le temps imparti étant restreint, et ii) l'apprentissage étant extrêmement coûteux en temps de calcul, il s'avère compliqué d'envisager cette solution à court-terme. Ceci nous amène à la dernière approche.
L'apprentissage basé sur une topologie existante
Cette dernière approche s'appuie quant à elle sur la réutilisation d'une topologie existante, et consiste à réaliser un apprentissage spécifique via les données que nous avons recueillies comme décrit à la section précédente.
Attention, nous parlons ici d'une inspiration quant à la topologie du modèle ; les différents paramètres ne sont pas tirés d'un modèle précédent comme cela était le cas pour l'apprentissage par transfert.
Notre tâche étant relative à ce que propose ImageNet, nous pouvons ainsi nous inspirer des travaux réalisés par les différents chercheurs et entreprises au fil des années pour réutiliser des topologies de réseau de neurones ayant eu de bons résultats sur le challenge.
Nous pouvons citer quelques modèles parmi lesquels :
Ces modèles ont tous permis de réaliser des avancées significatives dans des tâches de classification d'images, et proposent chacun bien sur leurs avantages et inconvénients.
Notre tâche étant relativement simple comparée à ce que sont capables de faire ces modèles, nous nous sommes inspirés du modèle LeNet.
Sur ce modèle, nous avons ajusté, par itération successive, les différents hyper-paramètres (format du filtre de convolution, format du « Pooling », etc.) à chaque couche du réseau de neurones, afin d'éviter au maximum le risque de sur-apprentissage sur notre jeu de données relativement restreint.
L'entrainement du réseau de neurones
Outre la topologie des modèles de Deep Learning – cette dernière fait intervenir de nouveaux opérateurs, des phénomènes de récurrence, etc. -, il est un autre facteur à prendre en compte. Ce dernier concerne l'optimisation des nombreux paramètres du modèle.
Les réseaux de neurones, en général, sont entrainés en utilisant la méthode dite de la « descente du gradient ». Il s'agit en fait de minimiser une fonction suivant un critère de pertinence du modèle, et ce par itérations successives, en se basant sur les variations de la fonction (c.à.d. sa dérivée).
Pour réaliser cet apprentissage, nous avons utilisé comme précédemment évoqué le Framework CNTK (Computational Network ToolKit), l'outil de Deep Learning développé par Microsoft Research (MSR) et disponible en Open Source sur le repo/la forge communautaire GitHub.

Ce Framework intègre directement un moteur d'optimisation par descente de gradient, ainsi que les différents paramètres et fonctions nous permettant de déclarer et entrainer notre modèle. Le billet CNTK, quoi de neuf ? publié sur ce même blog revient sur les dernières nouveautés apportées à ce Framework.
Afin d'entrainer notre modèle de Deep Learning, nous avons utilisé une machine virtuelle de type D5_V2 dans l'environnement d'exécution Microsoft Azure.
Ce type de machine possède les spécifications suivantes :
- 16 cœurs
- 56 Go de RAM
- Stockage SSD
( Comme indiqué ici, les instances de la série Dv2 sont basées sur la dernière génération de processeur Intel Xeon® E5-2673 v3 (Haswell) de 2,4 GHz et peuvent aller jusqu'à 3,2 GHz avec Intel Turbo Boost Technology 2.0. Les séries Dv2 sont idéales pour les applications nécessitant des processeurs plus rapides, de meilleures performances des disques locaux ou des mémoires plus volumineuses. )
Cette configuration nous a permis de satisfaire l'intégralité de nos besoins, à savoir : la puissance de calcul, la capacité à charger l'intégralité du jeu de données en mémoire et enfin, la possibilité de stocker le jeu de données ainsi que les différents fichiers d'étapes « checkpoints » de CNTK.
(Pour mémoire, CNTK est directement fournit prêt à l'emploi sur les machines virtuelles Data Sciences proposées dans Azure).
L'initialisation du modèle
Pour être en mesure de réaliser un apprentissage robuste et convergeant, il est du ressort du scientifique des données (data scientist) de veiller à un certain nombre d'hyper-paramètres, contrôlant dans la pratique la manière dont les paramètres (c.à.d. les pondérations de nos neurones) vont être optimisés.
Ces hyper-paramètres permettent d'agir sur la vitesse de convergence, la manière dont sont mis à jour les paramètres du modèle de Deep Learning ou encore la taille de l'échantillon utilisé.
De plus, il est important de veiller à la façon dont les pondérations sont initialisées lors de la création du modèle. En effet, l'un des phénomènes que l'on observe très souvent lors de l'entrainement de réseaux de neurones profonds, concerne la mise à jour des pondérations des neurones. À chaque itération, la pondération de chaque neurone va être ajustée proportionnellement à la valeur du gradient de la fonction d'erreur et ce, vis-à-vis de la pondération actuelle de chaque neurone indépendamment des autres.
Ainsi, plus le modèle est profond, plus la valeur gradient propagée lors de la phase d'optimisation est faible de couche en couche, et ce de façon exponentielle. Ce phénomène connu sous le nom de « disparition du gradient » (c.à.d. vanishing gradient), peut-être contourné de différentes manières.
Nous en avons utilisé deux principales :
- Utiliser une fonction d'activation neuronale dont la dérivée possède certaines caractéristiques intéressantes. C'est le cas notamment de la fonction d'activation linéaire rectifiée (ReLU = Rectified Linear Unit)
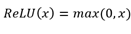
dont la dérivée est :
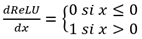
- La dérivée de la fonction ReLU n'est normalement pas définie en 0, mais il est courant de l'approximer de la sorte dans le cadre de l'optimisation par descente de gradient.
- Initialiser les pondérations aléatoirement en suivant une distribution gaussienne
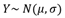 dont les paramètres sont calculés à partir des caractéristiques de la couche précédente :
dont les paramètres sont calculés à partir des caractéristiques de la couche précédente :
- Initialisation dites « de Xavier » (Glorot and Bengio. )
- Initialisation pour les activations linéaires rectifiées (He, Zhang, Ren et Sun . )
Ainsi, dans le cadre de notre projet, nous avons donc utilisé des activations linéaires rectifiées sur chacune des couches de notre réseau de neurones. La valeur initiale de chacun des neurones est fixée via l'initialisation appropriée pour les activations linéaires rectifiées.
Le suivi de l'évolution de l'apprentissage
CNTK fournit une interface en ligne de commande permettant de suivre l'évolution de l'optimisation (ou non :-)) de la fonction objective. Parmi les informations fournies par la sortie de CNTK, il est possible de visualiser les paramètres suivants :
- L'itération actuelle,
- La valeur actuelle de la fonction à minimiser,
- Le taux d'erreur actuellement commit par le modèle,
- Le temps nécessaire pour réaliser l'itération,


Figure 4 : Visualisation des différents critères d'évaluation et d'optimisation du modèle en phase d'apprentissage |
Figure 5 : Visualisation de l'erreur sur le jeu d'apprentissage et sur le jeu de validation |
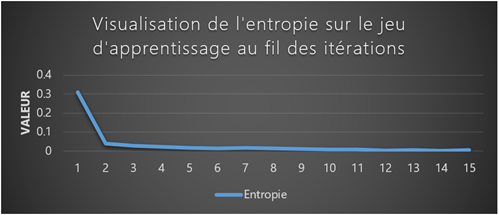
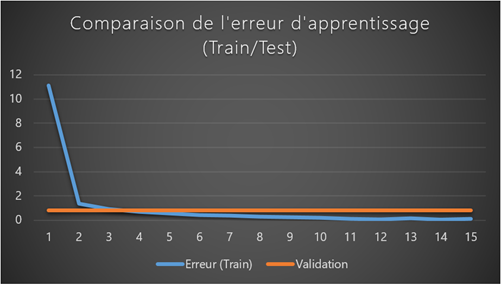
Enfin, lorsque l'entrainement du modèle s'achève, CNTK génère un fichier binaire, contenant :
- La topologie du réseau (auto descripteur)
- Les différentes pondérations de chacun des neurones
Ce fichier peut être utilisé sur un autre support que la machine ayant permis de faire l'apprentissage. Il est donc tout à fait envisageable de déplacer ce modèle de Deep Learning sur des systèmes embarqués, ou bien dans Azure afin de pouvoir utiliser ce modèle pour l'évaluation comme nous l'avons envisagé dans le second billet en termes de modèles de déploiement.
C'est ce point que nous allons détailler dans la prochaine section (ainsi que dans le prochain billet).
Le modèle généré, nommé KukaNet, contient ainsi toutes les informations nécessaires pour son utilisation par le moteur d'évaluation de CNTK (variables, constantes, topologies, etc.).
La mise en œuvre concrète avec CNTK
Comme énoncé plusieurs fois dans ce billet, nous avons utilisé le Framework CNTK afin de réaliser l'entrainement et le modèle final.
(Les billets Une illustration du Deep Learning : Monitorer son activité quotidienne en temps réel – 1ère partie et Une illustration du Deep Learning : Monitorer son activité quotidienne en temps réel – 2nde partie précédemment publiés sur ce même blog vous propose comme leur titre l'indique une autre illustration de la mise en œuvre de CNTK)
CNTK repose sur l'utilisation à minima de deux fichiers :
- Le premier décrit la topologie du réseau de neurones,
- Le second permet de décrire comment lire les données ainsi que les différents paramètres régissant l'entrainement du modèle.
Pour notre implémentation, nous avons utilisé trois fichiers, les deux fichiers décrits ci-avant et un dernier fichier regroupant toutes les fonctions utilisées pour l'apprentissage.
Ce fichier shared.bs, est en fait un fichier générique pouvant être utilisé sur différents modèles. Il décrit l'intégralité des opérations et des couches intervenant dans notre/nos réseau(x) de neurones.
ConvND (w, inp, kW, kH, inMap, outMap, hStride, vStride) =
Convolution (w, inp, (kW:kH:inMap), mapDims=outMap, stride=(hStride:vStride:inMap), sharing=(true:true:true), autoPadding=(true:true:false), lowerPad=0, upperPad=0)
ConvNDLayer (inp, kW, kH, inMap, outMap, hStride, vStride, wScale) = [
inWCount = kW * kH * inMap
W = BS.Parameters.Parameter (outMap, inWCount, init='gaussian', initValueScale=wScale, initOnCPUOnly=true)
b = BS.Parameters.BiasParam(1:1:outMap)
c = ConvND (W, inp, kW, kH, inMap, outMap, hStride, vStride)
out = c + b
].out
ConvNDReLULayer (inp, kW, kH, inMap, outMap, hStride, vStride, wScale) =
RectifiedLinear (ConvNDLayer(inp, kW, kH, inMap, outMap, hStride, vStride, wScale))
Ainsi, dans l'exemple ci-dessus, nous avons défini notre couche de convolutions, lesquelles seront utilisées au sein du fichier qui décrit la topologie (c.à.d. le premier).
Les fonctions définies ici utilisent un langage spécifique ou DSL (Domain Specific Language) nommé BrainScript. Ces fonctions peuvent être réutilisées au sein de plusieurs applications/modèles différents, et ce sans avoir à retoucher ces dernières. Il suffit juste d'importer ce fichier de définition.
Une fois vos fonctions éventuellement définies au sein d'un fichier dédié, vous êtes en mesure de décrire la structure de votre réseau de neurones. Ce fichier, KukaNet.bs ici, vous ainsi permet de définir :
- Des constantes,
- Des variables,
- Des opérations complexes (convolutions, pooling, etc.),
- Les différents critères d'évaluation et d'optimisation pour l'entrainement
- Mais aussi la topologie du réseau, l'enchainement des opérations, les transformations, etc.
features = ImageInput(ImageW, ImageH, ImageC, tag = 'feature')
featMean = Mean(features)
featScaled = features - featMean
# Gaussian Weighted initialization scale
convWScale = 7.07
# conv1
cMap1 = 64
conv1 = ConvNDReLULayer(featScaled, 10, 10, 3, cMap1, 2, 2, convWScale)
# pool1
pool1 = MaxNDPooling(conv1, poolW, poolH, poolHs, poolVs)
Dans l'exemple ci-dessus (tiré directement de la topologie utilisée pour ce cas d'usage) nous avons défini 3 variables :
- Features. Il s'agit de la donnée en entrée du réseau de neurones
- FeatMean. Cette variable est calculée directement à l'exécution. Elle contiendra la valeur moyenne de chaque pixel calculé sur l'ensemble du jeu de données.
- FeatScaled. Cette variable contient le résultat de la soustraction entre la valeur des pixels initiaux de l'image auxquels ont été retiré la moyenne de ces derniers.
Puis, nous définissons une constante convWScale, laquelle spécifie la variance accordée lors de l'initialisation des pondérations des différents neurones.
Par la suite, nous déclarons notre première couche, à savoir celle qui recevra nos données d'entrée. Il s'agit ici d'un réseau de convolutions avec 64 filtres dont les dimensions de la matrice de convolution sont 10 * 10 * 3.
Enfin, la dernière couche présentée ici est une couche de « Pooling ». Cette dernière peut être vue comme une fonction d'agrégation. Nous utilisons ici une couche de « MaxPooling » ; cette dernière fournira en sortie le pixel dont la valeur est maximale vis-à-vis de la sortie de nos filtres de convolutions.
Pour couronner le tout, il nous faut décrire à CNTK comment lire les données, et comment réaliser l'entrainement du modèle. Ces opérations sont réalisées au sein d'un fichier, KukaNet.cntk dans notre cas, le dernier, qui précise le format de données, les éventuelles transformations à opérer sur ces données, un processus couramment appelé « data augmentation ».
A titre d'exemple, pour la lecture d'image, voici comment nous avons procédé :
reader = [
verbosity = 0
randomize = true
# Currently for image reader a single sequence is a chunk
# so setting randomization window to 1.
randomizationWindow = 1
# A list of deserializers to use.
deserializers = (
[
type = "ImageDeserializer"
module = "ImageReader"
file = "$ConfigDir$/training_dataset.txt"
# Description of input streams
input = [
features = [
transforms = (
[
type = "Crop"
# Possible values: Center, Random. Default: Center
cropType = "center"
# Crop scale ratio. Examples: cropRatio = 0.9, cropRatio = 0.7:0.9. Default: 1.
cropRatio = 0.9
# Crop scale ratio jitter type.
# Possible values: None, UniRatio, UniLength, UniArea. Default: UniRatio
jitterType = "uniRatio"
]:[
type = "Transpose"
]
)
]
labels = [
labelDim = 3
]
]
]
)
]
]
Dans cette configuration, nous définissons une lecture d'image via l'utilisation du lecteur « ImageDeserializer ». Celui-ci, en plus de fournir le support de différent format d'image, propose différentes transformations à opérer sur celles-ci, telles que :
- Le « scaling » (redimensionnement),
- Le « cropping » (extraite une sous partie de l'image),
- Le « jittering » (modifier le contraste de l'image),
- etc.
Finalement, peut-être le point le plus compliqué à déterminer et néanmoins primordial réside sans la définition de la descente de gradient, c.à.d. l'algorithme utilisé pour entrainer le modèle.
Il est souvent nécessaire d'adopter un cycle itératif pour ajuster ces paramètres, en commençant par exemple avec des pas de gradient assez grand, et en les affinant au fur et à mesure. CNTK propose, à ce titre, plusieurs méthodes de mise à jour du gradient :
- Momentum : Nesterov (1983)
- AdaGrad : Duchi, John; Hazan, Elad; Singer, Yoram (2011).
- RmsProp : Tieleman, T. and Hinton (2012)
Voici la configuration utilisée dans notre cas :
SGD=[
gradUpdateType = RmsProp
epochSize = 1500
minibatchSize = 128
learningRatesPerMB = 0.1*5:0.05*5:0.01*5:0.003*12:0.001*28:0.0003
momentumPerMB = 0.9
maxEpochs = 50
L2RegWeight = 0.0005
dropoutRate = 0*5:0.5
numMBsToShowResult = 2
]
Quelques précisions au passage ;-) :
- Au cours de chaque époque nous visualisons 1500 images issues du jeu de données d'apprentissage
- Chaque mise à jour de gradient intervient après 128 images visualisées
- Nous utilisons un momentum de 0.9
- Le nombre d'itérations de l'entrainement est fixé à 50
- Nous utilisons un procédé de régulation sur les paramètres du réseau de neurones, visant à garder ces derniers les plus faibles possibles (Régularisation L2).
- Nous utilisons un précédé dit de « dropout », lequel autorise l'algorithme à supprimer une connexion entre deux neurones suivant la probabilité p(D), fixée ici à p(D) = 0.5
Encore une fois, nous insistons ici sur le fait que ces paramètres sont issus d'apprentissages successifs ayant conduit à ces valeurs. Il y a fort à parier que d'autres valeurs pourraient-elles aussi convenir !
En guise de conclusion
Le Deep Learning possède cette capacité à générer automatiquement des variables pertinentes à partir de données non-structurées. Dans une approche traditionnelle, il nous aurait fallu effectuer un certain nombre de prétraitement sur nos images, afin que celles-ci soient aisément identifiable par notre modèle.
Cependant, un tel gain sur la phase de prétraitement, rend l'apprentissage plus complexe et de ce fait plus long, en moyenne une journée complète sur notre petit jeu de données.
Il convient donc de véritablement s'assurer de la pertinence d'un modèle de Deep Learning vis-à-vis des autres types d'algorithmes, et ce afin de conserver une véritable plus-value sur l'investissement qu'il requiert.
Le prochain billet revient sur les échanges entre les différents systèmes et composants de la solution envisagée ainsi que sur le format de ces échanges en tant que tel. A suivre donc :-)