Do Both. Now with more pics.
In a previous post, I talked about how I was working on implementing mirroring inside the datacenter for high availability and log shipping between datacenters for disaster recovery. Well I wanted a reason to use my freshly installed live writer and its wicked cool capabilities so I decided to show a screenshot of that model.
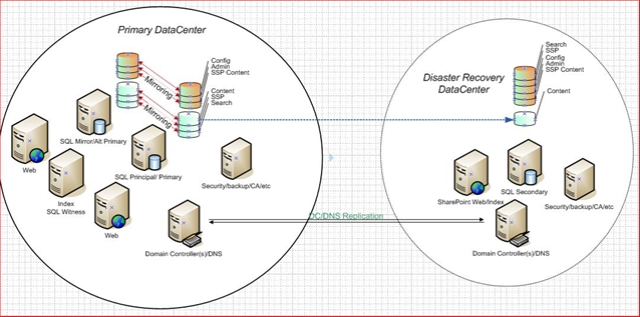
I apologize about the image size. Seems my blog format doesn't offer much real estate. You'll notice that the two large circles represent two datacenters. In this model the datacenters are likely separated by hundreds or even thousands of miles. In the primary datacenter you'll find the minimal highly available topology with two web servers, an index server, and mirrored SQL servers. You'll notice that all databases are mirrored including the configuration database. Now one thing to note about the mirroring configuration is that this isn't really supported yet so if you implement this right now, you are on your on. I do hope that testing will show this configuration is valid in the not too distant future. Also noteworthy is that the index server is also running SQL server and serves as the witness role for the highly available mirroring pair.
In the disaster recovery datacenter, you'll find a single SQL server and a combined SharePoint web/app/index server. Why not another highly available farm? Money. It costs money to build and maintain servers in the remote datacenter so this configuration saves money by discarding some flexibility. Note, I said flexibility, not performance. If you have two web servers you should really be able to support their load on a single server or your farm is not truly highly available. The same goes for SQL. The exception in this model is the index server role which can be intensive, but it is also one you can control through scheduling and throttling.
From a SQL perspective, the farm has its own local versions of all the standard databases with one exception. We are log shipping the content database(s) from the primary farm to the secondary farm. With each log shipped database in standby mode we can attach them to the local web application which the local SSP is configured to search. The trick here is to make the index think it's crawling the url of the primary datacenter, not the local url. You can do this by configuring an AAM for the primary site on the DR web app and adding an entry in the hosts file pointing the url to the localhost address. Finally, remove the local url from the index scope and replace with the AAM. Now schedule the crawl and you will have near seamless failover with instant query. One caveat. When log shipping content databases, any new sites added to your databases will not automatically be available. This is because each new site must also be registered in the configuration database, but without going through the normal process of site creation the only other way to make the site available is to reattach the containing content database. That's easy enough to script, but the problem is that every time you add or reattach a content database, that database gets a new GUID assigned. That doesn't sound bad, but it has major ramifications on search. Each time your content database gets a new GUID, the index server thinks the sites and content in that database are new. I need to continue testing the overall effects of this on search, but so far the most obvious symptom is more crawling.
There are many alternatives to this approach. Check back often as I'm sure I'll be talking about these in the future.