Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
SQL Server Integration Services (SSIS) Blog
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
2012
30daysofssis
ado net
AlwaysOn
API
aps pdw sql server 2016 ssis au5
attunity
Azure
Azure Blob
azure datamarket
azure moon cake azure blog ssis integration services
Azure Storage
azure vm
business rules
Case Study
CDC
chunk data
cleansing
cluster support
collation
conference
conferences
Configuration
Connectivity
constraints
ctp3
cu1
cu2
data cleansing
data enrichment
datamarket
data profiling
data quality
data quality service
data quality services
data warehousing
demo
denali
Documentation
domain rules
dqs
dqs cleansing
dqs cleansing component
dqs installation
dqsinstaller
dqs setup
dqs ssis
error output
Excel
execute process task
execute sql task
expressions
Extensions
ezapi
FAQ
fuzzy
General
Getting Started
hd insight
High Availability
IaaS
iaas ssis sql server azure vm sql vm
Install
installing dqs
introduction
katmai
knowledge base
known issues
language support
learning resources
links
logging
lookup
machine learning
master data services
matching
mdde
MDM
mds
Oracle
pass
pattern matching
Performance
performance enhancements
PowerShell
rc0
reference data
reference data service
Reporting
samples
scale out
scale out ssis odata dynamics ax crm
script
script task
service pack 1
Setup
slowly changing dimension
smo
sp1
sql2012
sql2016
sqlserver
SQL Server
sql server 2012
SQL Server 2016
sql vm
SSDT
ssdt designer
ssis
ssis 2008
ssis 2008 r2
ssis 2012
ssis blog
ssis catalog
ssisdb
stored procedures
teched
Templates
Tutorial
unicode support
Updates
Upgrade
validate
Video
visual studio 2012
vulcan
Webcast
XML
- Home
- SQL Server
- SQL Server Integration Services (SSIS) Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
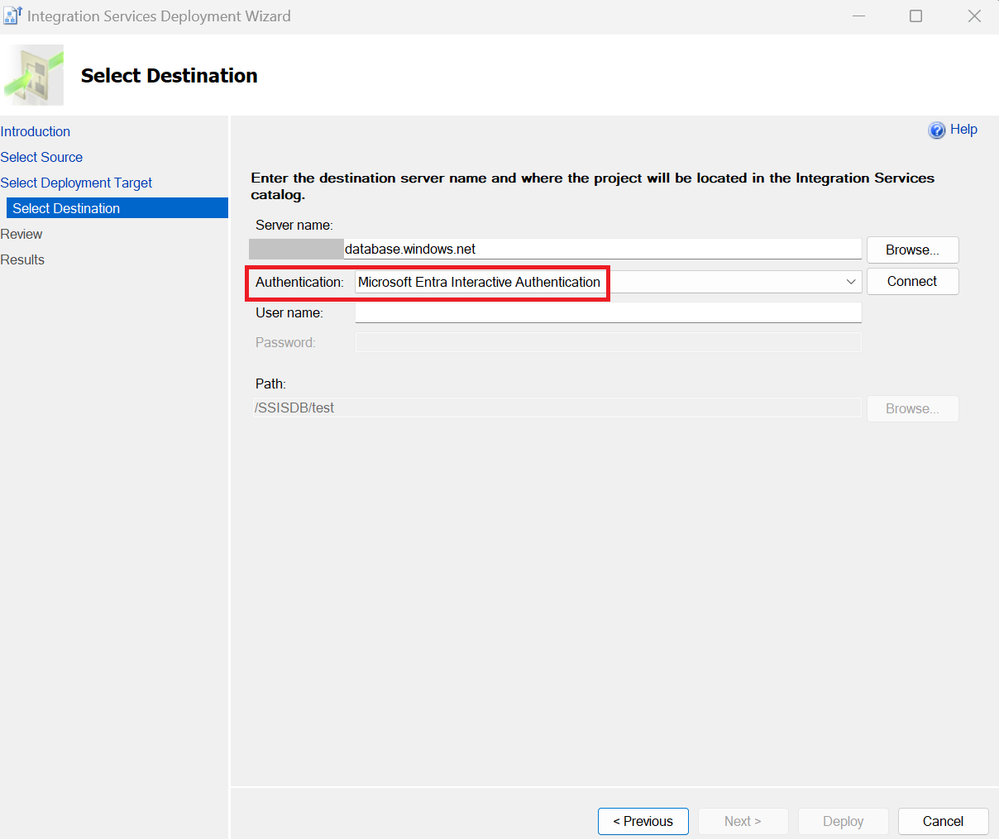
2,880

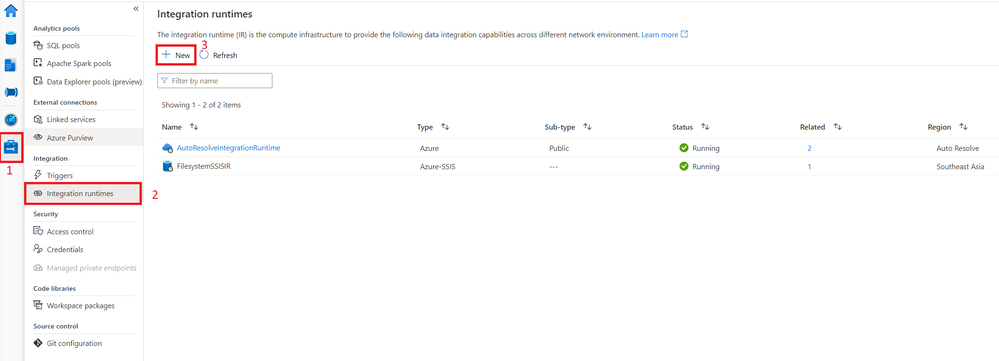
8,102

6,709
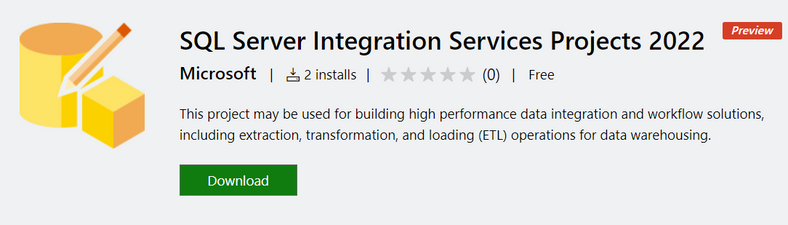

15.4K

10.4K
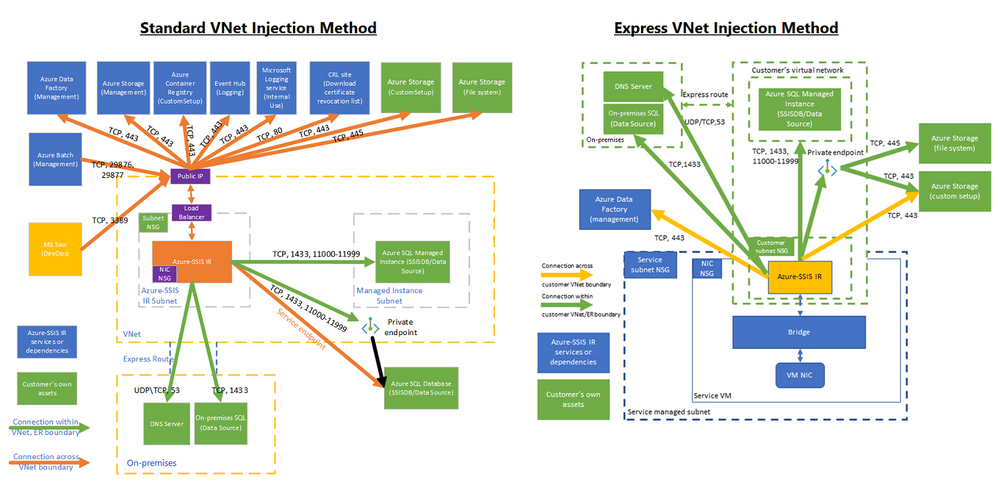
8,706
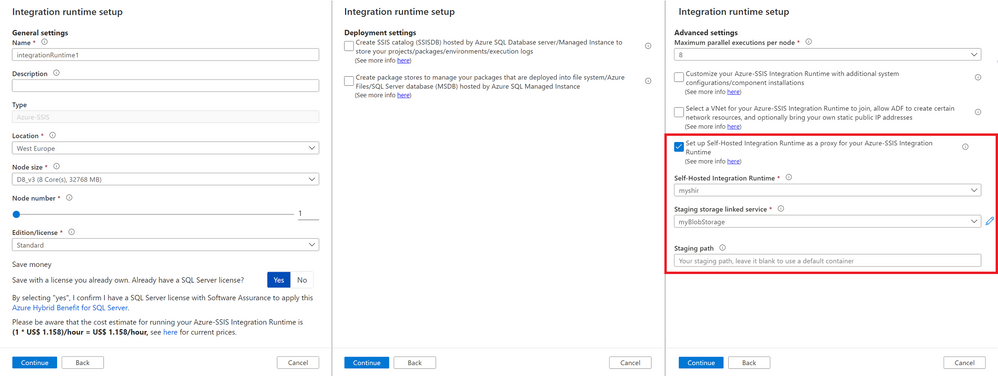
11.6K
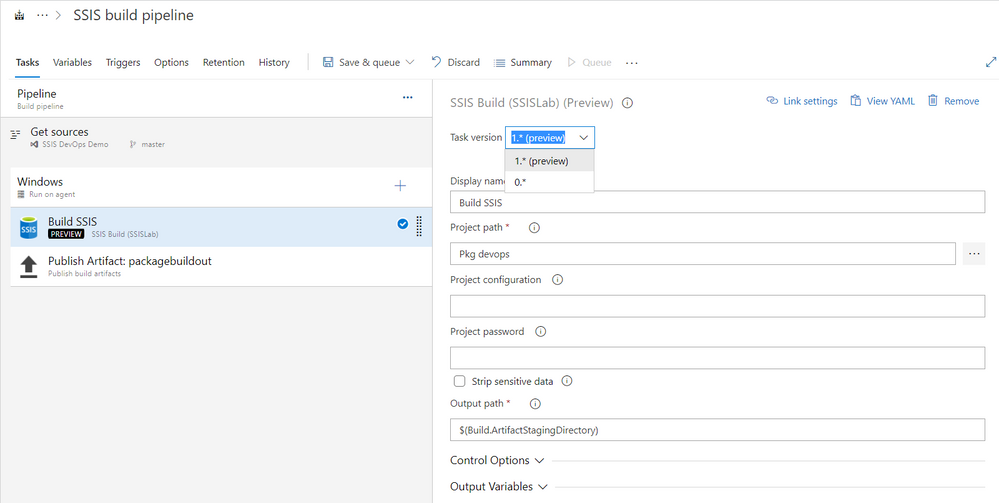

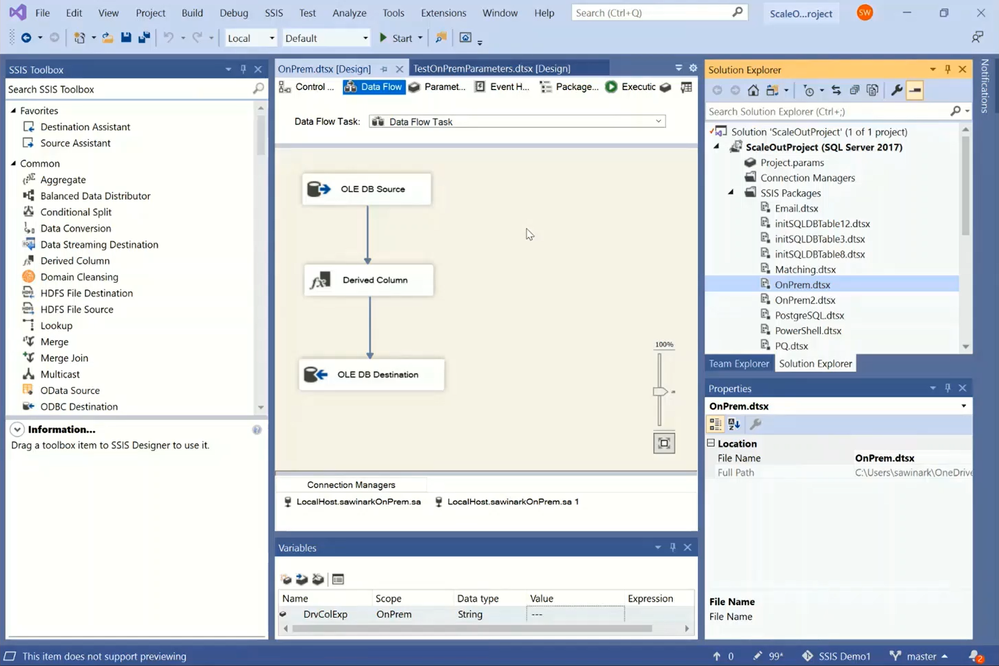
11.8K
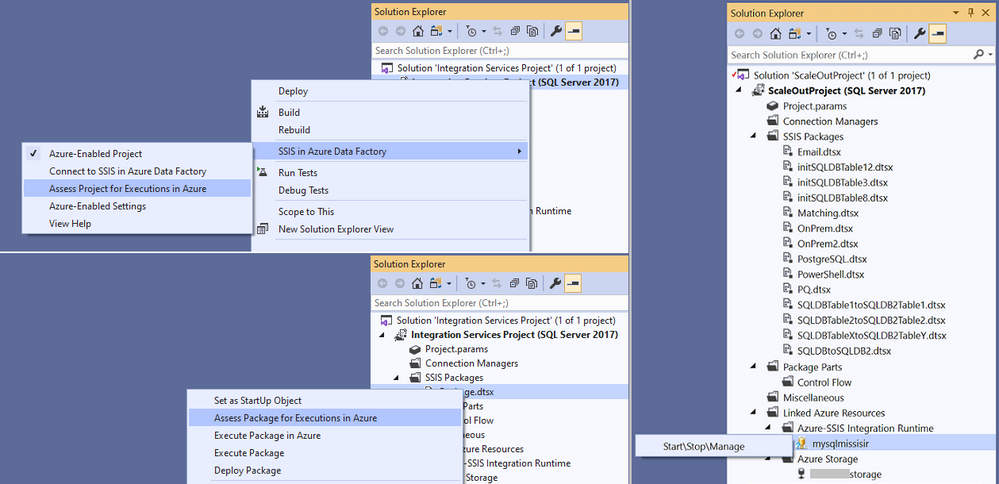
10.8K
10.1K


7,599
6,104

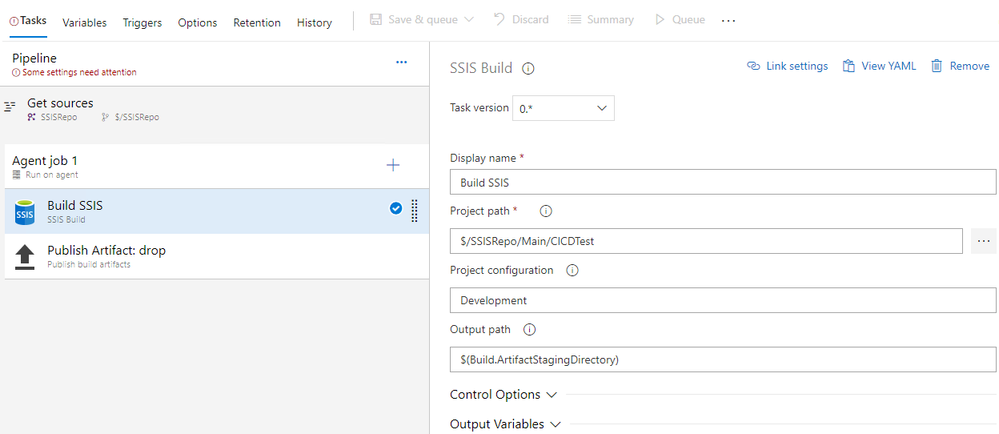
8,140
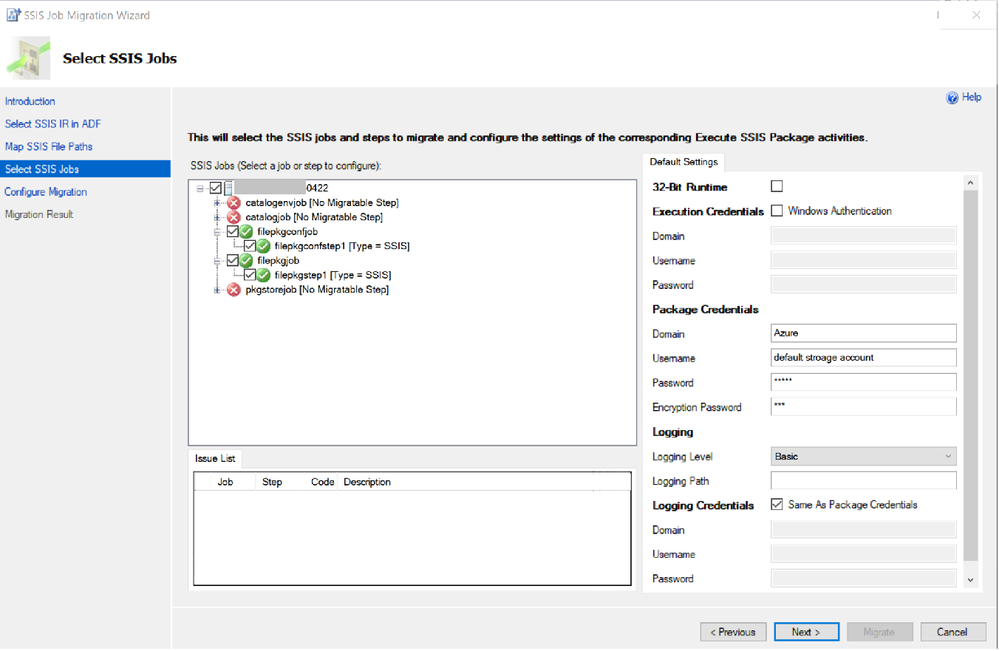
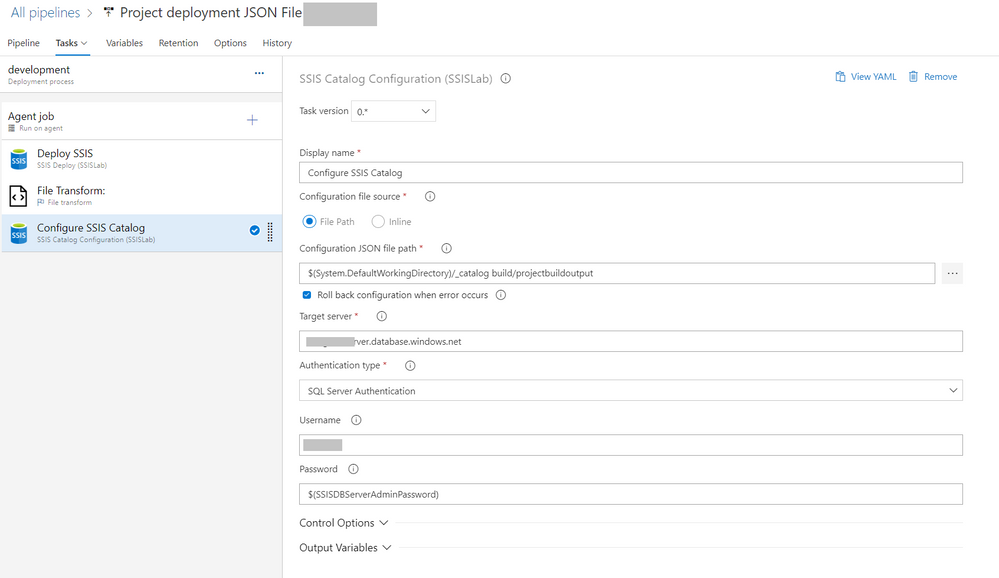
7,997
5,971
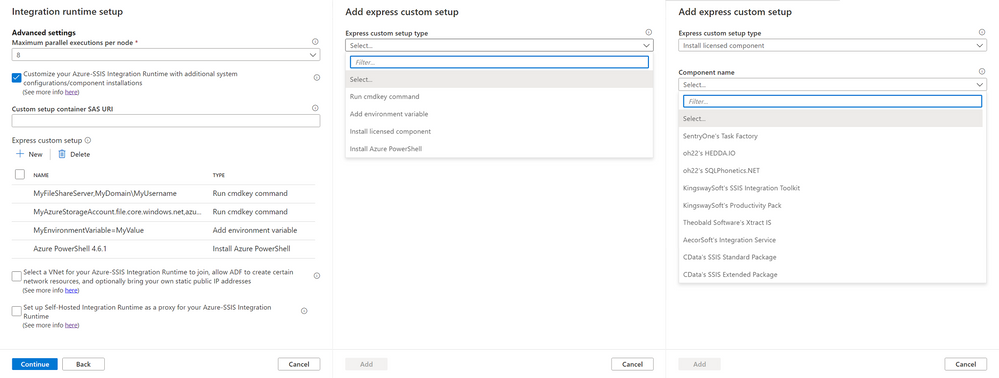
9,248

19.6K
16K
8,638
Latest Comments