Endpoint Load Balancing Heath Probe Configuration Details
Azure load balanced endpoints enable a port to be configured on multiple role instances or virtual machines in the same hosted service. The Azure platform has the ability to add and remove role instances based upon the instance health to achieve high availability of the load balanced endpoint (VIP and port combination).
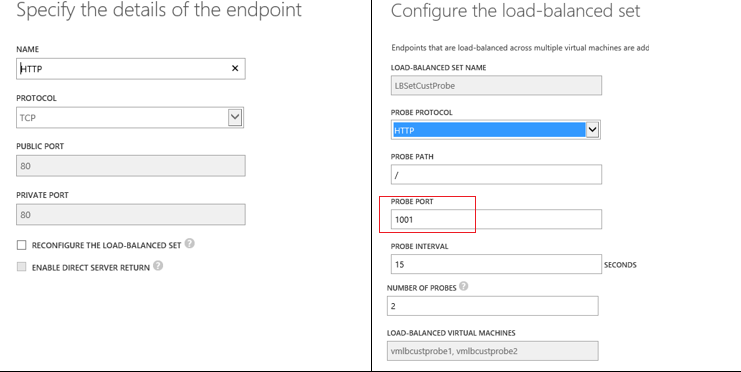
Customers can configure a probe to perform health detection on of a particular instance by probing a specified port. There are two types of probes: TCP and HTTP.
Example configuring probe via the portal:
Configuring a probe via PowerShell example:
PS C:\> Set-AzureLoadBalancedEndpoint -ServiceName "ContosoService" -LBSetName "LBSet01" -Protocol "TCP" -LocalPort 80 -ProbeProtocolTCP -ProbePort 8080 -ProbeIntervalInSeconds 40 -ProbeTimeoutInSeconds 80
Example via csdef (Paas): LoadBalancerProbes
The number of successful / failed probes required to mark an instance up or down is calculated for the user. This is SuccessFailCount value is equal to the timeout divided by probe frequency. For portal, the timeout is set to two times the value of frequency (timeout = frequency * 2).
HTTP based probes perform an HTTP GET request against the specified (relative) URL. The probe marks the role instance down when:
- The HTTP application returns a HTTP response code other than 200 (i.e. 403, 404, 500, etc.). This is considered a positive acknowledgment that the application instance wants to be taken out of service right away.
- In the event the HTTP server does not respond at all after the timeout period. Note that depending on the timeout value set, this might mean multiple probe requests go unanswered before marking probe as down (i.e. SuccessFailCount probes are sent).
- When the server closes the connection via a TCP reset.
TCP based probes initiate a connection by performing a three way handshake. TCP based probes mark the role instance down when:
- In the event the TCP server does not respond at all after the timeout period. Note that depending on timeout value set, this might mean multiple probe requests go unanswered before marking probe as down (i.e. SuccessFailCount probes are sent).
- A TCP reset is received from the role instance.
TCP and HTTP probes are considered healthy and mark the role instance as UP when:
- Upon the first time the VM boots and the LB gets a positive probe
- The number of successful probes meets the threshold required by the number SuccessFailCount (see above) to mark the role instance as healthy. If a role instance was removed, SuccessFailCount in a row successful probes are required to mark role instance as UP.
If the health of a role instance is fluctuating, the Azure Load balancer is waits longer before putting the role instance back in the healthy state. This is done via policy to protect the user and the infrastructure.
Additionally, the probe configuration of all load balanced instances for an endpoint (load balanced set) must be the same. This means you cannot have a different probe configuration (i.e. local port, timeout, etc.) for each role instance or virtual machine in the same hosted service for a particular endpoint combination.