Specifiche di base : XML Canonicalization in pillole
Iniziamo col dire cosa significa "Canonicalizzazione". La traduzione di Canonicalization, canonicalizzazione, significa rendere in forma canonica, normale. Quindi Canonicalizzazione = Normalizzazione (che è italiano :-)!
La specifica XML C14N è fondamentale per tutte le operazioni di crittografia nel mondo XML e Web Services (e non solo). E' una specifica del 2001 ovvero possiamo considerarla "matura" nel giovane mondo XML! Capiamo perchè XML C14N è così importante e cosa dice a grandi linee maaaa.... prima di iniziare con i contenuti seri una piccola curiosità:
Questa specifica viene spesso chiamata [XML C14N] perchè sono 14 lettere tra la C e la N di Canonicalization :-) ... svelato il mistero....
Adesso torniamo seri...
Le specifiche di XML Canonicalization si occupano della normalizzazione delle informazioni in una forma universalmente riconosciuta. Queste due specifiche(Canonical XML 1.0 del 15 Marzo 2001 e Exclusive XML Canonicalization 1.0 del 18 Luglio 2002) nascono per risolvere il problema della rappresentazione dello stesso XML Infoset (XML data model astratto – Ver. https://www.w3.org/TR/2001/REC-xml-infoset-20011024 del 24 Ottobre 2001) in formati sintattici e contesti diversi. Si considerino le seguenti rappresentazioni XML :
<persona nome=’Mario’ eta=”35”/>
<persona eta=’35’ nome=’Mario’/>
<persona nome=’Mario’ eta=’35’></persona>
Questa libertà di rappresentare lo stesso XML Infoset è intrinseca nella serializzazione di XML 1.0 e pone dei problemi in alcune operazioni di crittografia come ad esempio la firma digitale. In figura 1, ad esempio, un’unica informazione viene espressa in tre forme diverse e durante l’operazione di encoding in byte streams (octets) si ottengono tre valori diversi che producono ovviamente tre firme digitali diverse. Infatti la firma digitale avviene tramite l’encryption con la chiave privata dell’hash dei dati da firmare! Poiché le tre rappresentazioni producono tre hash diversi di conseguenza si ottengono tre firme diverse. Perché questo è un problema? Il problema nasce quando un programma vuole verificare una firma digitale rispetto al XML Infoset. Senza un processo di normalizzazione condiviso nel caso precedente avremmo 1/3 delle probabilità che l'operazione di firma dia esito positivo!
Questo aspetto è molto importante perchè la logica applicativa lavora molto spesso a livello di Infoset XML e non sulla singola rappresentazione creando problemi in fase di verifica delle informazioni crittografiche .
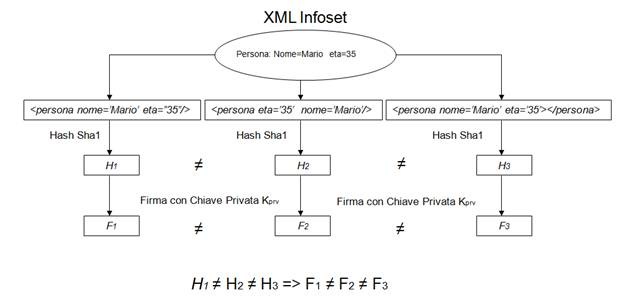
Figura 1
Inoltre durante il trasferimento dei dati, come ad esempio nelle operazioni di Orchestration, le rappresentazioni possono cambiare e subire trasformazioni dettate dalle regole sintattiche di altre specifiche come SOAP.
Anche la stessa natura del formato testo pone dei problemi di “compatibilità”. Alcuni esempi possono essere la diversa rappresentazione degli spazi alla fine delle righe, le tabulazioni, i caratteri di fine riga. Queste incongruenze devono quindi essere risolte prima di passare i dati in formato testo alle funzioni di crittografia. A questo proposito sono state create due specifiche: la prima, Canonical XML 1.0 [XML-C14N], chiamata anche Inclusive, descrive le regole di normalizzazione di un documento XML in byte stream. Queste regole prevedono che tutti gli attributi vengano dichiarati con i doppi apici, l’encoding debba essere in UTF-8, i tag debbano essere espressi nella forma estesa e gli attributi e i namespaces siano rappresentati in ordine alfabetico. Per una completa visione di queste regole si faccia riferimento alla specifica Canonical XML 1.0 e Exclusive XML Canonicalization 1.0 .
Applicando la funzione di Canonical XML 1.0 all’esempio precedente avremo il seguente output:
<persona eta=”35” nome=”Mario”></persona>
che genererà sempre la stessa firma digitale permettendo quindi l’operazione di verifica (Figura 2).
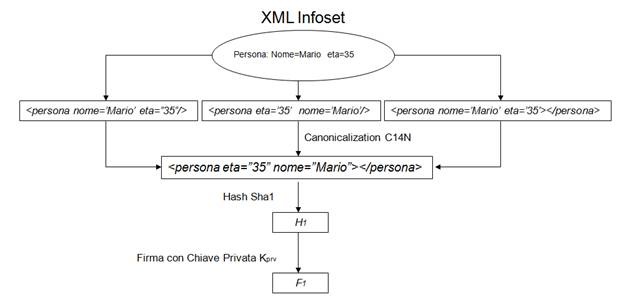
Figura 2
I limiti di questa specifica si evidenziano quando porzioni di documenti XML vengono spostati o copiati da un documento all’altro. Infatti la specifica prevede l’inserimento di alcune informazioni, come ad esempio le dichiarazioni dei namespaces appartenenti al messaggio XML originario nello stesso sottodocumento estratto, causando un cambiamento nella rappresentazione sintattica del documento stesso. Si è resa quindi necessaria una seconda specifica, Exclusive XML Canonicalization 1.0, che permettesse di escludere le informazioni di contesto dalla parte del sottodocumento passato alla funzione di normalizzazione. Questa situazione è comune soprattutto nel mondo dei Web Services quando un documento XML viene firmato ed estrapolato da un contesto applicativo per essere inserito in un SOAP:Envelope per la trasmissione. Nella fase di verifica il documento XML viene estratto dal SOAP:Envelope e verificato. Ad esempio nel firmare digitalmente la seguente porzione di documento XML che chiamiamo XML1
<ns1:info xmlns:ns1="https://application">
<ns1:persona eta="35" nome="Mario"></ns1:persona>
</ns1:info>
otteniamo la firma F1. Successivamente ipotizziamo di inserire XML1 all’interno di un altro elemento e chiamiamo XML2 il nuovo documento
<ns0:app xmlns:ns0="https://transmission">
<ns1:info xmlns:ns1="https://application">
<ns1:persona eta="35" nome="Mario"></ns1:persona>
</ns1:info>
</ns0:app>
Nella operazione di verifica della firma F1 è necessario estrarre XML1 da XML2.
Questa operazione può essere effettuata con la creazione di un node-set XPath passato poi alla funzione di normalizzazione ottenendo il seguente risultato XML3:
<ns1:info xmlns:ns0=”https://transmission” xmlns:ns1="https://application">
<ns1:persona eta="35" nome="Mario"></ns1:persona>
</ns1:info>
Come si può notare XML3 è diverso da XML1.in quanto sono presenti alcune informazioni di contesto di XML2 che genereranno un errore in fase di verifica della firma digitale F1.
Exclusive XML Canonicalization 1.0, che non inserisce le informazioni di contesto, permette di riottenere esattamente XML1 e quindi di avere una corretta operazione di verifica.
Questa è una versione un po' aggiornata di un articolo che ho scritto nel 2003 per Visual Basic Journal...
--Mario