Threat Modeling Again, Threat modeling and the fIrefoxurl issue.
Yesterday I presented my version of the diagrams for Firefox's command line handler and the IE/URLMON's URL handler. To refresh, here they are again:
Here's my version of Firefox's diagram:
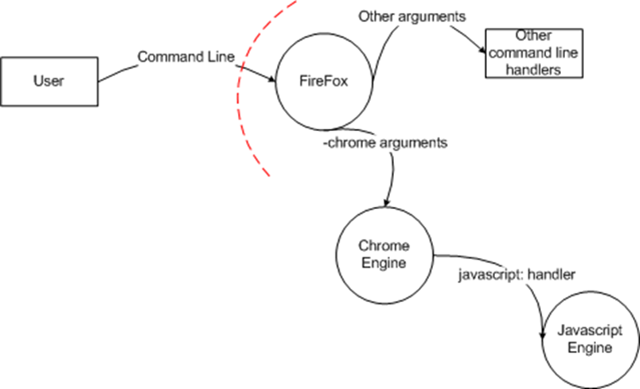
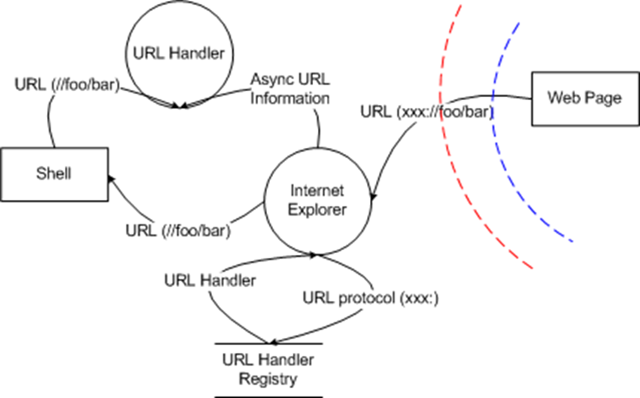
And my version of IE/URLMON's URL handler diagram:
As I mentioned yesterday, even though there's a trust boundary between the user and Firefox, my interpretation of the original design for the Firefox command line parsing says that this is an acceptable risk[1], since there is nothing that the user can specify via the chrome engine that they can't do from the command line. In the threat model for the Firefox command line parsing, this assumption should be called out, since it's important.
Now let's think about what happens when you add in the firefoxurl URL handler to the mix?
For that, you need to go to the IE/URLMON diagram. There's a clear trust boundary between the web page and IE/URLMON. That trust boundary applies to all of the data passed in via the URL, and all of the data should be considered "tainted". If your URL handler is registered using the "shell" key, then IE passes the URL to the shell, which launches the program listed in the "command" verb replacing the %1 value in the command verb with the URL specified (see this for more info)[2]. If, on the other hand, you've registered an asynchronous protocol handler, then IE/URLMON will instantiate your COM object and will give you the ability to validate the incoming URL and to change how IE/URLMON treats the URL. Jesper discusses this in his post "Blocking the FIrefox".
The key thing to consider is that if you use the "shell" registration mechanism (which is significantly easier than using the asynchronous protocol handler mechanism), IE/URLMON is going to pass that tainted data to your application on the command line.
Since the firefoxurl URL handler used the "shell" registration mechanism, it means that the URL from the internet is going to be passed to Firefox's command line handler. But this violates the assumption that the Firefox command line handler made - they assume that their command line was authored with the same level of trust as the user invoking firefox. And that's a problem, because now you have a mechanism for any internet site to execute code on the browser client with the privileges of the user.
How would a complete threat model have shown that there was an issue? The Firefox command line threat model showed that there was a potential issue, and the threat analysis of that potential issue showed that the threat was an accepted risk.
When the firefoxurl feature was added, the threat model analysis of that feature should have looked similar to the IE/URLMON threat model I called out above - IE/URLMON took the URL from the internet, passed it through the shell and handed it to Firefox (URL Handler above).
So how would threat modeling have helped to find the bug?
There are two possible things that could have happened next. When the firefoxurl handler team[3] analyzed their threat model, they would have realized that they were passing high risk data (all data from the internet should be treated as untrusted) to the command line of the Firefox application. That should have immediately raised red flags because of the risk associated with the data.
At this point in their analysis, the foxurl handler team needed to confirm that their behavior was safe, which they could do either by asking someone on the Firefox command line handling team or by consulting the Firefox command line handling threat model (or both). At that point, they would have discovered the important assumption I mentioned above, and they would have realized that they had a problem that needed to be mitigated (the actual form of the mitigation doesn't matter - I believe that the Firefox command line handling team removed their assumption, but I honestly don't know (and it doesn't matter for the purposes of this discussion)).
As I mentioned in my previous post, I love this example because it dramatically shows how threat modeling can help solve real world security issues.
I don't believe that anything in my analysis above is contrived - the issues I called out above directly follow from the threat modeling process I've outlined in the earlier posts.
I've been involved in the threat modeling process here at Microsoft for quite some time now, and I've seen the threat model analysis process find this kind of issue again and again. The threat model either exposes areas where a team needs to be concerned about their inputs or it forces teams to ask questions about their assumptions, which in turn exposes potential issues like this one (or confirms that in fact there is no issue that needs to be mitigated).
Next: Threat Modeling Rules of thumb.
[1] Obviously, I'm not a contributor to Firefox and as such any and all of my comments about Firefox's design and architecture are at best informed guesses. I'd love it if someone who works on Firefox or has contributed to the security analysis of Firefox would correct any mistakes I'm making here.
[2] Apparently IE/URLMON doesn't URLEncode the string that it hands to the URL handler - I don't know why it does that (probably for compatibility reasons), but that isn't actually relevant to this discussion (especially since all versions of Firefox before 2.0.0.6, seem to have had the same behavior as IE). Even if IE had URL encoded the URL before handing it to the handler, Firefox is still being handed untrusted input which violates a critical assumption made by the Firefox command line handler developers.
[3] Btw, I'm using the term "team" loosely. It's entirely possible that the same one individual did both the Firefox command line handling work AND the firefoxurl protocol handler - it doesn't actually matter.