Threat Modeling Again, Threat Modeling in Practice
I've been writing a LOT about threat modeling recently but one of the things I haven't talked about is the practical value of the threat modeling process.
Here at Microsoft, we've totally drunk the threat modeling cool-aid. One of Adam Shostak's papers on threat modeling has the following quote from Michael Howard:
"If we had our hands tied behind our backs (we don't) and could do only one thing to improve software security... we would do threat modeling every day of the week."
I want to talk about a real-world example of a security problem where threat modeling would have hopefully avoided a potential problem.
I happen to love this problem, because it does a really good job of showing how the evolution of complicated systems can introduce unexpected security problems. The particular issue I'm talking about is known as CVE-2007-3670. I seriously recommend people go to the CVE site and read the references to the problem, they provide a excellent background on the problem.
CVE-2007-3670 describes a vulnerability in the Mozilla Firefox browser that uses Internet Explorer as an exploit vector. There's been a TON written about this particular issue (see the references on the CVE page for most of the discussion), I don't want to go into the pros and cons of whether or not this is an IE or a FireFox bug. I only want to discuss this particular issue from a threat modeling standpoint.
There are four components involved in this vulnerability, each with their own threat model:
- The Firefox browser.
- Internet Explorer.
- The "firefoxurl:" URI registration.
- The Windows Shell (explorer).
Each of the components in question play a part in the vulnerability. Let's take them in turn.
- The Firefox browser provides a command line argument "-chrome" which allows you to load the chrome specified at a particular location.
- Internet Explorer provides an extensibility mechanism which allows 3rd parties to register specific URI handlers.
- The "firefoxurl:" URL registration, which uses the simplest form of URL handler registration which simply instructs the shell to execute "<firefoxpath>\firefox.exe -url "%1" -requestPending". Apparently this was added to Firefox to allow web site authors to force the user to use Firefox when viewing a link. I believe the "-url" switch (which isn't included in the list of firefox command line arguments above) instructs firefox to treat the contents of %1 as a URL.
- The Windows Shell which passes on the command line to the firefox application.
I'm going to attempt to draw the relevant part of the diagrams for IE and Firefox. These are just my interpretations of what is happening, it's entirely possible that the dataflow is different in real life.
Firefox:
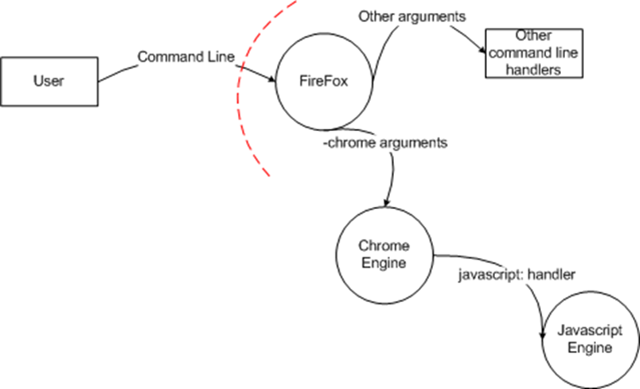
This diagram shows the flow of control from the user into Firefox (remember: I'm JUST diagramming a small part of the actual component diagram). One of the things that makes Firefox's chrome engine so attractive is that it's easy to modify the chrome because the Firefox chrome is simply javascript. Since the javascript being run runs with the same privileges as the current user, this isn't a big deal - there's no opportunity for elevation of privilege there. But there is one important thing to remember here: Firefox has a security assumption that the -chrome command switch is only provided by the user - because it executes javascript with full trust, it's effectively accepts executable code from the command line.
Internet Explorer:
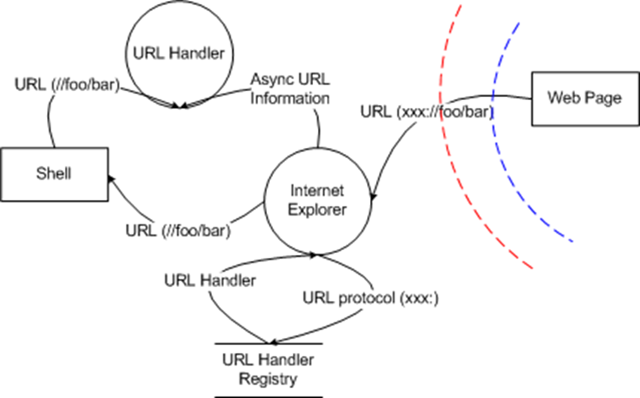
This diagram describes my interpretation of how IE (actually urlmon.dll in this case) handles incoming URLs. It's just my interpretation, based on the information contained here (at a minimum, I suspect it's missing some trust boundaries). The web page hands IE a URL, IE looks the URL up in the registry and retrieves a URL handler. Depending on how the URL handler was registered, IE either invokes the shell on the path portion of the URL, or, if the URL handler was registered as an async protocol hander, it hands the URL to the async protocol handler.
I'm not going to do a diagram for the firefoxurl handler or the shell, since they're either not interesting or are covered in the diagram above - in the firefoxurl handler case, the firefoxurl handler is registered as being handled by the shell. In that case, Internet Explorer will pass the URL into the shell, which will happily pass it onto the URL handler (which, in this case is FireFox).
That's a lot of text and pictures, tomorrow I'll discuss what I think went wrong and how using threat modeling could have avoided the issue. I also want to look at BOTH of the threat models and see what they indicate.
Obviously, the contents of this post are my own opinion and in no way reflect the opinions of Microsoft.