Threat Modeling Again, STRIDE per Element
As I mentioned the other day, we had three huge big realizations as we've been doing more and more threat models. The first (which we've known all along) was that threats are permanent - the threats that apply to the elements of your component don't change over time (assuming that your diagram is accurate and that the design doesn't change[1]). The second (again, which we've known all along) is that threats can be categorized according to each of the 6 STRIDE categories and that there are standard mitigations that can be applied for each of the STRIDE elements. The final piece of the puzzle was that for each type of element, there is a limited set of STRIDE categories that apply to that element.
When you put those pieces together, it turns out that you can build a modeling process based on your diagram (remember diagrams? I started out this series talking about them - there was a reason for it :))
Since each element in your diagram has a series of threats that apply to it, you can build your threat model simply by thinking about how each threat applies. That means that every dataflow in your document, has Tampering, Information Disclosure, and Denial of Service threats. It's entirely possible that you don't actually care about those threats, but they ARE at risk to those threats.
We call this process of considering the threats to each element in the DFD "STRIDE-per-Element" (it's not the most original name, but it IS concise and highly descriptive).
The way that STRIDE-per-element shines (and why it's been so effective here at Microsoft) is that it's a flexible paradigm.
A group can use STRIDE/element as a framework that can lead you to consider threats that you hadn't considered before, they can use STRIDE/element as a way of guiding a brainstorming session, or they can use STRIDE/element as a way of thinking about which mitigations might be appropriate for the various threats that their elements face. The STRIDE/element methodology allows for all of these.
And the best part about it (as far as I'm concerned) is that STRIDE/element allows people to produce competent threat models with relatively little training. Which, as I mentioned at the beginning of the series is important. At Microsoft, every person on the development team participates in the threat modeling process, because they understand their feature better than anyone else does.
The STRIDE/element methodology ends up creating a fair number of threats, even a component with a relatively tiny diagram like:
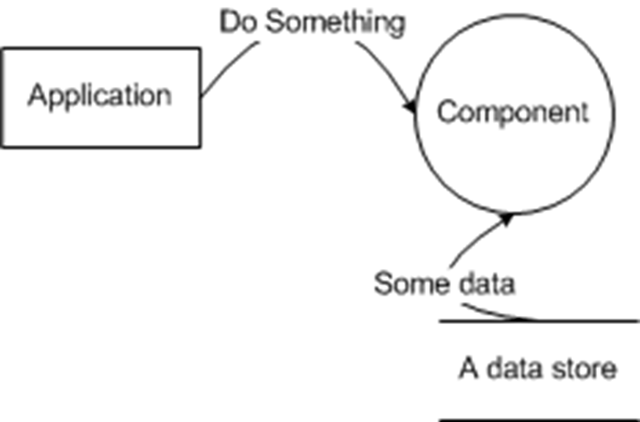
has at least 18 different threats according to the STRIDE/element methodology. The good news is that many/most of those threats aren't meaningful threats - for example, if "Component" in the example above is an API, the "spoofing" threat against "Application" isn't particularly meaningful - you don't care WHO calls your API, one caller is as good as another. On the other hand, if "Do Something" involved communicating data over the network, you probably DO care about the T, I and D threats associated with that data flow. It's the analysis of each threat that lets you know how to handle that.
This analysis is the core of the threat model, and where the real work associated with the process takes place (and where the value of the process shows up). The analysis of the threats associated with your component let you know (a) how you need to change the component to prevent against various classes of attacks and (b) what your test team needs to do to ensure that your mitigations are in place and are correct.
Next: Let's start building the PlaySound threat model!
[1] I'll come back to this particular point a couple of posts from now, it's important.