Microsoft R Server for Hadoop/Spark の実行アーキテクチャー
某工場長と語らう会で7分ぐらいの LT をした際の内容まとめ。
Microsoft R Server の最も特徴的な機能は R スクリプトを多数のスレッド・プロセス・ノードに振り分けて、並列実行することでスループットを上げる機能です。 (ScaleR という機能名がついてます) R を並列実行する機能以外にも、R スクリプトを非常に簡単に HTTP 経由で呼び出して REST API 化する機能もあります。
HDInsight の Hadoop/Spark クラスターは全ノード Ubuntu で構成されてます。

HDInsight の Premium エディションを選択すると Microsoft R Server 構成済みの Spark クラスターが標準で作成できるようになっています。 "R Server on Spark" となっていますが、Spark ジョブ以外に Hadoop の MapReduce ジョブとして実行することもできます。
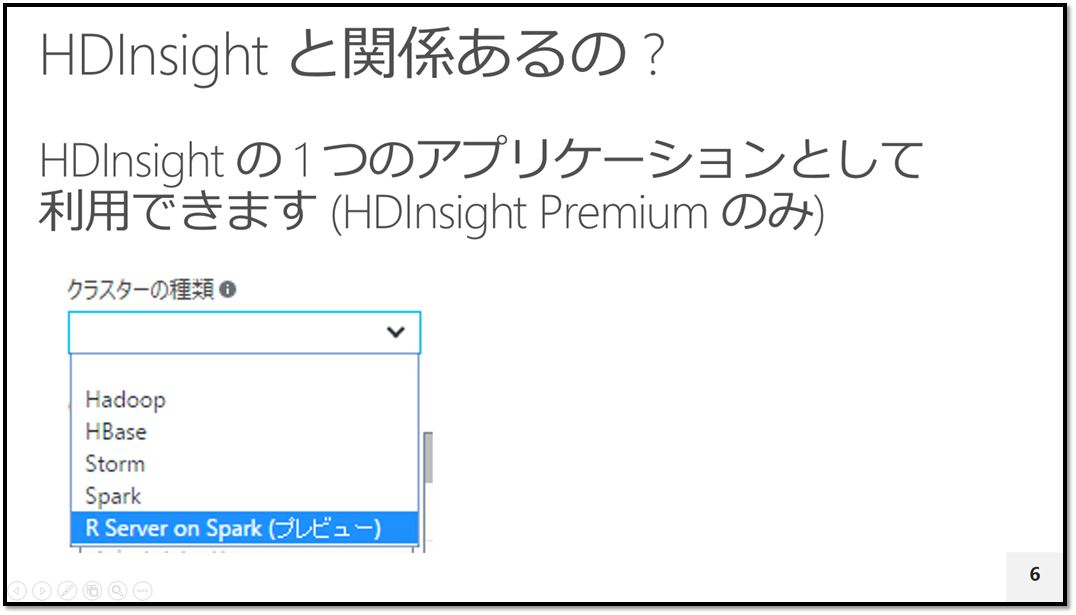
『R スクリプトを書くと、それが MapReduce/Spark ジョブとして HDInsight のワーカーノードに配信されて並列分散実行される』というのが R Server for Spark(Hadoop) の仕組みです。
今思うと、Spark Shell と書いてありますが、実際には Spark のドライバープログラムから実行してます。

R Server を初めて触ったとき、私は てっきり「R スクリプトで書いた内容を Java プログラム もしくは Scala に変換して MapReduce/Spark ジョブを実行している」と思っていました。HDInsight のワーカーノードで動く以上、最終的には Java VM 上で動く必要があるので、R -> Java/Scala へのコンバートしてるのかな?と。
ですが、実際に中身を見てみると違いました。実際には、書いた R スクリプトは加工された後、R スクリプトとして HDInsight のワーカーノードに配信され※1 Java VM 上で動く MapReduce/Scala 内から R ランタイムを fork する形で実行されます。そのため、R Server on Spark を実行するために HDInsight のワーカーノード全てに Microsoft R Server がインストールされています。
LT 中に「どうやって実行してると思います?」と聞いてみたら、某さとうさんから「R 用の Java ランタイムで実行している」という返事を頂いたんですが、よくよく考えてみると、Java VM は JRuby (最近聞かないけど・・) とかあるので、その辺を踏まえての話だったのだな、と※2
※1 配信の仕組みも独自になっており、ワーカーノードに配信される R スクリプトは、MapReduce/Spark ジョブ内で書き出して生成されます。各ノード上で一時ディレクトリをきって、そこに自分自身で R スクリプト書き出して、そして実行するという荒々しい実装です。
※2 言われてみると、R 用 Java インタープリターってのはとても良さそうで、無いのかなと検索してみたら Renjin という JVM ベースの R インタープリターがあるようです。

よく「Microsoft R Server for Hadoop/Spark を使う場合に利用できる R 関数が制限されるのではないか?」ということを聞かれますが、実際には SQL Server (Windows) 向け、Red Hat/SuSE (Linux) 向け、Teradata 向けと実行できる内容に変わりはありません。結局のところ、同じ R のランタイム上で実行しているためです。
というか基本的には R 関数全てを実行できます※。ワーカーノードで R ランタイム上で R のスクリプトを実行しているだけだからです。
※ 外部ライブラリ (.DLL 等) に依存している関数を呼び出すのはちょっと難しいかもしれません。各ワーカーノードにそれらの外部ライブラリが存在しないためです。

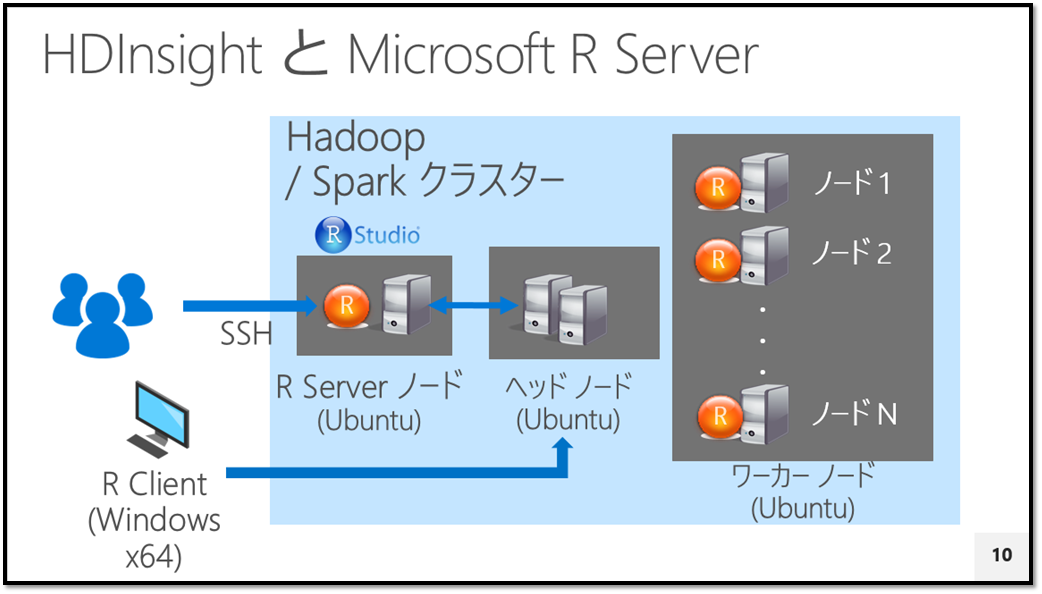
構成図にすると以下図のようになります。HDInsight Premium の R Server on Spark は「2台のヘッドノード」、「1 台以上のワーカーノード」と「1 台のエッジ (R Server) ノード」で構成されます。オレンジ色の "R" マークがあるノードで R Server (ScaleR 機能) が動きます。
最近リリースした「Microsoft R Client」を 64bit Windows にインストールしてクライアントにすることもできます。R Client は無償のソフトウェアで、R Server (ScaleR) のライブラリ呼出しが行えます。
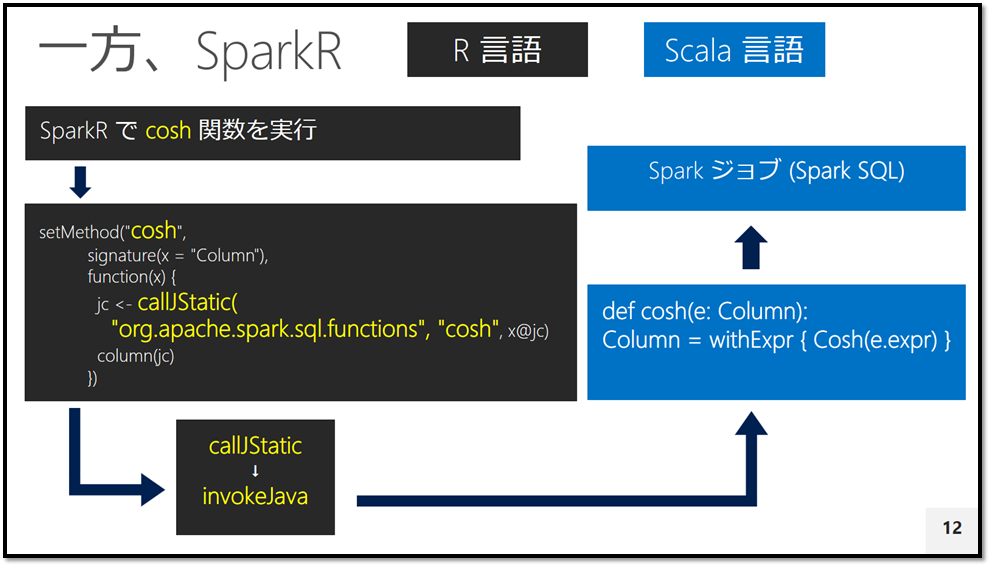
ここからは Microsoft R Server ではなく、比較されがちな Apache Spark の SparkR について。LT のために当日ソースコードを確認してみたのですが、似たようなものを作るにあたっても実装方法やアーキテクチャーの選択はやっぱり違うよね、というのを実感しました。実際、SparkR の GitHub リポジトリを見ると「R」のファイルが並んでおり、どの R ファイルも かなりの大作になっています。

例えば、functions.R には以下のように R 関数ごとに setMethod 関数を実行しており、さらに callJStatic 関数 -> invokeJava 関数を経て SparkSQL の対応する関数を実行する仕組みになっているようです。SparkSQL で実装できるレベルのプリミティブな関数は良いと思うのですが、このアーキテクチャーだと少し内容が難しくなると SparkR で実現するのは難しそうな気がします・・・が、プリミティブな範囲であっても R さえ知っていれば、Apache Spark のジョブが呼び出せる (Spark シェルや pyspark 以外の選択肢) というのは OSS だけで実現したい人には良さそうです。
apache/spark/R/pkg/R/functions.R
setMethod("acos",
signature(x = "Column"),
function(x) {
jc <- callJStatic("org.apache.spark.sql.functions", "acos", x@jc)
column(jc)
})
流れを纏めると以下のような流れのようです。 ※ 30 分ほどコード読んで確認した範囲なので、もし読み間違ってたらご教示を・・
ということでまとめとしては、Microsoft R Server はソースコードを公開していないプロプラエタリなソフトウェアですが、Spark 上で R を実行するために Scala で Spark ドライバープログラムを (非常に少なく行数で) 実装するという選択を取り、一方、SparkR はここの呼び出しに対応する大量の R 関数を実装するという選択を取ったことになります。同じなのは R を Spark のインタフェースにしている、という点だけで動きや目的も多少違うので設計が違うのもありだと思うのですが、おもしろいなぁ、と。どちらも一長一短あるので、どちらが良いという話ではないです。
