PIVOT on two or more fields in SQL Server
The PIVOT function in SQL Server is not used very often in projects I work on, but can be extremely useful for specific kinds of pages, especially when consumed in ASP.NET using GridView objects. Some people struggle with PIVOT on one field, the online documentation should be sufficient for that need. Here is an example of pivoting on two fields for the SQL community. Having a need to show multiple properties for an entity is a good case for such.
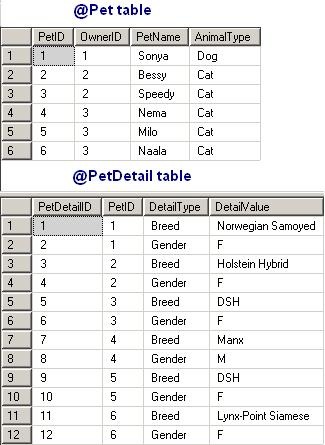
To demonstrate this technique, I will create some contrived data, and show pivoting on it. Note that you must pivot on an aggregate function, which may or may not be relevant, such as the case where you want to pivot on a text field. We will use a table of pets with their owners, and another table containing properties of the pets, and show a report for properties of them, such as name, breed and gender. To make this demo even more contrived, we will assume no more than 3 pets per owner (I'm demonstrating the technique, you need to fit it into your requirements).
Below is a script to create two relational tables, Pet and PetDetail. Note, the database schema would likely need a more generic animal table if this were a real application, and we would display the owner names, not their ID's. It may seem obvious that the data model should be optimized, but remember this is a demo of a SQL skill, it is not a demo for data modelling. The insert statements use a syntax new to SQL Server 2008.
The data in the @Pet table has records representing distinct Pets. This has a one to many relationship to the @PetDetail table. Further complicating this is the fields DetailType and DetailValue are effectively key / value pairs. Thus, we have a model with a parent record having multiple key / value pairs. For our report, we only care about data pertaining to the Gender and Breed keys (DetailType).
SQL 2008 -Data Creation - Pivot Demo
--SQL to create tables and insert data here...
DECLARE @Pet Table
(
PetID INT
, OwnerID INT --FK to fictitious PetOwner table
, PetName NVARCHAR(50)
, AnimalType NVARCHAR(10)
)
DECLARE @PetDetail Table
(
PetDetailID INT
, PetID INT -- FK to @Pet table
, DetailType NVARCHAR(50)
, DetailValue NVARCHAR(50)
)
INSERT INTO @Pet(PetID, OwnerID, PetName, AnimalType) VALUES
(1, 1, 'Sonya', 'Dog')
, (2, 2, 'Bessy', 'Cat')
, (3, 2, 'Speedy', 'Cat')
, (4, 3, 'Nema', 'Cat')
, (5, 3, 'Milo', 'Cat')
, (6, 3, 'Naala', 'Cat')
INSERT INTO @PetDetail(PetDetailID, PetID, DetailType, DetailValue) VALUES
(1, 1, 'Breed', 'Norwegian Samoyed')
, (2, 1, 'Gender', 'F')
, (3, 2, 'Breed', 'Holstein Hybrid')
, (4, 2, 'Gender', 'F')
, (5, 3, 'Breed', 'DSH')
, (6, 3, 'Gender', 'F')
, (7, 4, 'Breed', 'Manx')
, (8, 4, 'Gender', 'M')
, (9, 5, 'Breed', 'DSH')
, (10, 5, 'Gender', 'F')
, (11, 6, 'Breed', 'Lynx-Point Siamese')
, (12, 6, 'Gender', 'F')
SELECT PetID, OwnerID, PetName, AnimalType FROM @Pet ORDER BY PetID
SELECT PetDetailID, PetID, DetailType, DetailValue FROM @PetDetail ORDER BY PetDetailID
This data may be easier to visualize graphically as below:
Note: The remaining queries below assume data generated as per the insert statements above.
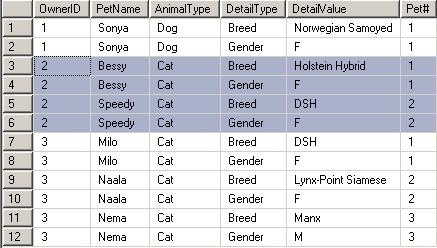
A typical query would give accurate data as below, however would lead to multiple records per pet owner. This would require looping or other logic in the front end to translate to a nice report of each owner and their pets. To gain a better understanding of Ranking Functions , experiment with the RANK function as in the commented out code below, and compare to the DENSE_RANK function. This will show why this report requires the DENSE_RANK function in order to be usable by the PIVOT function in the subsequent example.
SQL 2008 -Simple Joins - Pivot Demo
--Simple Join SQL HERE...
SELECT p.OwnerID, p.PetName, p.AnimalType
, pd.DetailType, pd.DetailValue
,DENSE_RANK() OVER (PARTITION BY p.OwnerID ORDER BY p.PetName ASC) AS [Pet#]
--,RANK() OVER (PARTITION BY p.OwnerID ORDER BY p.PetName ASC) AS [Pet# by RANK]
FROM @Pet p
INNER JOIN @PetDetail pd ON p.PetID = pd.PetID
ORDER BY p.OwnerID, p.PetName, pd.DetailType
Now, on to the report using the PIVOT function. To understand what's going on, the DENSE_RANK function affords us the ability to distinguish key fields sequentially so that we can pivot on them using predictable names. The predictable names will be the key name plus 1, 2, or 3.
Observe how there are two pivots in this query. The first one pivots from the concatenation of the key name as described above. This is necessary so we can differentiate the data belonging to that key. However, the second pivot is at a higher level, for the distinct pet. Since we don't need to distinguish one value from the other, because the PetName will be the same for each record, we simply generate a pivot based on an arbitrary string value concatenated with the DENSE_RANK value.
Also observe the use of the GROUP clause. Here, I want to group by the OwnerID to create a unique record by owner, however the PetName field is removed from the grouping because we are pivoting on it. For further explanation of the PIVOT function, see the online documentation at https://msdn.microsoft.com/en-us/library/ms177410(SQL.90).aspx
SQL 2008 -PIVOT Function - Pivot Demo
--PIVOT QUERY HERE...
SELECT
OwnerID
, AnimalType
, Pet1Name = MAX([PetName1])
, Pet1Gender = MAX([Gender1])
, Pet1Breed = MAX([Breed1])
, Pet2Name = MAX([PetName2])
, Pet2Gender = MAX([Gender2])
, Pet2Breed = MAX([Breed2])
, Pet3Name = MAX([PetName3])
, Pet3Gender = MAX([Gender3])
, Pet3Breed = MAX([Breed3])
FROM (
SELECT
p.OwnerID
, p.PetName
, p.AnimalType
, pd.DetailType
, pd.DetailValue
,pd.DetailType + CAST(DENSE_RANK() OVER (PARTITION BY p.OwnerID ORDER BY p.PetName ASC) AS NVARCHAR) AS [PetNumber]
,'PetName' + CAST(DENSE_RANK() OVER (PARTITION BY p.OwnerID ORDER BY p.PetName ASC) AS NVARCHAR) AS [PetNamePivot]
FROM @Pet p
INNER JOIN @PetDetail pd ON p.PetID = pd.PetID
) AS query
PIVOT (MAX(DetailValue)
FOR PetNumber IN ([Gender1],[Gender2],[Gender3], [Breed1], [Breed2], [Breed3])) AS Pivot1
PIVOT (MAX(PetName)
FOR PetNamePivot IN ([PetName1],[PetName2],[PetName3])) AS Pivot2
GROUP BY
OwnerID
, AnimalType
ORDER BY OwnerID

Concluding Remarks
The PIVOT function is a powerful tool for transforming data into simplified structures. It may seem difficult at first to grasp what is being pivoted, and how to do so. Hopefully the example above will bring clarity for pivoting on two or more fields. It should be considered whether to transform the data in SQL Server or the client, as there are tradeoffs to each approach. The PIVOT function would likely have a performance impact on the query based on complexity of the pivot and / or the size of the data being transformed. This performance impact may be less than you might imagine if appropriate filters are applied. At any rate, performance testing would be critical, whether you use the PIVOT function or implement equivalent functionality in the business layer. A well constructed PIVOT statement could lessen the chances of downstream bugs, as the code required to pivot outside of SQL could be very complex, especially if NULLs are allowed in the key fields.
However, this potential for performance impact could be offset by simplifying the code and processing at the client layer, as doing such a transformation in your favorite programming language could be very complex and have just as much of a performance impact. By pivoting in the SQL layer, databinding to a GridView object can be done very straightforward, whereas the alternative would require transformations in the code prior to the databinding event, or hijack the onrowdatabound or other events to do secondary processing.
Regardless of the approach taken for PIVOT, whether it be in SQL Server or programmatically in a .NET language, testing is critical. Be sure to do performance testing as well as accuracy of results, and to do so with a wide range of data to ensure the system can handle real data.