デッドロックを避けるコツ
神谷 雅紀
SQL Server Escalation Engineer
まずは、デッドロックとは?から
デッドロック (deadlock) とブロッキング (blocking) は異なる事象です。
デッドロックは、リソース獲得において、A が B を待たせ、かつ、B が A を待たせている状態です。例えば、トランザクション 1 がある行に排他ロックを獲得している状態でトランザクション 2 がその行に共有ロックを獲得しようとします。この時点では、トランザクション 1 がトランザクション 2 を待たせているだけであるため、発生している事象は、デッドロックではなくブロッキングと呼ばれる事象です。この状態から、トランザクション 1 が別の行に共有ロックを獲得しようとし、その行にトランザクション 2 が排他ロックを持っていると、デッドロックと呼ばれる事象が発生します。このデッドロックはサイクルデッドロック (cycle deadlock) と呼ばれます。
デッドロックは、お互いがお互いを待っている状況であるため、第三者が介在しない限り、その状況から脱することはありません。SQL Server では、Deadlock Monitor が第三者となり、この状況を検出し、解消する役割を担っています。
デッドロックは、複数のブロッキングから構成され、第 3 者が介在しない限り、継続します。
ブロッキングは、ロックを保持しているトランザクションが終了することでロックが解放されれば、第 3 者の介入がなくても自然解消します。
ロックはどこに獲得されるのか?
ロックは、クエリの最終結果に含まれる行やキーだけに獲得される訳ではありません。
クエリ結果を得るためには、クエリの最終結果に含まれる行以外の行へのアクセスも発生することが多々あり、そのような場合には、クエリの最終結果に含まれる行以外の行にもロックは獲得されます。
例えば、更新行を絞り込むために有効なインデックスがない場合、更新対象となる行かどうかを判断するためには、その行を一度読み取り、更新対象かどうか確認するという処理が必要になります。この確認を実施中に他のトランザクションにその行を更新されると、一貫性のある状態が保てなくなるため、この確認のための読み取り時にもロックは獲得されます。
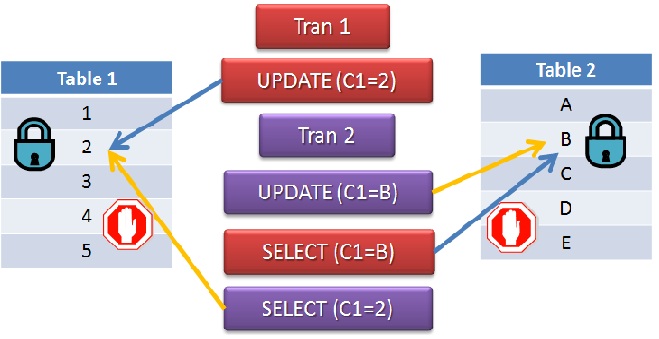
以下の例では、対象行は C1 = 2 の行のみですが、ロックはすべての行に獲得されます。

ロックは、その行が対象行かどうかを評価する時にも獲得されます。
デッドロックを避けるには?
ロックを獲得する範囲は最小に、ロックを保持する期間は最短に。
アクセス順を一定に保つというのは、あまりにも一般的に言われることですので、ここでは議論しません。
上で説明したように、デッドロックは複数のブロッキングから構成される事象です。ブロッキングの可能性を減らせば、デッドロックの可能性も低くなります。そのためには、クエリの最終結果を得るために必要最小限のデータのみにアクセスするようにします。これが非常に重要です。
必要最小限のデータのみにアクセスするようにすることで、ロックを獲得する範囲を最小にすることができます。また、アクセスするデータ量が少なくなることで、クエリの実行時間は短くなり、トランザクションの実行時間も短くなるため、ロックを保持している時間も短くすることができます。
例えば、テーブルの全行にアクセスするクエリは、テーブルの全行に行ロックもしくはキーロックを獲得するか、ページやテーブルなど、より粒度の大きいリソースにロックを獲得します。その結果、他のトランザクションのロックと競合する可能性が高くなります。さらに、多くのデータにアクセスすることで、クエリの実行時間が長くなるため、ロックを保持している時間も長くなります。
このような状況を避けることで、デッドロックの可能性を可能な限り小さくします。
チェックポイント
1. 以下の指針に従っているかどうか
以下のポストは、パフォーマンスを話題の中心としていますが、これらはブロッキングやデッドロックの主要な発生原因でもあります。特に、データ型の不一致は、最もよく見られるブロッキングおよびデッドロックの原因のひとつです。
DO's&DONT's #2: 絶対にやらなければいけないこと - データ型を一致させる
DO's&DONT's #3: やらなければいけないこと - 非典型的パラメータ値が存在する場合の再コンパイル (Atypical Parameter Problem の対応)
DO's&DONT's #4: やらない方がいいこと - クエリの 条件句 (WHERE や JOIN ON 等) で参照されている列の加工
DO's&DONT's #6: 絶対にやってはいけないこと – ストアドプロシージャ内でのパラメータ値の変更
2. Table Scan, Clustered Index Scan, Index Scan が行われていないかどうか
クエリに有効なインデックスが存在せず、テーブル全検索 (Table Scan, Clustered Index Scan) やインデックス全検索 (Index Scan) が行われている場合があります。Index Scan はインデックスを使用していますが、ほとんどの場合、そのインデックスがクエリに有効だからではなく、テーブル全部を検索するよりもインデックスの方がサイズが小さいからテーブル全体を検索するよりはマシ、といった理由で使用されています。
ただし、Scan が必ずしも悪いとは限りません。テーブルのサイズが小さければ、インデックスで範囲を限定して検索するよりも、テーブル全体やインデックス全体を検索した方が効率的な場合もあります。また、テーブルのほとんどの行がクエリ結果に含まれる場合には、インデックスを使用するよりも、テーブル全体を検索した方が効率的な場合があります。
Table Scan, Clustered Index Scan, Index Scan が行われているかどうかは、SQL トレースイベント Showplan Text (Unencoded) で確認できます。
手順
1. 以下の手順に従い、 SQL:StmtStating, SP:StmtStarting, Showplan Text (Unencoded) イベントをトレースします。
SQL トレーススクリプトの作成、実行 (SQL Server 2005, 2008, 2008 R2)
SQL トレーススクリプトの作成、実行 (SQL Server 2000)
2. 採取したトレースファイルを Profiler で開き、Showplan Text (Unencoded) イベントを確認し、Table Scan, Clustered Index Scan, Index Scan がないかどうか確認します。
※ fn_trace_gettable 関数を使用して、トレースファイルを開き、内容を検索することできます。