Using BLOB Storage: Azure Storage and GAE Blobstore
[ Updated Azure Storage Sample Code : the code used for Storage in this post has been scrubbed and updated and posted]
Anyone that has read my recent posts, or posts by many others out there, can see examples how to upload single and multiple files into Azure Storage (Storage). Likewise, there are a number of examples out there for uploading files to GAE Blobstore (Blobstore). However, I haven't seen any posts that discuss both as I have been looking into it myself. So, I thought an entry about the two might be useful. Before we get started, this is a long post; please forgive the length and any odd grammar as I only did a cursory review before posting.
In this post I'm not going to cover every feature or use pattern of either of the blob storage options. Rather, I'm going to go over the mechanics of uploading files and I will point out some specifics about each offering as it makes sense in the context of this post.
The first point of comparison is the API that is available:
· The Blobstore API is available as a set of libraries that can be used via Python or Java, but the mechanism calls and interaction are the same. I point this out, because interacting with the GAE Datastore if quite different if you are using Python or Java as the Java provides JDO and JPA as a means of interacting with the Datastore. However, to reiterate, the Blobstore interaction is the same; though syntactically different.
· Azure Storage provides three API entry points for developers:
o REST
The experience is consistent when using either of the Azure choices. Unlike the Blobstore API the Storage API provides enough flexibility that a developer is free to choose any .NET language or, and as a huge plus, absolutely any language or platform that may make REST calls. This means that you could implement using ASP.NET, Python, Java or any others and build on any platform like Windows, Linux, Unix, OS X, and still have the same experience and the same features while interacting the Azure Storage service.
The next thing that became painfully obvious to me is the mechanics of using the Blobstore. Maybe it is due to my familiarity with Azure Storage that is making me predisposed to disliking GOOG's implementation here, but I don't think so, because I don't find interacting with the Datastore difficult or unlikable. I might even argue that if you have any experience working with files you'll be predisposed to disliking the mechanics of the GAE Blobstore. So, let's take a look at GOOG's first and then we'll follow with an Azure sample stolen from some code that I will be posting on Codeplex soon.
With smudging of some of the details, uploading a BLOB into the Blobstore works the following way:
1. Identify the file by full path
2. Assign the path to the blob_info object
3. Retrieve the key (you will need to subsequently access the BLOB)
4. If using BlobstoreUploadHandler it rewrites the request and uploads and stores the MIME bodies are stored
5. You can then fetch the blobs directly using the key that was generated
I'm not sure why GOOG implemented the API like this and it may work fine for their internal apps, but I think that they are going to have to expand the API. Also, I couldn't find a way to upload a entire directory or recursively uploading directories without keeping track of the files that are done in a persistent store (e.g., Datastore) and causing a browser refresh for every file or using JavaScript to dynamically add <input/> elements of type file which is also pretty clunky. It may be there, but it is not obvious to me. With that said, let's look at the code to upload a single file. For this sample I simply used the sample provided in the documentation. That code looks like this:

I used an image here to easily preserve the text formatting as it is in IDLE as the copy-paste functionality from it only passes plain text. This is the main handler for the page that generates a user form. Note the upload_url variable is created via the Blobstore API. This URL is assigned as the value of the form action. Hence, the user will interact with the form element file as defined in <input type="file" name="file"> and select a file and then click submit. The generated URL in the AppEngine developer environment will look similar to https://localhost:8080/_ah/upload/agdqb2Z1bHR6chsLEhVfX0Jsb2JVcGxvYWRTZXNzaW9uX18YCAw. Two things of note in this URL are the _ah part of the path and the string at the end. The AppEngine Blobstore intercepts this post and extracts the MIME parts of the post storing them into the Blobstore. Here is where I suggested earlier you might dynamically generate an input field for every file found, if we were to recursively discover files, and insert <input type="file" /> elements into the form then we could effect a multi-file upload without a browser refresh. I suppose that this might also be accomplished via a network library to do the HTTP posts, but it would still require multiple posts or an generated set of form post elements in order to work. However, I have not attempted this and it only represents conjecture on my part. I might research this more practically at a later time and see if I can follow-up and effectively do bulk uploads to GAE's Blobstore. For now, let's focus on the one and the general mechanics as illustrated by the single file upload.
Taking a look at the Main function of the webapp we can see the handlers that are assigned for the various paths:
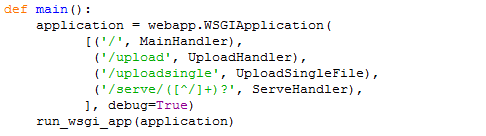
Note that we have moved through the MainHandler on the first request once we selected the file and clicked submit. Now, the content is posted to the upload URL. That URL, referencing the first code image and the generated URL above you can see the word "upload" in the URL and that in main() a handler is defined as UploadHandler for anything that is posted with /upload in the URL. Let's take a look at the UploadHandler:

Not that this handler is only defined for the post verb. Also, note that the class UploadHandler extends blobstore_handlers.BlobstoreUploadHandler. By extending this class we get a little bit of work done for us for free. It is by extending that class that the Blobstore will extract the MIME parts and store them. Thus, once it enters into the code for the handler a blob object has been created along with a corresponding blob_info object in the Datastore. We then call get_uploads passing the file path. That call will result in a list of uploaded files. Since we have one input field of type file there will be only one entry in the list. We grab the key value from the blob_info object and redirect back to the serve path putting the key in the URL to cause the uploaded content to subsequently display to the user. Referencing main() again we see that to serve the content there is a defined URL path of "/serve/" and that is mapped to the handler ServeHandler. That code is:

As defined, this only responds to get verbs. For the request https://localhost:8080/serve/fYEiKpd9v1U_znTY1ewD4w== the URL contains "/serve/" causing the handler to be invoked for the get request. The key has been concatenated to the end of the request and comes into the handler as the variable named resource. The key is then used to fetch the blog by calling blobstore.BlobInfo.get([key]) and subsequently sent to the requesting browser via self.send_blob([blob_info]).
I don't know if it jumps out at you or not, but looking past the awkwardness of the API which presents difficulty just in staging content we also have to consider that for any image, video, or other BLOB resources that we'ved store, we must also:
1. Know the key of the object or look it up by getting a list, parsing the file name (it is the original full path), and comparing the name of the sought resource to the name of the file.
2. Generate an URL for the object that is not easily known or easy to read and get an understanding as to the target content; so much for the sitemap.
The point is for the two items above is that if you have a standard convention for storing and naming resources you must forego your convention and are forced to use the generated keys. This may not be a big deal if you're starting from scratch, but if you're migrating to the cloud it could present quite a challenge. Also, if you implement in this manner it likely won't easily migrate from this (GAE) to another platform. Also of note, it seems as if Blobstore is tied to the application meaning that you could not share the content itself across applications, but rather must have other applications call through the application associated with that particular Blobstore to access the BLOBs.
So, with a that short review of using GAE's Blobstore, let's take a very brief look at the required mechanics for storage and retrieval in Azure Storage. Azure Storage feels more like a flat file system when you want to interact with it. For that matter, if you were to say that the use of folders had no structural implications, but rather only assisted in specifying a unique name for a given file then you could say that it behaves exactly like a file system in that regard. In Storage you may create any number of containers in which you can store BLOBs. This can help in many regards, because it facilitates organization and security (that provided by Storage or any access methods built on top of it). The sample I'm going to use for upload is actually designed to upload a folder and all of its descendants into a specific Storage container. The file names will be created as relative path names from the site. For example, if you had a site www.mysite.com and you designated that resources (images and such) were to be kept in a path /resources then to access some.jpg one might have a URI that was www.mysite.com/resources/images/some.jpg. To create a unique name in the container we use the relative path off of the URL. Thus, the name that we store in the container for that particular file is "/images/some.jpg". This is a design decision that you must implement, but it makes it easy to identify resources as they relate to the structure of the site. The upside is that Azure Storage doesn't force some type of key retrieval mechanism making it very easy to move between local site storage and Azure Storage as the location for any given set of resources. Let's start looking at the code. The following function is called and uses some configuration settings to know where to look. This is the first function in the call chain to upload the files. Uploading a single is very simple and you can extract that logic yourself from the samples that I will post here.
{kind=link}
static void MoveFromFolderToContainer(string FolderPath, string ContainerName, CloudStorageAccount StorageAccount)
{
//use the last folder name in path as the root and take it and any ancestor folders to the file name
string[] FolderNamesArray = FolderPath.Split(new char[] {'\\'});
string ResourceRootFolderName = FolderNamesArray[FolderNamesArray.Length -1];
CloudBlobClient BlobClient = StorageAccount.CreateCloudBlobClient();
//need to check if container exists
//get the target container
CloudBlobContainer BlobContainer = new CloudBlobContainer(StorageAccount.BlobEndpoint.ToString() + "/" + ContainerName, BlobClient);
//set request options
BlobRequestOptions options = new BlobRequestOptions();
options.AccessCondition = AccessCondition.None;
options.BlobListingDetails = BlobListingDetails.All;
options.UseFlatBlobListing = true;
options.Timeout = new TimeSpan(0, 1, 0);
//In case this is the first time that we are accessing/loading this container we'll call CreateIfNotExist() to ensure the container exists
BlobContainer.CreateIfNotExist(options);
//get enumberable list of blobs
System.Collections.Generic.IEnumerable<IListBlobItem> TargetBlobs = BlobContainer.ListBlobs(options);
//open file system
System.IO.DirectoryInfo DirInfo = new DirectoryInfo(FolderPath);
//call recursive function to load all contents and children of a directory into the storage container
IterateFolders(DirInfo, BlobContainer, TargetBlobs, ResourceRootFolderName);
}
In the above sample we do the following:
1. Take the last folder name of the source file path to use as the root for naming files that we are saving to Azure Storage
2. Create a CloudBlobContainer based on the name passed in
3. Set request options for the BLOB
4. Get a list of current BLOBs in the container
5. Get the a directory info object for the source directory
6. Call the function that will work through the folders and upload all BLOBs
This pattern really isn't much different than if I wanted to copy all of one folder to another target folder. Thus, a well understood pattern and flexible in that I can do what I desire and, to some degree, choose exactly how I do it. That leads us on to the next piece of code that will actually do the upload of the BLOBs.
static void IterateFolders(DirectoryInfo CurrentDir, CloudBlobContainer TargetContainer, IEnumerable<IListBlobItem> TargetBlobs, string RootFolderName)
{
DirectoryInfo[] ChildDirectories = CurrentDir.GetDirectories();
//call this function again on each entry to ensure traversal of the tree
foreach (DirectoryInfo ChildDir in ChildDirectories)
{
IterateFolders(ChildDir, TargetContainer, TargetBlobs, RootFolderName);
}
//get the path name including only the rootfoldername and its decendants; it will be used as part of the filename
string PreAppendPath = CurrentDir.FullName.Remove(0, CurrentDir.FullName.IndexOf(RootFolderName));
//get file list
FileInfo[] FileList = CurrentDir.GetFiles();
//iterate through files
foreach (FileInfo file in FileList)
{
//filename + path and use as name in container; path + filename should be unique
string NewFileName = PreAppendPath + "\\" + file.Name;
//create a normal form for the filename: lcase + replace "\" with "/"
NewFileName = NewFileName.Replace(@"\", "/").ToLower();
//check to see if in destination container
IListBlobItem foundItem = null;
try
{
//note the catch block, if NO matching item is found it throws an InvalidOperationException
//we catch it and ensure the value of the item is null and use to indicate the need to convert
foundItem = TargetBlobs.First(listitem => listitem.Uri.ToString().IndexOf(NewFileName) > 0);
}
catch (InvalidOperationException InvalidOpEx)
{
//just making sure in case the return behavior is to return something other than null
foundItem = null;
}
//if it is not found it will be null and we write to the target storage
if (foundItem == null)
{
//open file and read in
FileStream fstream = file.OpenRead();
//write the file straight from the stream to the Azure blob
CloudBlob destBlob = TargetContainer.GetBlobReference(NewFileName);
destBlob.UploadFromStream(fstream);
fstream.Close();
}
}
}
In this block of code we do the following:
1. Get the child directories of the current directories
2. Call recursively into the function for each of the children
3. Create a file name based on the relative path of the file (which makes sense in sense of a site structure)
4. See if the file exists in the container
5. If it doesn't we write the stream to a BLOB object in the container
This is a little more code than we used for the GAE example, but it does more work. It uploads all descendants to a container and gives a path relative name to each uploaded resource to facilitate easy access. If we pulled out just the part to upload the a single file it would end up being something like 10 or less lines of code. This example is about 30 lines of code and provides a lot more functionality than even appears to be possible in GAE's Blobstore API implementation.
As for features of the two stores:
· we can set metadata in both
· Azure provides direct URL access to files in containers, but Blobstore requires a key and a handler to serve the content
· Security
o GAE Blobstore has no built-in security features; security would have to implemented in the serve handler
o Azure Storage provide public, private, and leases for built-in security. Additionally, we could implement a more robust security mechanism through a Web Role which would be similar to working through the handler for GAE Blobstore
· Available API
o Blobstore API is minimal at best
o Azure Storage has a rich API that has two means of surfacing and consuming the Storage service
o It is expected that GAE Blobstore API will expand their API, but it is uncertain, based on the awkwardness of the current API, what form that will take
· Storage Sizes and BLOB types
o GOOG max size is 50 MB per BLOB with a max of 1MB uploaded at a time.
o For BLOBs Azure Storage presents two BLOB types:
i. Azure Block Blobs
· Optimized for streaming
· Maximum size of 200GB per BLOB
· Upload 64 MB or smaller block blobs with PutBlob
· > 64 MB block blobs must be uploaded in 4MB increments
ii. Azure Page Blobs
· Optimized for random read/write access
· Maximum size of 1TB
· Since someone might bring it up
o GAE has an image service that can be used to transform (e.g., rotate, crop, resize, etc.) images and it can use the Blobstore as the image source. This limits the output file to 1MB due to the image being returned directly to the caller.
o For Azure and .NET one would use System.Drawing namespace to accomplish similar tasks and subsequently have that code running in a Web or Worker Role.
· Consumption of API
o For Blobstore there is no easy way to create a non-browser based process that could do upload, download, or other interactions with the storage container. Thus, daemons to do whatever various tasks one might identify.
o Azure Storage allows for this type of programmatic access for apps running on local machines or as Worker Roles in the cloud. For that matter, one could implement daemons on other platforms that interact with Azure Storage via REST.
There are a number of other point for point feature comparisons that could be made, but the goal of this post is to give folks, especially .NET developers, an understanding of the difference in practical application of the two. In their current incarnations, Azure Storage for BLOBs is superior to GAE Blobstore. If, for one reason or another, I wanted to use GAE to build and deploy and app I could argue that it would be more attractive from a functional perspective to use Azure Storage for my Python or Java GAE implementation :)