Automating Process Dump for Azure Functions using Kudu and Alerts
Recently I was asked how I might programmatically dump the w3wp process for a Function App. Jeremy Brooks (fellow Microsoftie) pointed out that I could issue the same GET requests used in Kudu to show process information in the dashboard. So, before I get to the automation, I'll review fetching information using Postman.
Setup Deployment Credentials
If you are currently using Kudu for deployment, you've already done this. If not, take a look here (/en-us/azure/app-service/app-service-deployment-credentials) and follow the guidance to get a username and password setup.
Requests in Postman
In Postman, use the Authorization tab to set the type to Basic and enter the username and password that I created as a Deployment Credential.
[caption id="attachment_375" align="alignnone" width="300"] Kudu API Calls in Postman[/caption]
Kudu API Calls in Postman[/caption]
Postman takes care of Base64 encoding and adding the header. It'll be a little more work when I get to the code :)
The next thing to know is that I will issue 3 different GET requests, but all are located at the Kudu endpoint. Thus, base URI and pattern will be: https://[yourAppName].scm.azurewebsites.net/api/[command]. The three commands I wish to execute are:
- /processes - retrieves a list of all running processes
- /processes/[processId] - properties of a specific process
- /processes/[processId]/dump?dumpType=[1||2] - dumps the process with 1 for mini-dump and 2 for a full dump
Before I move on to the code, I want to review the sample return from the first two requests that need to be issued. The first request is simply going to give us the list of the processes that are presently servicing the Function App. It will look something like:
[
{
"id": 4292,
"name": "w3wp",
"href": "https://[appname].scm.azurewebsites.net/api/processes/4292",
"user_name": "IIS APPPOOL\\[appname]"
},
{
"id": 6948,
"name": "w3wp",
"href": "https://[appname].scm.azurewebsites.net/api/processes/6948"
}
]
I clearly don't have much going on here and if you have something of any amount of significance running you'll have a lot more line items. The key thing to note is "name" key. I am going to want all items in the array where the "name" key has a value of "w3wp". However, I don't want to dump the w3wp process that is serving Kudu. Which brings me to the second set of requests. For every item I use the "href" value to retrieve the individual properties of the process. The result for each of those will look something like:
{
"id": 4292,
"name": "w3wp",
"href": "https://[appname].scm.azurewebsites.net/api/processes/4292",
"minidump": "https://[appname].scm.azurewebsites.net/api/processes/4292/dump",
"iis_profile_timeout_in_seconds": 180,
"parent": "https://[appname].scm.azurewebsites.net/api/processes/-1",
"children": [],
.
.
.
"is_scm_site": true
}
I've cut a lot of the properties out to keep it manageable in this post, but I kept in the key that we are searching to compare "is_scm_site". Thus, as we loop through the process list that we got from the first and check for this property for false before dumping the process. Thanks to David Ebbo for pointing me to the "is_scm_site" key.
Implementation
I've created a blob storage container named "dumpfiles" to receive the process dumps and I'm organizing them into folders for date.
[caption id="attachment_385" align="alignnone" width="497"] Storage Structure for Dump Files[/caption]
Storage Structure for Dump Files[/caption]
Function Code
The next bit was a small bit of code that I throw into a separate Function App to retrieve the information from Kudu. To get things setup, I need to grab the list of running processes issuing the same GET request that I issued in Postman. To that, I've got a little code to setup the HttpClient.
HttpClient client = new HttpClient(); client.BaseAddress = new Uri(baseAddress); // the creds from my .publishsettings file var byteArrayCredential = Encoding.ASCII.GetBytes(usr + ":" + pwd); client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Basic", Convert.ToBase64String(byteArrayCredential)); // GET to the run action for my job var response = await client.GetAsync(apiProcessPath); responseString = await response.Content.ReadAsStringAsync();
In this first call, the baseAddress is "https://[Fn App Name].scm.azurewebsites.net/" with the apiProcessPath is assigned the value "api/processes/". This gets me a JSON Array which I'll loop through and grab process details. To that end, I've setup a loop to iterate the Jarray.
JArray jsonProcessList = JArray.Parse(responseString); //setup loop to check each process and dump if is w3wp and is not is_scm_site foreach (var processItem in jsonProcessList) { if (processItem["name"].Value<string>() == "w3wp") { log.Info("checking " + processItem["name"] + ":" + processItem["id"] + " for scm site"); string apiProcessDetailUri = processItem["href"].Value<string>(); response = await client.GetAsync(apiProcessDetailUri); responseString = await response.Content.ReadAsStringAsync();
So, here I just check to make sure it is the process in which I'm interested (processItem["name"] == "w3wp") and if it is I'll use the "href" key that is returned with the previous call that gives me the URI to retch the process details.
JObject processDetail = JObject.Parse(responseString); if (processDetail["is_scm_site"]?.Value<bool>() == true) { log.Info("process " + processItem["name"] + ":" + processItem["id"] + " is the scm site"); } else { log.Info("fetching process dump for " + processItem["name"] + ":" + processItem["id"]); //TODO: Need a means to handle a larger return than can be handled by string string processDumpContent = default(string); //construct the query string based on the process URI; using type 1, minidump response = await client.GetAsync(apiProcessDetailUri + "/dump?dumpType=1"); processDumpContent = await response.Content.ReadAsStringAsync();
In this section of code, I'm simply ensuring that I only dump for the non-SCM site (serving Kudu). To do that, I construct the URI and query string to request a minidump (apiProcessDetailUri + "/dump?dumpType=1") for the process. The last bit of code is just to name the file and persist it to BLOB storage.
string path = "dumpfiles/" + DateTime.Now.ToShortDateString().Replace(@"/", "-") + "/" + DateTime.Now.ToShortTimeString() + " - " + processItem["name"] + ":" + processItem["id"]; var attributes = new Attribute[] { new BlobAttribute(path), new StorageAccountAttribute("processdumpstorage_STORAGE") }; using (var writer = await binder.BindAsync<TextWriter>(attributes)) { writer.Write(processDumpContent); } }
Once I've set the name as desired to get the desired organization, I set Attributes to connect to my BLOB storage target and use the binder with those attributes to create a TextWriter that then use to persist the dump.
Alert + WebMethod
The last bit to tie it all together is to create an alert on errors that calls a webhook (the Function App endpoint that I created) if there is an error.
[caption id="attachment_395" align="alignnone" width="300"]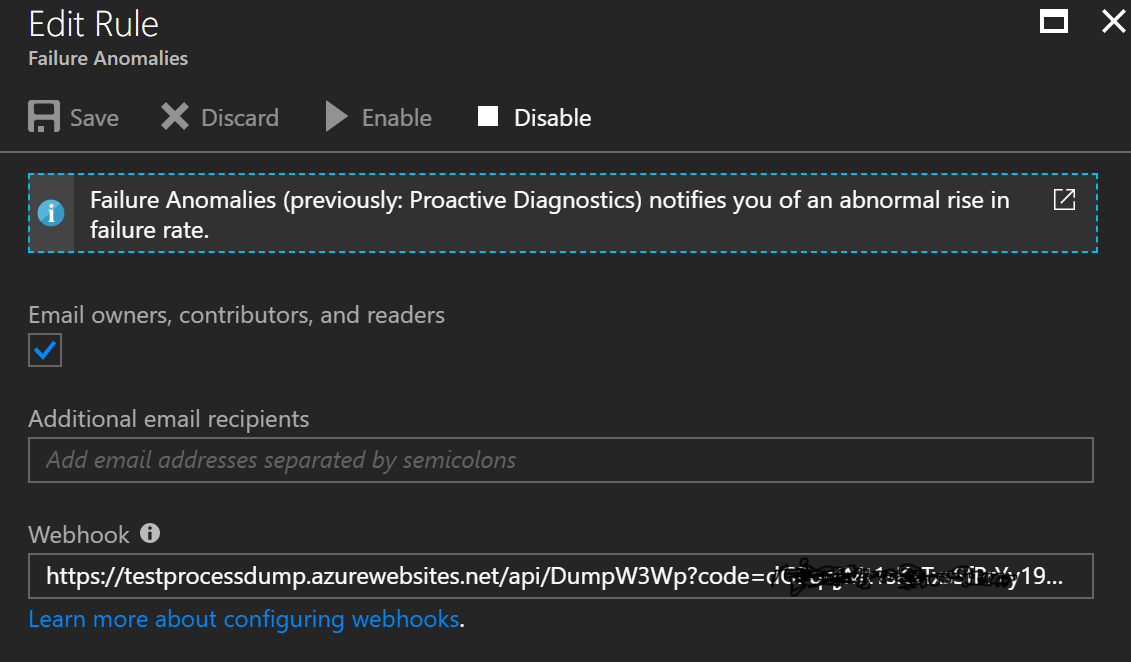 Set Webhook in Alert[/caption]
Set Webhook in Alert[/caption]
I've done it here in the Alerts (Classic) UI. I've grabbed the Function's URL from the portal which has the code in the querystring and provided as the Webhook in the configuration UI.
Housekeeping
With everything configured and code in place, I should start to see w3wp dumps when my app has exceptions. However, this sample has a number things that need to be considered if doing this in a more production fashion.
- Credentials and paths
- I've simply assigned variables directly in the code. You would want to store and retrieve the values separately.
- KeyVault is ideally the place for the credentials
- Root path for the Kudu API is a little of something to explore. For example, could we pass it in via the new Alerts mechanism? So, there is some research to be done there. The same sort of thinking applies to the dump type.
- Scale issue - if the Function App has a large number of hosts we need to parallelize the dump collection and look into ways to target better.
- My for loop to iterate the JArray and check the process for is_scm_site is sequential. It would be worth looking at using parallel for and running a few checks at a time. The exact amount of concurrent fetches would probably be a bit of a science project to get right.
- Need to research errors reported to see if there is information available that could be passed to the webhook to specifically target the process.
- Data Size - I used a string to retrieve the process dump which limits me to a theoretical 2GB.
- Look at a more efficient type for receiving and holding data (maybe local filestream as temporary holder spot?).
- If local filestream works then maybe there is more efficient copy mechanism too.
I'm sure I missed out on a few things, but these are my thoughts at the moment. If you have any thoughts or feedback, post it up and I'll try to incorporate where it makes sense.