Factories 201- How would you build it?
Previous posts in the Factory 201 series:
-
- What are they (concretely)? (Edward)
- When would you build one? (Jezz)
- What do I tell my Manager? (Edward)
- How long will it take? (Jezz)
- What would you build? (Jezz)
- With what would you build it? (Edward)
Now that we know what we are going to do, what automation assets to create and which technologies to use to build them, the next question is really: what process do we use to do that, and how to actually build the factory? In other words, “How would you build it?”
We covered a little bit of this process already in “What would you build?” where we outlined the basic process for automating your solution as a factory product. But for clarity, let’s run through that again here. (Although I recommend you read that post first for a bit broader context).
Lastly we look at getting started, and creating the first version of our factory.
[To clear up some nomenclature, we use the term ‘solution’ and ‘product’ apparently interchangeably in this post. A ‘solution’ is really the existing solution that you have before you had a factory, and the meaning of it is what developers fully understand as the physical solution to a problem. When we say ‘product’ we are referring to the thing that comes out of the factory; it is also a solution to the original problem, but with a slightly different semantic meaning, since it might not always be a complete physical solution.]
The Approach
If you have consumed the majority of ‘The Book’ on software factories by Jack and Keith, you might come away thinking that to build a software factory requires a heavy amount of engineering and pre-design before getting starting. One misconception arising from this definitive text is that building a software factory requires a kind of ‘big-bang’ type of approach; which could not be further from the truth for building factories today. It’s just a common perception of course, the book has very much ground to cover in teaching the principals of this space, and it’s extremely informational and a invaluable definitive resource on the subject. However, because the book is mostly focused on the ‘why’ and ‘what’ of software factories, much of the ‘how-to’ of realising a concrete software factory is pretty abstract.
Now, assuming you meet the pre-requisites as outlined in “When would you build one?” you should be in a good position to start right away transforming your solution based assets into automation assets for constructing your factory.
[If and when we have software factory authoring tools sometime in the future, they may well offer other alternative starting points and processes for building factories that require more careful upfront planning and design. But until then, the reality of building software factories today is quite different, since we are approaching it from ‘bottom-up’ approach of transforming available solution assets into automation assets for a known domain, and discovering the factory we need for that as we go.]
Common Practices
Before we get into any discussion about a process of any sort - hold on a second!
For many people today, building automation assets is very informal, more like, trial-and-error at the moment while they skill-up and explore the current toolsets, modelling and automation spaces – this is a pretty new and exciting domain to many who stumble across it. There isn’t a whole lot of guidance yet on the 'how-to' formulate anything like a software factory out there right now - which is of course, what we recognised, and why we are doing this series of posts for you!
With the power the current toolsets bring, many just simply want to ‘templatize’ some of their current solutions, some want to code generate some stuff, and others just want to model something, and of course any combination thereof. Many may not even start with a full reference implementation of their solution; instead they only have a few of the pieces to get started, expecting to discover the other pieces and fill in the blanks later. These are great drivers for building a factory of course.
If you are currently involved in this kind of discovery phase and not entirely sure if a factory is for you, you will probably be a little averse to being prescribed a process for doing what you need to do, or what you are already doing. However, what we have found is, that if you look at the process below carefully and reflect on the things you do yourself, the decisions you make, and why - you will probably notice that these process steps are almost exactly how you think about converting your solution assets into higher level automation assets.
The fact is that this process wasn’t dreamed-up from some academic theorem, or idealised notion of how to build factories - it is simply a description of the natural stages that you as a factory builder go through in evolving and developing your automation assets from existing solution assets to expand the productivity of your factory.
So, whether you already started creating your automation assets individually for fun, or you are considering embarking on a factory team-development project, the process of turning solution assets into automation assets should be very similar to the way you are doing it now.
Incremental, Agile Process
The basic overall process for factory construction today is to incrementally develop your factory from initial solution-based assets in bite-sized chunks following an agile development process.
That does not mean you need to follow agile development practices such as extreme programming and test driven development etc. But it does mean, not having to ‘go dark’ for months and do a whole bunch of heavy design and upfront engineering hoping to implement a finished factory in one go some time in the distant future.
Why? I think the answer is pretty clear when you consider the complexity of building any reusable asset or automation tool, such as a factory, which has to create products to suit many different end-user scenarios.
Keep in mind that a factory creates a product line (multiple related product variants) each variant different to another because of the configuration of a point of variability in the product, and further, that product variant from the factory addresses a specific scenario. Without sticking to the constraints of meeting specific scenarios, factory development would continue infinitely, decomposing, identifying and refining points of variability until the product is so finely variable as to warrant the factory productively useless. You would have basically rendered the factory back to a low level abstraction similar to source code again. So really, how far you go is a fine balance between creating a variable enough product to just suit all the scenarios you want in your domain, and no more. There are several challenges with predicting how much work to do to get to a point where the factory is good enough to fulfill all the necessary scenarios, and it's unlikely this will be known when you start factory development.
Let’s look at some of the reasons why an agile development process lends itself ideally to software factory development:
- If you can’t predict all the scenarios you want to cater for with your factory, you’ll not be able to predict all the product variants you need to create, and hence all the variability you will need to address and calculate the automation assets you will need to create for that. This will all need to be discovered incrementally, addressing the simpler scenarios first and tackling the tougher ones later.
- As you tackle each scenario, and design each product variant to suit that scenario, you’ll want your factory to configure, deliver and verify this complete functioning product variant at every stage.
Once you have reached a point where the factory addresses all its specific scenarios, applying more effort into automation may be in vain. Unless, perhaps you just want to increase usability and productivity of the factory with further refinements to the automation.
Evolution & Change
The key point with factory development is to always be in a position to create a predictable, stable set of product variants - so you can deploy them!. These 'products' can then be analysed ‘offline’ to see where they deviate between what is needed for a future scenario and what the factory actually creates (i.e. in user acceptance testing). The results of that analysis will be fed back into the factory identifying, most likely, another point of variability, and a new version of the factory can be developed further to address that new scenario.
It’s interesting to note that whilst the factory is developing and evolving, the actual product itself will evolve very little in terms of scope. All that will really change are the different variants within that scope that you can create, (i.e. the specific configuration of the products variants). It is also possible that the underlying reusable product-based assets, like frameworks and class libraries, are further refined as the product is generalised and refactored to tease-out the variability.
So, let’s have a look at the software factory development process in some depth.
Process Steps
What we describe here is a progressive, iterative, generative process for developing your factory. It does have several entry points for starting an iteration, depending on what is planned to be achieved in the next iteration.
Keep in mind that this process assumes you fulfil the assets pre-requisites laid out in “When would you build one?” (i.e. existing solution-based assets preferably a full reference implementation).
Let’s just state the basic process steps here, and then follow that with detailed explanations:
- æ Define/redefine scope of the solution domain (the product)
- Collate relevant product-based assets
- i.e. RI’s, frameworks, libraries, templates, patterns, etc.
- æ Identify the logical components ‘work products’
- Use relevant architectures and patterns to guide you
- æ Identify variability (how the work products vary)
- CV analysis. Generalise and refactor product-based assets
- æ Build automation assets
- i.e. recipes, wizards, DSL’s, templates, runtime etc.
- Re-generate product variants, then verify, and deploy
ãã Re-iterate
[ æindicates an optional entry point for each iteration.]
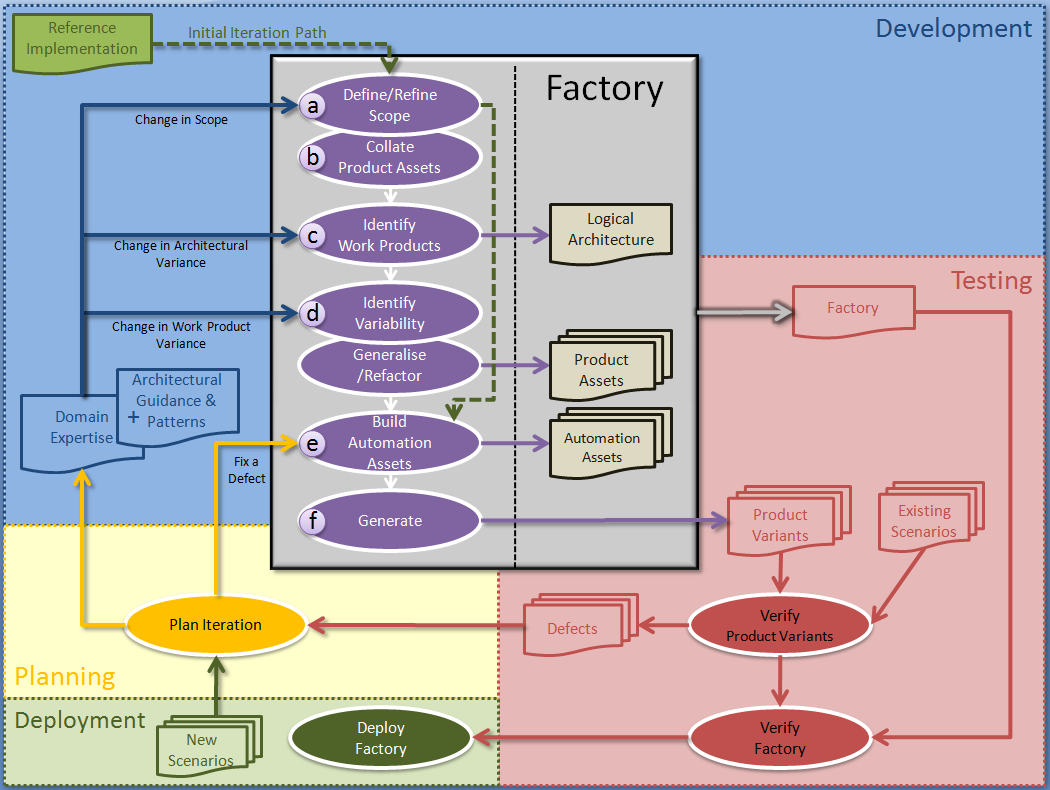
An initial iteration occurs when getting started building the factory, this iteration skips some of the process steps, and instead runs from (a) to (e) and then (f). Once that iteration is completed, the next iterations maybe started at any one of the entry points (a), (c), (d) or (e) depending on outcomes of previous iteration, and the next iterations follow in the same manner.
Steps (a) and (b) – Define Domain, Collate Assets
In step (a) you scope the domain your factory is addressing (i.e. the bounds of the product you are building – solution domain). In step (b) you collate together all the relevant product-based assets you already possess to address your domain.
Initially, the order of step (a) and (b) may depend on your objectives and motivations for building a factory. For example, if you are building a factory from a requirement to automate existing assets, such as would be the case if you already had a code-based framework, you are likely to start at step (b) before defining your domain at step (a). If your objective is more based around creating a factory from business requirements etc., you are likely to start at step (a) and collate together any assets before starting at step (b).
After the initial iteration, you will always execute (a) before (b).
Step (c) – Identify Work Products
The next step, after you collate together your product-based assets, step (c), is to identify the logical components of the solution – abstractions. These logical components are referred to as ‘work products’ of the factory, and the work products represent the ‘abstraction’ and variability of the physical components of your product.
You would identify the work products by leveraging existing architectures and patterns known and adopted in your domain. These should help indicate what the moving parts are (naming, structure, concerns etc.) and perhaps indicate some of the variability of them. If no patterns or architectures exist for your domain then you may need to derive them. The key here is to leverage what is commonly known about this domain and communicate that to those who will ultimately use those abstractions – the factory users. This helps guide those using your factory in understanding how to assemble the product in an expected and predictable manner.
What you are looking for at this step are logical abstractions (simplifications) of the physical components of the solution. This is not necessarily a one-to-one mapping, as your work products can describe many physical components grouped together as one logical unit. What you are aiming for is a logical architecture of your product with course-grained defined work products related in a hierarchical structure that can be easily assembled by your factory users.
Step (d) – Identify Variability
Step (d) is all about identifying how the work products vary. Here you are focused on separating the common parts from the variable parts of the solution components and then representing the variable parts in meta-data description (work product configuration).
You can use a process called ‘Commonality/Variability Analysis’ to factor out the common parts and identify how the remaining parts vary. Typically, the outcome of this analysis is to refactor your product-based assets and move the common parts into reusable framework/class libraries, and then describe the varying parts in your work products using meta-data (configuration). In some cases the varying parts might require additional or differing architecture, in which case, you will decompose and identify further child work products of the work product.
After this step, you should now have a complete picture of the logical architecture of your product (at least virtually, in-mind), with child work products, each with meta-data descriptions. In effect you have described a ‘meta-model’ of your factory’s product. This meta-model contains the relevant abstractions of your product.
[ Incidentally, this meta-model is a representation of the ‘software factory schema’ for your particular factory.]
Step (e) – Build Automation Assets
Step (e) is all about building automation assets that represent, and manipulate, the abstractions of your product meta-model, and building these assets to operate on those abstractions (i.e building: recipes, wizards, DSL’s, automated actions, and runtime infrastructure etc.)
You may chose to 'infer' your meta-model within these assets (i.e. in a recipe). Or you may concretely declare the meta-model and persist it within the assets (i.e. within a DSL domain model). You may also decide to implement a runtime that persists and maintains the state of the meta-model (i.e. in-memory store) and provide runtime access to it, so other automation assets can integrate with it. Either way, your automation assets provide a UI representation of the work products in the meta-model that the user will use to manipulate the work products of the factory.
One thing to consider at this stage is how to persist your meta-model. Common options include: persist a representation of it in physical artefacts (i.e. source code). Or alternatively, persist it directly to a logical domain model (i.e. a DSL file, or other runtime data store).
How you persist your meta-model is likely to govern how your automation assets will operate. For example, if your meta-model is persisted in source artefacts, you would create recipes and wizards that can only manipulate and generate physical components in source artefacts. If your meta-model is persisted in a runtime domain model, then your recipes can manipulate and create work products directly to that domain model. Of course at some time later, you might create other recipes to map the work products to physical artefacts (or other representations) at a later stage.
Step (f) – Generate, Verify and Deploy
Once your automation assets for this iteration are complete, you need to ‘exercise’ them and create the various product variants from your factory for verification. Typically, these new product variants vary from those generated from the previous iteration, since they should be taking advantage of new variance provided by the automation assets of this iteration.
Creating new product variants verifies the operation of the factory. But the product variants themselves need to be verified against the scenarios they were designed for. This process may well occur alongside the development of the factory in UAT testing for example. The result of that testing is to provide feedback back into planning the next iteration of the factory.
Any defects in the factory's ability to create product variants to address the existing scenarios are fed back as 'defects' to subsequent iterations of the factory.
The factory itself can also be tested; particularly its installation and runtime operation.
If no defects in the product variants are found, and the factory operates as expected, a new version of the factory can be packaged up and deployed.
[This deployable package would be some kind of installer, and would also include other guidance assets and supporting materials as well, such as reference implementations, documentation, samples etc.]
At this point, new scenarios may arise or be introduced either from UAT testing, new deployments, or through customisations for a particular scenario.
Re-Iterate
A next iteration is planned based upon the feedback from testing the previous iteration, and from any new scenarios introduced. The choice of which step to iterate next basically comes down to the level of change required from the new iteration.
For example:
- If there is a defect in previous product variants due to inaccurate or incomplete automation, then we probably iterate back to step (e) and fix something.
- If there is a scenario that requires a change in variability of the product variants, then we probably need to iterate back to step (d) and accommodate the new variance.
- If a scenario requires a change in architecture to accommodate new variance, then we probably need to iterate back to step (c) and refactor the logical architecture.
- If the product variants need to expand domain scope to address a new scenario, then we iterate back to step (a) and change the scope of the factory (hopefully this doesn’t happen that often!).
The beauty of this process is that when you get to the end of each iteration, you should be able to deliver new product variants that addresses new scenarios. That way, your iterations can remain short, and you never lose sight of your target scenarios or their solutions, and you can quickly adapt to change in them. You can also generate revenue with these new product variants to support your next development iterations.
First Steps?
So how would we initially get started building our factory with this process? What are the first steps? You noticed the process declared an initial iteration, what is all that about?
Imagine you already had a solution and a domain in mind. You already possess mostly a reference implementation (RI) of your solution, and it already uses some re-usable assets like frameworks and class libraries. What’s the first step in turning that into a factory?
Just before we do that, let’s build an understanding of what we already have and what we want.
A 'reference implementation' is by definition an instance of the type of product you want to build – it is a product variant, albeit the first one. It addresses only a single well-defined scenario, since its solution is fixed. What you are aiming to do is provide automation of the configuration for the variable parts of the solution, using your factory, so your factory can generate a new solution that applies to more than one scenario.
A Concrete Example
Let’s take a concrete example - an enterprise level 'Web Service'.
You already have a solution for your web service in code as an sample (it’s the RI!). It uses some kind of recommended architecture and some patterns to implement its structure. But certain things are ‘fixed’ in it for this RI, for example the WSDL is fixed probably. In this domain, a WSDL is also known to describe a ‘Service Contract’. Which implies that things like the operations (known in this domain as ‘Service Operations’) are fixed, and the messages they use (known in this domain as 'Message Contracts' and 'Data Contracts') are already defined and encoded into the solution. Your solution will probably also perform some pre-defined business processing for these operations.
Now taking this example, you may want to allow someone to create a similar web service (similar in structure, architecture, patterns etc), and allow them to tweak the Service Operations, and the Data Contracts (and most likely the business logic of it too!). For that you want to create a factory that allows the factory user to define specific Service Operations, Data Contracts and associated Business Logic etc, but you want them to keep the architecture, structure and patterns, and underlying frameworks and class libraries etc., since that stuff is ‘common’ to all these types of web services you want to build.
OK, so you just identified the following things:
- Your ‘Problem Domain’ – enterprise strength, layered, services
- Your ‘Solution Domain’ – a web service
- Your ‘Product’ – a web service
- Your initial ‘Work Products’ – ‘Service Contract’, ‘Service Operation’, ‘Data Contract’, ‘Business Logic Component’ etc.
- The ‘Variability’ in some of the Work Products:
- Service Contract – Operations Contract, Data Contract etc.
- Service Operation - name, return type, request type.
- Data Contract – Data Members etc.
The only thing missing at this point is what automation assets you are going to build to allow the factory user to define the variability you just discovered. This will lead to what artefacts you need to create for your solution, and then how to build them reusing your re-able assets underneath (frameworks, class libraries etc).
At this point you are basically at step (e) in the above process. At the very minimum you’ll want to use your factory to create a product that looks just like your reference implementation, in other words, your reference implementation. This new product variant will of course have had have no variability in it, but after this minimal release of the factory, we can start focus more on the automation side of configuring that variability. For now let’s just look at getting our first iteration complete.
Initial Factory Release
The first iteration of your factory development should really just deliver your RI - as is. You’ll want to do this, because you’ll want to get familiar with the overall process that you’re going to re-iterate many times over, and it is in this iteration that you want to iron-out all the physical processes and get all project members familiar with the process stuff before things start ramping up.
To do this today, taking the example from above, and what we know from With what would you build it?, you can simply complete the following steps:
- Use GAT to create a recipe to unfold your RI into a solution template. Include in this template your entire working RI as is (files, references, frameworks etc). You won’t need to add a wizard at this point because you are not gathering any data from the user, however, you will probably want to name at least the solution file with the name the user will be prompted for in the ‘File | New Project’ dialog box when they select your solution template.
- Compile and register your GAT package. Create an installer for it. This is now the basis of your factory (albeit just a Guidance Package at this stage).
- Install the ‘Factory’ on your test environment and verify it installs your first ‘Product Variant’. Your product should now build and run as expected.
- Verify that your product is good, through User Acceptance testing etc.
- Identify new scenarios that you want to address with a new product.
- Start the process at Step (c).
So very quickly, within a day probably, you have the first version of your concrete factory (in a sense). With little or no effort a factory user can create your solution using your factory. You shipped your first product, and now you can start to develop your factory further using the above process.
Summary
In this post we have looked at a simple process of building your software factory, and we learned that we can get started very quickly and easily with that process by releasing a factory that almost immediately delivers our first product. From there it’s just a case of planning further iterations that add more and more automation and productivity to assembling the target solution. All the while, expanding the target scenarios you need to address for the domain of the factory.
We also learned a little about building re-usable assets and how to move to higher levels of design using abstractions to describe our domain. This is a very important key concept in factories, since it is through this simplification (abstraction), described in familiar terms of the domain (common language), that we can allow a broader base of factory users to create complex solutions using the factory.
There are still many challenges in the actual implementation of your factory such as new tools and technologies to learn. There are also new patterns and new factory development practices that are emerging all the time – hopefully I can share some in later posts. However, without a common platform of tools to author factories, or a common runtime for them to operate in, we just have to ‘do the best we can with what we got’ for the time being. Building factories is fairly green pastures at the moment, and there is heaps of room to innovate and contribute in this space – I wish you the best of luck.