Challenges - How do you generate your artefacts?
One of the challenges I am investigating more right now (at the pattern level) is the coalescing of artefacts from multiple parties on a model in a software factory (or domain modelling context. i.e. from a DSL). The parties in question could be different views (diagrams) or different actors on those views.
[For the purposes of this discussion: A model is the domain specific language itself, with its classes and relationships. A view exposes part of that model, usually visually. The parties acting on these things are the runtime invoked by the user.]
The question really is, if more than one party creates parts of the same physical artefacts (to represent the same underlying model) how are they combined into the final artefacts which represent the domain? Considering that these code artefacts are likely to be generated (in-part) from Text Templates somehow, and each artefact part may represent separate concerns/aspects (defined by each view). What mechanisms should/could we have in place to make weaving the source artefacts from each party possible?
To simplify the problem, we consider a single model, and multiple views, and assume that each view will create parts of the same artefacts as the other views. We also assume that each view has a separate party responsible for the artefact generation. There may a orchestrating process governing the generation and/or finalising of the artefacts after generation by all parties.
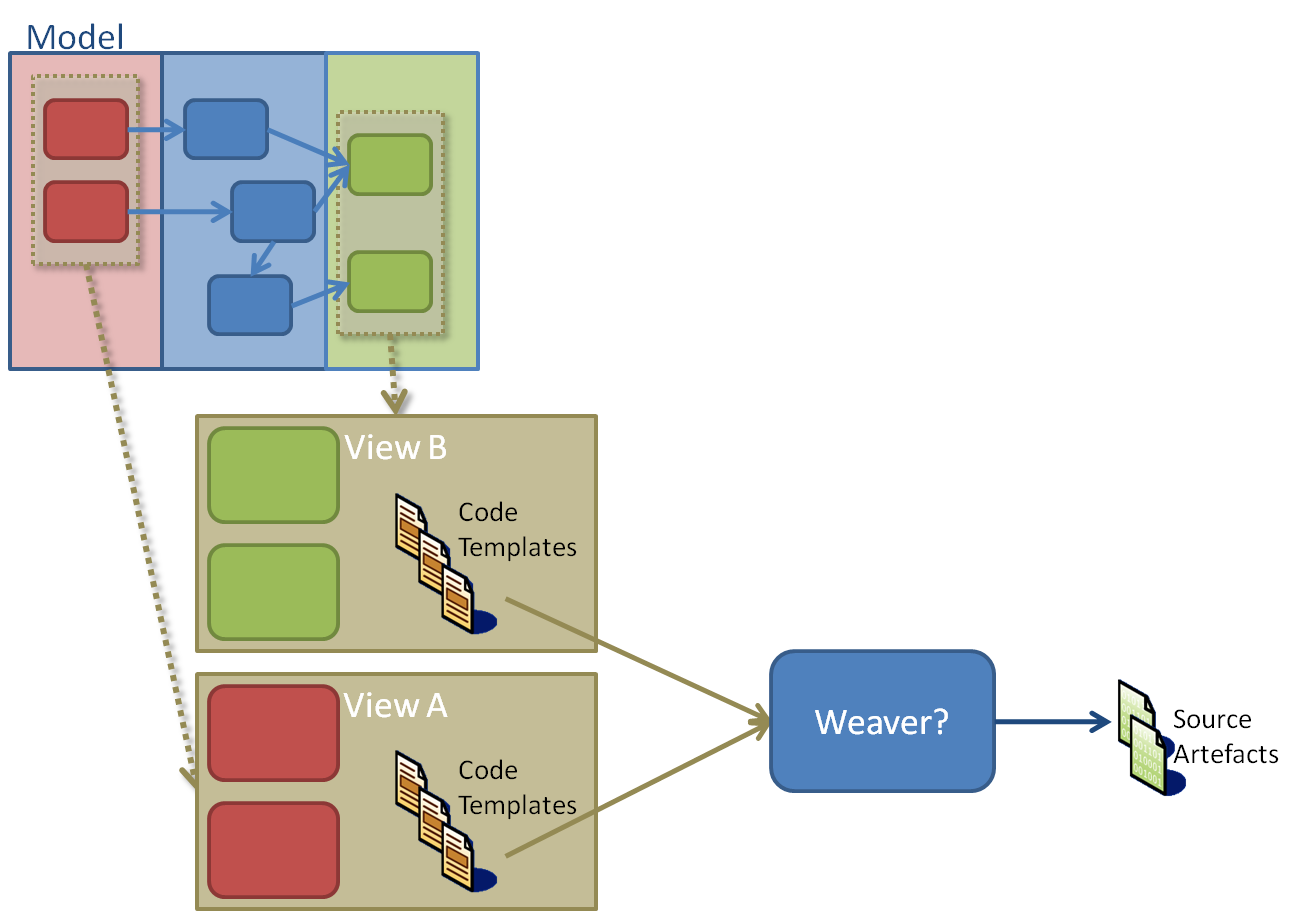
This is almost the same challenge that AOP compilers have in weaving together different aspects of a program, so this concept is not new. However, there is little support in .NET for this mechanism, and certainly nothing yet based upon Text Templating Engine that can be used by mainstream developers who are building software factories, to make this apparently desirable capability transparent.
A good concrete scenario of this is where we have a technology-independent model of an architecture, and we want to allow another party to provide a technology-specific implementation of that model (either all of it or at least part of it). For this purpose, these are just two different views of the same model (albeit perhaps enhanced by the technology-specific view).
An Example
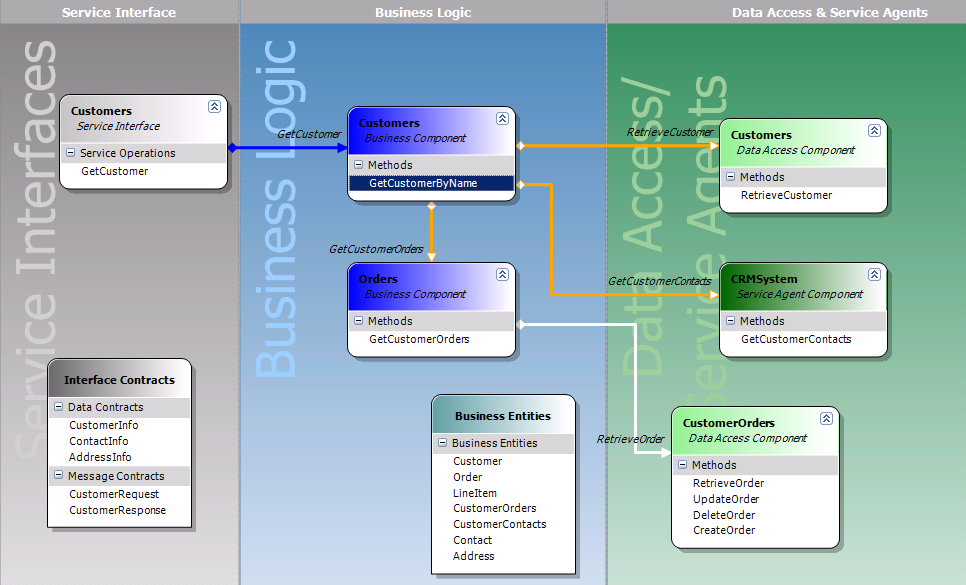
This is exactly what we have in the EFx Factory currently as an example, where the core factory provides the technology-independent model and a view of that model, and then allows Artefact Generators (tech-providers) to plug in the core factory to provide a technology-specific view of parts of that model. Lets consider, for a concrete example, the 'Service Contract' part of a Web Service architecture (left-hand grey area). The tech-provider provides a technology-specific representation of this view by:
{kind=link}
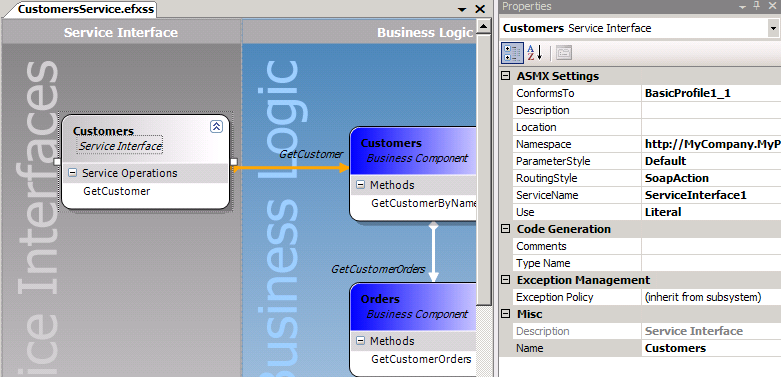
- Enhancing the relevant part of the technology-independent view (for the Service Contract) directly in a technology-independent view (as you can see here for ASMX technology)
- Providing additional (separate) technology-specific views for the Service Contract (in most cases based on a separate, enhanced technology-specific model of its own, better suited to represent the technology-specific view of the Service Contract).
{kind=link}
We can see that the technology-independent view and the tech-specific view are 2 views of the same model (or perhaps, same enhanced model) provided by different parties, and each view is concerned with different aspects of the model.
Separate Concerns & Architectural Guidance
Now, a further consideration. The technology-independent model may expose architectural concerns that must be implemented such as: logging, exception handling, authorization etc. as determined by the overall architecture. The technology-specific view therefore does not have to be concerned with these aspects, and can focus upon its' own technology implementation of other technology related aspects. But the intention maybe that these aspects, or concerns, are also implemented in addition to the technology-specific implementation. Furthermore, the technology-independent view, and runtime will more than likely have the best way to implement them best since it takes ownership of defining them, and those concerns are potentially technology-agnostic.
Problems
Either way you look at it, when transforming the views of the model into physical artifacts, the following questions arise:
- Who is responsible for artefact generation overall (which party)? Who initiates it?, and when should it be initiated?
- If the responsibility is shared, then how is that divided between the parties (who is responsible for which bits of which models)?
- Who is responsible for implementing the technology-independent concerns modelled in the technology-independent view?
- If it is the other party, then how do you ensure the concerns are implemented, and how do you control how they are implemented?
- If the same artefacts are created/touched by/relevant to more than one party, then which party modifies first? Since this implies the next party must assume the output of the previous parties.
- How do you create a co-ordinate system over the generated artefacts to piece them altogether?
- Do we desire source code weaving, or is IL code/byte code weaving satisfactory?
- If Text Templates are used, how are those combined, and how is the weaving defined in them?
Single Party Generation
When you only have one party involved in generating the source artefacts, the problems for weaving artefacts are greatly simplified, but separation of concerns, conformance and completeness are not addressed.
For example, if we just said, in this scenario, that the tech-provider does all the implementation and artefact generation for the model, then we still have issues around separation of concerns and control of those concerns. For example, should you expect a technology-specific model be concerned and responsible for general architectural concerns factored out and addressed by the technology-independent model or other cross-cutting concerns providers?
If this is the case, then each and every tech-provider must implement the same technology-independent concerns defined by the tech-independent model, and furthermore they should all do this the same, correct way. The technology-independent party has no control over how that is done, whether it is done, nor whether its done correctly as intended, not to mention the duplication of the implementation in each tech-provider.
Therefore, if we only have one party generating the artefacts, then that party must do all the generation on behalf of all the parties, which means it must have intimate knowledge of how that is done for all parties.
Serial Party Generation
Now, if we consider that one party could take the lead and the other parties could then follow, and enhance the artefacts created by the previous party - we have opened another can of worms.
For example, lets say we let the core factory generate the technology-independent 'baseline' artefacts that set the basis for all others parties to enhance. This way we can ensure that the technology-independent model is implemented correctly, and that all concerns are correctly addressed and correctly implemented.
The tech-providers then only need to adorn the 'baselined' artefacts with technology specific stuff.
Since we are talking about source artefacts (for example source code), the tech-providers need to know all about the baseline source code they are enhancing: what files, what formats. If it is code then what classes, what functions, how is it all structured? That again is intimate knowledge about what was created by the previous party. Otherwise how do they know what to enhance and how - source code is so variable? This binds our tech-provider to one specific implementation (provided by this particular party), so reuse by other parties is restricted.
Snippet Orchestration
Not only that, there needs to be some way the tech-provider can insert code snippets at certain known points in the baseline source code.
How do we define those points?, and what kind of code enhancements can we make? (attributes, code replacements, code pro-logues, code post-logues etc) We need a coordinate system for that, and that coordinate system needs to have references we can either hard code or calculate for the various parties creating parts of the artefacts.
Then we would need a way to pass the code snippets back and forth between parties, and one party to be responsible for consolidating it all and merging it together into a final artefact.
In the context of Text Templates, how then would a tech-provider author these code snippets and how would they reference the baseline code? We need to make this reasonably intuitive and elegant for the tech-provider authors creating the artefact parts.
Clearly there are some major technical challenges here.