The Factory 'Meta-Model'
Hopefully in previous posts I have been able to help de-mystify what exactly the factory schema is and how you should be thinking about it. If you are still confused about how to build a factory and how to create the factory schema, you are not alone.
My good friend Ed Bakker and I have been working together towards improving the user experience of factories, primarily for the factory user, and also for the factory author. He has just posted on some of his own thoughts in this area (Software Factories - The Next Generation).
I wanted to expand on some of those thoughts here from a different angle, in a couple of articles and focus a little more on the schema and meta-model of a factory and how they are related, the EFx factory has a bit of a head start on most of the emerging factories at the moment.
A Solution-based Approach
The first software factories on the market right now like the 'Service Factory' (from patterns & practices team) do not define or provide or use a factory schema, nor offer help on what one should look like, or how it works. They do not provide a 'model' per-se of the problem domain of building a service as a 'product' of the factory, and therefore they don't require the need for a factory schema.
Instead, the approach it uses is to define sets of losely related GAT recipes to create the physical components of a service by directly generating the source artefacts right into the solution.
These recipes are expected to be executed, by the factory user, in the right order, on the right physical solution elements, then somehow the user is expected to know what was created and further more go back into the physical artefacts, manually, and edit them (using code snippets and other recipes). It's a job for a skilled expoerienced developer who has detailed knowledge about the how the factory works, and deep knowledge of the solution domain as well.
It is the output of the recipes (source code) that maintains the *state* of the service being defined, and therefore it is difficult to re-configure the state of the service with automated tools. So to be clear, there is a 'solution model' maintained in the source code. But there is no provision for reverse engineering the 'solution model' source back to a logical 'problem model', that can be modified and re-generated easily by the factory user.
This class of factory is able, to describe the work products (physical artefacts) of the factory, and the assets that create them (tools, recipes etc), but they offer little formal schema of the factory or visualisation of that schema, and rely upon written guidance as a means to relate one work product to another.
In other words, there is no 'problem model' of the product of the factory. There is a 'solution model' persisted in the physical solution structure and its artefacts, and the factory user is expected to be very familiar and concerned with the physical model. This design thererfore only offers very little abstraction of the problem space.
A Different Approach
An approach which is more in-line with factories of the future, and one the EFx factory took to the same problem domain, is to use a model driven approach to model the service and its variability points from end-to-end. This therefore, offers an abstraction of the problem domain to the factory user. The advantages of this approach are numerous:
The Problem Model
The EFx factory employs a runtime model (a Meta-Model) of the 'product' and its' work products that the factory produces, as well as the architectural relationships between them.
The factory is then able to display a logical 'view' of the things (work products) it produces (a product model) in a hierarchy that describes how they are composed and related, offering implicit guidance on how to construct and compose them.
Separating the Implementation from the Configuration
In addition, the EFx factory offers an extensible plug-in mechanism for 'Artefact Generators' which are used to generate the source artefacts that are represented by the model (once the model has been configured).
The model describes the architectural make up of the service and the relationship of the components within, not the technology implementation of it.
Technology implementation is cleanly separated by this design, and only applied (postponed) till when the factory user is ready to select a technology based upon changing requirements of the solution.
It is these 'Artefact Generators' (seperate specialised pluggable packages) that determine how best to write the source artefacts based upon the current configuration of the model, and in all but the rarest cases, these artefascts will require no further editing by the factory user. In fact, in this design the factory user, performs little if any coding. The coding know-how of the solution domain is encoded into the 'Artefact Generator' itself.
Seperating the Logical from the Physical
Further advantages of this approach are:
The factory user no longer needs to be concerned about working with, or configuring, the physical artefacts the factory (artefacts generators) produce, nor modifying them.
The factory maintains a logical model of the product and its work products, and this logical model maintains a runtime mapping to the physical structure of the solution. The factory is able to determine where the generated artefacts are placed in the physical structure.
The factory can do this because it attributes meta-data properties from the model to the physical solution structure containers (Solution Folders, Projects, Files), designating them as a specific work products in the product model.
Therefore, since the this product model provides a seperation and mapping to the physical artefacts that are produced, so the solution structure can be independently manipulated (re-structured) to define a suitable physical deployment model of the product, rather than attempting to describing the logical structure of it. The advantage of this is clear.
The mixture of these two concerns (logical structure vs. deployment structure) often leads to poorly named and structured solutions, and much debate on what physical structure to use per solution/project/developer. Now, you can address correctly the concern of the deployment structure of the solution - independently from the logical structure of the problem.
You can see the relationship of the Logical View and the Physical View of the product of the factory in the picture below.
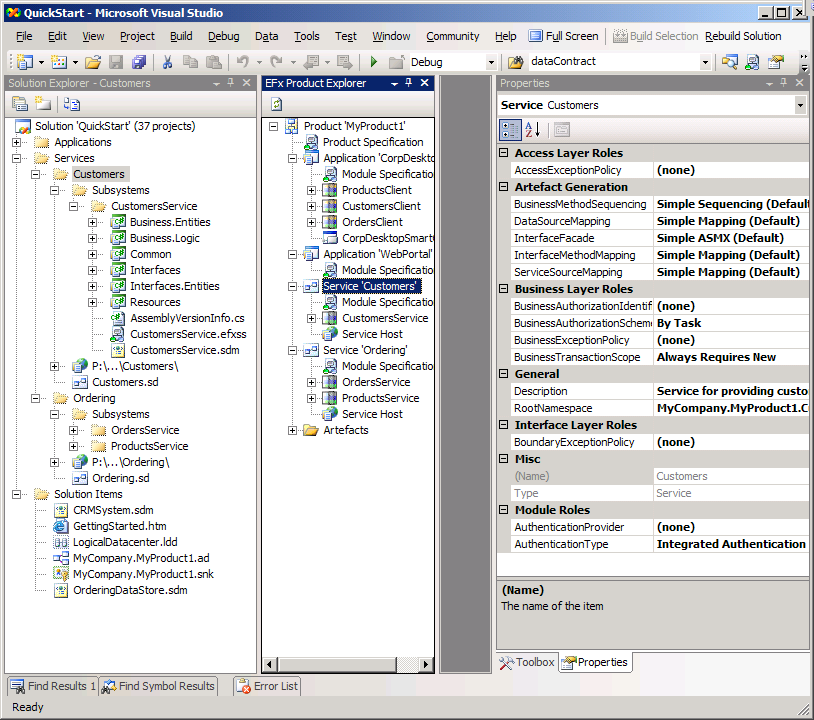
Figure 1. Illustrates the 'EFx Solution Explorer' logical view of the solution, and its relationship to the physical structure of the solution in 'Solution Explorer', and meta-data attributed to the work products of the factory.
Architectural Correctness and Guidance in Context
The fact that the service has been modelled from end-to-end and the variability of the problem domain is configurable in a persisted model - offers additional advantages:
The model already describes the relationship between the logical concepts of the architecture, and therefore can validate them at an appropriate time in context with each other, preventing invalid architectures and illegal configuration of the work products.
The user is no longer expected to know how to compose a single work product (with a set of related recipes), since the model describes and maintains the configuration of the work product. The selected specialised 'Artefact Generators' determine the correct and most efficient means to construct it, and create the physical representation of it.
The work products can be re-generated over and over again by re-configuring the model, producing reliably, highly predictable and architecturally correct artefacts every time.
For more details on the other features of this factory and their advantages see the EFx Architectural Guidance Software Factory article.