Content Pipeline その2 その流れ
コンテントの流れ
前回は、コンテントマネージメントに関する問題の複雑さについて書きました。今回から、その問題を解決する為に設計されたXNAのコンテント・パイプラインの仕組みを紹介していきます。下図は、XNAのコンテント・パイプラインの概念図です。
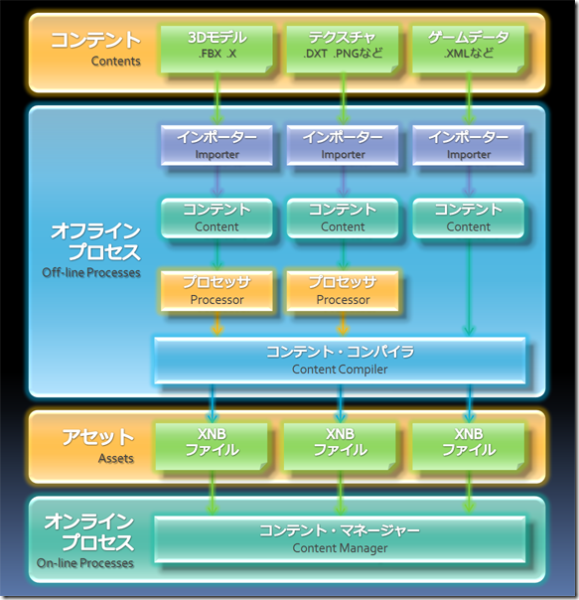
パイプラインの名から判るように、コンテントが上から下へ流れるように処理され、アセットとしてできあがったものをゲームで使うようになっています。コンテントを川の水、アセットを水道水として考えると、コンテント・パイプラインは、浄水場と配水管に例えることができます。
コンテント・パイプラインは2つのプロセスに分けることができ、ビルド時にコンテントをアセットに変換するオフライン・プロセス、ゲーム実行時にアセットを読み込むオンライン・プロセスとなります。この2つのプロセスは設計目的も明確に分かれていて、オフライン・プロセスではメモリ使用量や実行速度よりも、簡単にコンテントを加工できるように設計されているのに対して、オフライン・プロセスではアセットに対する処理のし易さよりも、メモリ使用量や実行速度重視で設計されています。
オフライン・プロセス
オフライン・プロセスの中心となるのは、データを加工しやすい構造で保持するコンテント(Content) です。XNAフレームワークには標準でMeshContent、AnimationContent、TextureContent等のコンテントがあります。コンテントは、その型に対応するTypeWriterとTypeReaderを記述することによって、どんな型でもコンテントとして扱うことができます。
次にコンテントファイルからコンテントにデータを読み込む役割をするのがインポーター(Importer) です。XNAフレームワークには標準でFbxImporter、XImporter、TextureImporter等のインポーターがあります。3Dモデルファイルなどからのインポートの場合、NodeContentやMeshContentに変換する為の処理が入るので、単なるファイルからの読み込みよりも複雑な処理になりますが、前述のようにNodeContentやMeshContent自体がデータ加工がしやすいように設計されているのに加え、MeshHelperやMeshBuilderといった補助クラスを使うことで、独自インポーター製作の労力を軽減できます。
そして、コンテントに対して様々な処理をしたり、ゲームに最適なデータフォーマット変換するのがプロセッサ(Processor) です。XNAフレームワークには標準でModelProcessor、MaterialProcessor、TextureProcessor等のプロセッサがあります。例えばModelProcessorはNodeContentからModelContentに変換するプロセッサで、実行時のパフォーマンス効率が良いようにマテリアル順に並び替えたり、頂点キャッシャの効率化のための頂点データの並び替えや、Windows/Xbox360のプラットフォームの違いによるデータ変換等が行われます。基本的にプロセッサはコンテントからコンテントへの加工をするのですが、XNAフレームワークでは処理前と処理後のコンテントを区別する為にプロセッサ処理後のコンテントはMicrosoft.Xna.Framework.Content.Pipeline.Processors内で宣言されています。
最後に、コンテント、インポーター、そしてプロセッサの管理をするのが、コンテント・コンパイラ(ContentCompiler)です。主な仕事は、指定されたアセットを生成する為に指定されたインポーターとプロセッサを呼び、最後にTypeWriterを使ってXNBファイルへの書き出しをすることです。その他にも、時間節約の為にビルドや配置(Deploy)を必要なアセットのみだけに対して行うなどの処理もします。
オンライン・プロセス
オフライン・プロセスで殆どの処理がすでに終わっているので、オンライン・プロセスではコンテント・マネージャー(ContentManager)を使い、TypeReaderを介してXNBファイルからのアセットを読み込むだけと、非常に単純なものになっています。ContentManagerは読み込んだアセットを保持しているので、既に読み込まれているアセットを読み込もうとした場合は、保持されているアセットを返すキャッシャ機能があります。読み込んだアセットはContentManager.Unloadメソッドで一括して消去することができるので、システム用、ステージ用といった複数のContentManagerのインスタンスを持つことでアセットのライフサイクルの管理をすることができます。
そしてカスタマイズへ
以上がコンテント・パイプラインの大まかな仕組みです。インポーターやプロセッサは独自のものが作れるように設計されているので、FBXやXファイル以外のモデルデータを読み込むインポーター、単純なパラメーターからフラクタルを使ってテクスチャや地形を生成するインポーター、ModelContentから当たり判定データに変換したりするプロセッサを作ったりということができます。
最大の利点はインポーターやプロセッサはモジュール化しやすいので、作ったものを簡単に皆に使ってもらえる、使えるということではないでしょうか?
次からは、実際にインポーターや、プロセッサの作り方の紹介をしていきます。