SYSK 86: .NET Reflector Revisited
In SYSK 7, I discussed a tool created by Lutz Roder that can be used to decompile and analyze .NET assemblies. The tool is available at http://www.aisto.com/roeder/dotnet/.
This tool disassembles the raw assembly and translates the binary information to human-readable, showing you the code implementation. It can also be used to find assembly dependencies, and even windows dll dependencies, by using the Analyzer option.
One thing that did not occur to me at the time is that the same tool can be used to convert C# code to VB and vice versa.
Imagine you have some C# code that you want to convert to VB.NET. You could compile this code, open and disassemble it with .NET Reflector, and then simply change the language from C# to Visual Basic in the drop down box, and you’ve got yourself same code in VB.NET! Ok, it’s not a panacea, but it’s better and more accurate that online C# to VB code converters…
This is a very cool tool! Make sure to test drive it and see for yourself…
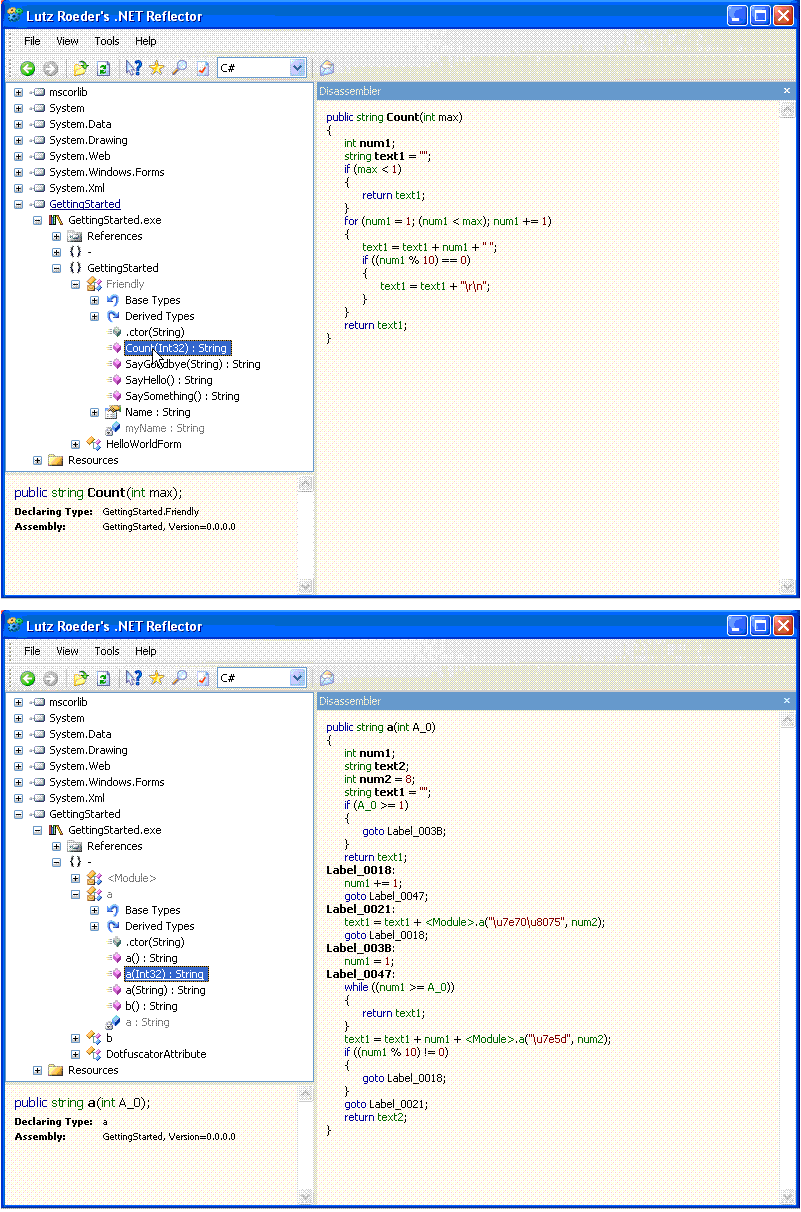
Now, if this makes you concerned about protecting your intellectual property, there are a number of obfuscator tools available today that mangle function and variable names, and make it more difficult for hackers to decipher the meaning of the code. Here is an example of non-obfuscated code and, below, obfuscated code, as seen in .NET Reflector (see attachment at the bottom)
Below are some of the obfuscators available today for .NET (in alphabetical order):
- {smartassembly} -- http://www.smartassembly.com/
- Dotfuscator .NET Obfuscator -- http://www.preemptive.com/
- Decompiler.NET -- http://www.preemptive.com/
- Demeanor for .NET -- http://www.wiseowl.com/products/products.aspx
- Salamander .NET Obfuscator -- http://www.remotesoft.com/salamander/obfuscator.html
- Semantic Designs: C# Source Code Obfuscator -- http://www.semdesigns.com/products/obfuscators/csharpobfuscator.html
- Spices.Net -- http://www.9rays.net/cgi-bin/components.cgi?act=1&cid=86
- Xenocode Postbuild 2006 -- http://www.xenocode.com/Products/Postbuild/
{kind=link}