Multi-Terabyte SQL Server Database Backup Strategies for Azure Virtual Machines
With the advent of DS-SERIES and GS-SERIES with Premium Storage, now running big databases in Azure Virtual Machines (VM) is a reality, something that was not fully achievable until few months ago. You now have the power to run up to use up to 64 x 1TB disks and use 32 cores horse-power, with about half Terabyte of memory, or you can obtain up to 114K IOPS from Azure Premium Storage and its Blob cache mechanism. However, big databases (here I consider sizes greater than 1Terabyte (TB)) come with big responsibilities: how do you intend to backup “efficiently” such multi-TB DBs? How you can efficiently move backup sets to a remote Azure datacenter to obey offsite requirement for backup set storage? Storage and network in Azure, as for any other public cloud vendor, have quite different latencies and throughput compared to on-premises, then you need to carefully consider the time necessary to move large quantity of data between VMs and between different Azure datacenters. In this article, I want to provide you some ideas, suggestions and recommendations on how to efficiently deal with SQL Server backup for very large databases in the Terabyte (TB) space.
Virtual Machine and Cloud Service Sizes for Azure
https://msdn.microsoft.com/en-us/library/azure/dn197896.aspx
Fortunately, there are several feature in both Azure and SQL Server (here I’m assuming 2014 and later versions) that may help you, before covering possible strategies in detail, let me first create a short dotted list of what I will comment later:
- SQL Server Backup to Windows Azure Blob Storage Service
- SQL Server File-level Backup
- SQL Server Backup to Storage Pools (VM Disks)
- SQL Server Native Backup Striping
- SQL Server Backup to Local SSD drive
- SQL Server AlwaysOn Availability Group (AG)
- Azure Storage Level Snapshot Backup
- Azure Backup VM level snapshot
- SQL Server 2016 Native Backup in Azure (preview)
Independently from which strategy you will adopt, SQL Server Backup Compression should be always used: it is a killer feature since can reduce backup size also by 70% (my personal experience) and there is no compatibility or side effect, additionally CPU overhead is minimal.
Backup Compression (SQL Server)
https://msdn.microsoft.com/en-us/library/bb964719.aspx
Prolog
First stop in this journey is to understand the limits that you need to take upfront in your mind:
- Azure disk/blob can be up to 1TB size and has as maximum throughput (using Standard storage) of 60MB/sec;
Azure Storage Scalability and Performance Targets
http://azure.microsoft.com/en-us/documentation/articles/storage-scalability-targets
- Azure storage GRS replica is asynchronous and there is no SLA on replica lag in the remote datacenter:
Introducing Geo-replication for Windows Azure Storage
- If you use Windows Server 2012 Storage Pools, storage geo-replication (GRS) is not supported:
Performance Best Practices for SQL Server in Azure Virtual Machines
https://msdn.microsoft.com/en-us/library/azure/dn133149.aspx
- Azure Premium Storage is only locally redundant (LRS), then no geo-replication (GRS);
- Azure Premium Storage account is limited to 35TB space allocation and 10TB snapshot size;
Premium Storage: High-Performance Storage for Azure Virtual Machine Workloads
http://azure.microsoft.com/en-us/documentation/articles/storage-premium-storage-preview-portal
- Azure Premium Storage I/O bandwidth and IOPS depends on VM size (DS-Series) and disk size: you can have a theoretical maximum of 200MB/s and 5000 IOPS on one P30 disk, but be sure to match with VM bandwidth that can be up to “only” 512MB/s and 50000 IOPS.
- VNET-to-VNET connectivity using VPN has a maximum limit of 200Mbit/sec using High-Performance gateway. Express Route can also be used to connect VNETs to VNETs, or VNET to on-premises, with circuits up to 1Gbit/sec (NSP mode) and 10Gbit/sec (XSP mode).
My personal Azure FAQ on Azure Networking SLAs, bandwidth, latency, performance, SLB, DNS, DMZ, VNET, IPv6 and much more
- There is no bandwidth nor latency SLAs on Azure cross-datacenter network connections;
- SQL Server 2014 backup to native Azure storage is limited to a single blob <1TB size:
SQL Server Backup and Restore with Windows Azure Blob Storage Service
https://msdn.microsoft.com/en-us/library/jj919148.aspx
Backup Strategies
SQL Server Backup to Windows Azure Blob Storage Service
This is the first and simplest option, very nice feature I personally like and use. It has been introduced in SQL Server 2014 and then backported in SQL Server 2012 SP1 CU2: with this feature, you will be able to bypass the need to use disks in a VM that you can instead use for scaling out on your database storage requirements. The only but important limit is that you cannot use multiple target blobs at the same time, then at the end, you are limited to maximum 1TB backup set. If you enable SQL Server backup compression (please do it!) you will be able to backup higher database sizes. SQL Server uses multiple threads to optimize data transfer to Windows Azure Blob storage services, but the bottleneck here will be the single blob. Be sure to review limitations and recommendations at the link below:
SQL Server Backup to URL
https://msdn.microsoft.com/en-us/library/dn435916.aspx
If your database is less than 1TB, even compressed, time required for full backup should be less than 4.85 hours, considering a 60MB/sec single blob throughput. If you have database size larger than 1TB, then you can’t use this feature alone, you need to take additional actions. Another important consideration: in which storage account you are storing the backing file/blob? If you use a local storage account, you will not incurring in bandwidth and latency limitations for cross-datacenter copy, then your backup will finish earlier compared to a direct remote backup in a different datacenter. Drawback is that you will need to ensure that your backup file will be geo-replicated to a remote Azure datacenter, here you have two choices: manually copy local backup file to a remote storage account, using tools like AZCOPY, or enable GRS (should be by default) on your storage account and rely on Azure to replicate remotely. Additionally, there is no SLA on when the copy will be completed, but based on my personal experience Azure is below 15
minutes. This is only to give you a general idea, don’t assume as a golden rule. If you need to ensure fixed SLA and RPO, you cannot rely on Azure storage geo-replication. But what you can do with a database size greater than 1TB, even using backup compression? Since this feature is limited to 1TB single target file, the answer is pretty obvious: do multiple backups of smaller size! How we can do that? I will explain in the section “SQL Server File-level Backup” later in this blog post. NOTE: SQL Server 2016, now in preview, will support multiple blob targets for native backup to Azure Blob storage.
SQL Server File-level Backup
This is a nice SQL Server feature not often used since it is quite complex to manage and requires careful planning and generally apply to very large database (VLDB) in the on-premise world. Essentially, instead of relying on a giant monolithic single data file, you can design the physical layout of your database in multiple data files (MDF/NDF) and File Groups:
Database Files and Filegroups
https://technet.microsoft.com/en-us/library/ms189563(v=sql.120).aspx
Using multiple files and multiple filegroups, you can essentially use data files less than 1TB and then leverage, for example, SQL Server backup to native Azure blobs as described in the previous section. Before adopting this strategy, I strongly recommend you to read the material contained at the link below:
Full File Backups (SQL Server)
https://msdn.microsoft.com/en-US/library/ms189860.aspx
File backups increase flexibility in scheduling and media handling over full database backups, which for very large databases can become unmanageable. The increased flexibility of file or filegroup backups is also useful for large databases that contain data that has varying update characteristics. The primary disadvantage of file backups compared to full database backups is the additional administrative complexity. Maintaining and keeping track of a complete set of these backups can be a time-consuming task that might outweigh the space requirements of full database backups.
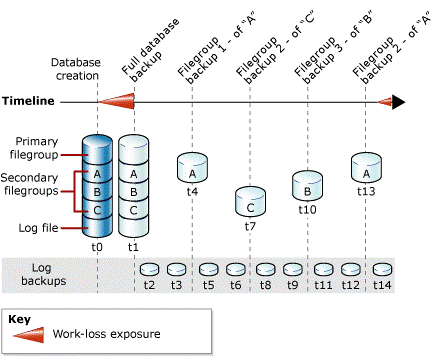
In the article I mentioned above, there is an example of backup plan that can be used to effectively leverage file level backup in SQL Server 2014. The most important limitation you need to be aware of is that only one file backup can run at any time, then you cannot run in parallel: total time for backup is obtained from the sum of the time to backup serially all single files for a specific database. Again, here the main bottleneck comes from throughput of a single blob. Additionally, in order to restore a database, you
need to ensure that transaction log backup is taken including the temporal interval starting from the beginning of first file backup, until the end of the last file. This feature can be absolutely used in conjunction with Backup Compression that I always recommend to use. As explained in the previous section, since we want the backup to be saved in a different Azure datacenter to prevent huge data loss caused by a wide disaster, which storage account you should use for storing backup? You can use one in the same local datacenter where your SQL Server instance resides, then relying on GRS to async replicate remotely, or you can copy manually using AZCOPY tool.
SQL Server Backup to Storage Pools (VM Disks)
The first option I mentioned above will save you on usage of Azure disks, while the second one will permit to backup up VLDB greater than 1TB, but both share a common problem: the limited bandwidth of a single Azure blob, that is 60MB/sec. on Standard Storage and 200MB/sec on Premium Storage. Since time required to complete a backup (full, differential, incremental) will affect your RPO, it is also important to consider alternatives that can use multiple blobs/disks at the same time to reduce completion time. One valid technical alternative is to use a subset of your VM attached disks to store your backup file: using Windows Server 2012 (and later) Storage Pool feature, you can create a logical volume on top of multiple Azure disks, then obtaining a multi-Terabyte unique disk where you can finally store a backup set larger than 1TB.
Best Practices & Disaster Recovery for Storage Spaces and Pools in Azure
Performance Best Practices for SQL Server in Azure Virtual Machines
https://msdn.microsoft.com/en-us/library/azure/dn133149.aspx
Which Azure storage account type I should use? If backup (and restore) time is critical for you, I would recommend using Premium Storage for backup disks to overcome the standard storage limits. Premium Storage comes with three different disk flavors, each one with its own IOPS and bandwidth limits:

Premium Storage: High-Performance Storage for Azure Virtual Machine Workloads
As explained in the article above, you need also to consider the VM bandwidth and use the appropriate VM size to ensure your compute resources will be able to drive full consumption of disk bandwidth and IOPS. For example, even with the most powerful DS-SERIES VM (STANDARD_DS14), you will be able to sustain only three P30 disks, if you consider the bandwidth or only ten P30 disks if you consider the IOPS. It is important to remember that SQL Server backup perform I/O sequentially, both reading from the source database and writing to the destination disks, in big chunks and then the number of real IOPS should be adjusted to consider 256KB for Premium Storage. Then, you consider primarily consider bandwidth on your backup calculations. Be careful here because you need to divide by two the maximum bandwidth associated with each DS-SERIES VM: you will use (in theory) half of the bandwidth to read from database disks, and the second half for writing to backup disks. NOTE: there is no governance that this split will be perfectly balanced between reads and writes. For backup tests and numbers using Premium Storage and DS-SERIES VMs, please read my blog post below:
Efficient SQL Server in Azure VM Backup Strategies using DS-SERIES and Premium Storage
Then, in an ideal situation, with a 4TB database and a STANDARD_DS14 VM (256MB/sec bandwidth to write backup stream) with three P30 disks, your full backup job can be theoretically completed in 4.55 hours (8,879TB/hour), without eventually considering Backup Compression that I always recommend to use. Using Standard storage account, the theoretical completion time should be 6.47 hours (42% slower) if you consider three disks with 60MB/sec bandwidth. However, there is a big caveat: while with Premium storage account bandwidth and IOPS are constant and consistent around the declared limits, there is no assurance that on Standard storage account you will be able to reach 60MB/sec limit. Using Premium Storage seems to be a compelling option, but you need to remember an important detail, that is storage content is LRS only and not geo-replicated! How can you safely and quickly deliver your backups to a remote Azure datacenter? You have essentially the following possibilities:
- Copy backup VM disks/blobs from Premium storage account to a local Standard geo-replicated (GRS) storage account and then rely on Azure async GRS replica;
- PROs: fast server side local copy for the Azure storage infrastructure;
- CONs: no SLA on GRS replica completion at the remote Azure datacenter;
- Copy backup VM disks/blobs from Premium storage account to a remote Standard (LRS) storage account;
- PROs: full knowledge and control on when the copy will be hardened and completed at the remote Azure datacenter;
- CONs: slower Azure storage backend operation, longer backup completion time;
Instead, if you use Standard storage accounts, backup operation in SQL Server will take longer to complete, but you could use GRS storage accounts underneath Storage Pools: in this way, your backup disks will be silently (but asynchronously) moved to the paired remote Azure datacenter without any additional step. This important consideration must be done when choosing the type of Azure storage account to use, each solution presents PROs and CONs, and your requirements must be considered.
SQL Server Native Backup Striping
For some strange reasons, this is one of the most unknown and unused feature in SQL Server. Anyway, since quite a long time ago, SQL Server can stripe backup over multiple backup files, something like this:
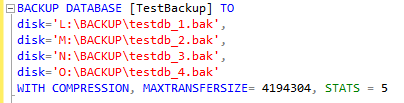
If the original database is about 4TB, for example, this command will stripe the content of the backup operation over different disks/files, thus reducing each slice to <1TB and then can be allocated on Azure disks without any problem. The first advantage of this approach is that you do not need to use Storage Pools to build a >1TB backup logical volume. The second important one is that you now have individual backup files <1TB size, then you can use tools like AZCOPY to “archive” on Azure blobs in a different storage account and/or different Azure datacenter and/or with GRS/LRS enabled. Same considerations I have shared with you, previously in this post, regarding Standard vs. Premium, LRS vs. GRS and backup performances and completion time, still apply in this case. AZCOPY is a great tool since it is asynchronous (by default), parallel, and restartable. It can also trigger Azure backend-only copies when used between Azure storage accounts. In our case, you can do something like the command line below to move a SQL Server backup file from a local disk to a remote/external blob:
AZCOPY.EXE /Source:X:\backup\ /Dest:https://mystorageaccount1.blob.core.windows.net/backup/ /Destkey:<destination storage key> /Pattern:*.BAK
Getting Started with the AzCopy Command-Line Utility
http://azure.microsoft.com/en-us/documentation/articles/storage-use-azcopy
Great tool, but you need to be aware of the following fact: AZCOPY, when used inside a VM to copy a local file to a blob on Azure storage, will use storage bandwidth to read data and will use network bandwidth to write data! Officially Azure does not provide network bandwidth limits per VM size, but you can certainly argue (and test yourself!) that the bigger the VM is (#cores) the higher network bandwidth will be. Regarding storage bandwidth, officially documented only for DS-SERIES and Premium Storage, is there any way to avoid wasting it for backup operations and save for your transaction workload? Yes, there is a way sometimes and I’m going to explain in the next section.
SQL Server Backup to Local SSD drive
As you probably know already, local “D:” (on Windows) drive on Azure VMs is ephemeral, then content can be lost and nothing you care should be placed here. But exactly when the content is lost? Well, according to various documentations, content is not lost
when you simply reboot your VM or Azure Host maintenance happens, but this event may happen if you shut down the VM with de-allocation (default behavior in PowerShell and the Portal), you resize the VM or if a crash will happen at the Azure Host level. Then, local SSD drive wipe is not so frequent and you can leverage in an intelligent way. Remember that first of all is SSD, it is locally attached storage, then low latency and high-throughput, finally IOPS do not count toward VM (Premium) storage bandwidth quotas. What you can essentially do is storage full backup of your big SQL Server database on the local SSD “D:” drive, then use a tool as AZCOPY to copy remotely to another storage account, in the same or different datacenters, depending on what you want to achieve in terms of backup offsite storage strategy. Let me emphasize again this important fact: on a DS14 VM, for example, you have 512MB/s storage bandwidth, but if you need to read and write from Azure persistent storage, you will have contention. Conversely, if you read from Azure storage (where the database is allocated) but write to local SSD, you can write at the maximum speed, that is the minimum between Azure VM and Premium Storage bandwidth and the SSD bandwidth. The most extreme performance possible is with a DS14 VM that drives un-cached Premium Storage disks to the limit of 50,000 IOPs (where the database resides) and the SSD cache to its limit of 64,000 IOPs for a total of over 100,000 IOPs.
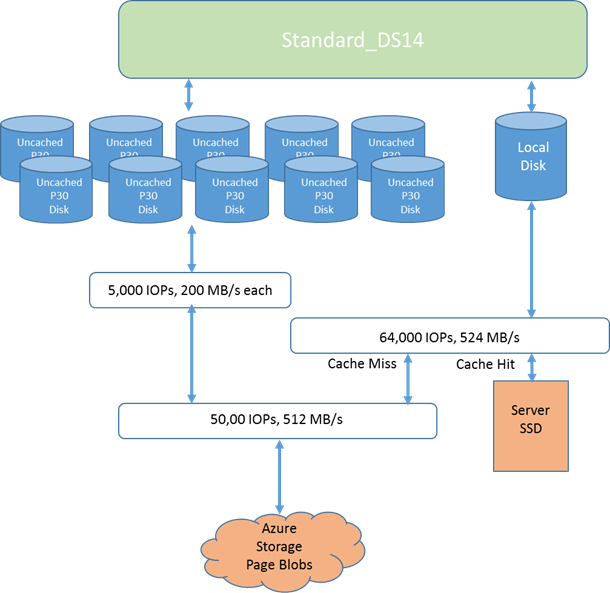
How fast can be the local SSD? You can read the details in the blog post below by Mark Russinovich, essentially the SSD performances are tied to the size (in cores) of the VM:
Azure Premium Storage, now generally available
http://azure.microsoft.com/blog/2015/04/16/azure-premium-storage-now-generally-available-2
On DS14, for example, you will have up to 64K IOPS and 524MB bandwidth, if you will not use Blob Cache for other purposes (should not in SQL Server). It means an average of 4K IOPS and 32MB/sec (approximately) per single core. There is still an important
consideration to do here: remember that I focused here on multi-terabyte database backup, but if you look at the DS-Series VM specs, you will see that the maximum amount of local SSD is 224GB, on DS14. I still wanted to cover this possibility because you may use this strategy with incremental transaction log backups or file/file-group level backups. On the other hand, if you decide to use G-Series VMs, you can have up to 6TB of local SSD, even if Premium Storage is not (yet) available here.
SQL Server AlwaysOn Availability Groups (AG)
AlwaysOn Availability Groups (AG) is a SQL Server technology widely used on-premise to provide high-availability instead of, or in conjunction with, Windows Server Failover Clustering. In Azure VMs AG is always used since it is the only technology actually supported. In addition to HA, a nice feature of AG is the possibility to “offload” database backups to the secondary instance of SQL Server, then not touching at all the primary instance. Additionally, each SQL Server instance (1 Primary + (n) secondaries) will have separate storage and separate Azure VM storage bandwidth. Then, why not using one of the SQL Server secondary instance as a source for database backup? You can leverage one of the strategies I mentioned previously in this post and also have additional
benefits. If you have a secondary instance in a remote Azure datacenter, for example, you can backup to local Azure storage without requiring GRS since you are already in a different location from the primary. Or you may think to backup to local SSD only, without using AZCOPY since you are already in a different datacenter. In this case, remember that local SSD is ephemeral. If you want to learn more about AlwaysOn AG in Azure, you can read my blog post below:
SQL Server 2014 High-Availability and Multi-Datacenter Disaster Recovery with Multiple Azure ILBs

Azure Storage Level Snapshot Backup
“Snapshot” is a very nice Azure storage feature that will permit you to have a “frozen” logical image of a blob/disk at a specific point in time. Physically, it is another blob that will store blob page versions before write changes. Creating a snapshot on an Azure blob/disk is a very fast operation since it is pure logical and server-side executed, Azure storage infrastructure will take care of “copy-on-write” mechanism without touching your VM IOPS or bandwidth thresholds. Be aware that this is very different from on-premise SAN hardware snapshots or Virtual Shadow Copy (VSS) software based snapshots, there is no coordination with SQL Server to ensure transactionally consistent backups. Then, how to leverage this mechanism even with this important limitation? The logical steps to perform this kind of backups are essentially: stop SQL Server service, or take offline the specific database, then create a disk snapshot for every disk used, then restart SQL Server or bring back online the database. When you create the snapshot, it is critical that no activity will be placed on the database, otherwise you may have a logically inconsistent backup. This kind of backup is called “off-line backup” or “cold backup” in DBA terminology and it is not used generally in the on-premise world. The reason is simple: SQL Server, since the very beginning of his history, is able to do on-line backups then why taking the database offline since it will cause service/application downtime? In Azure, and public cloud in general, you don’t have powerful SAN system and you have to deal with bandwidth and other storage limitations, then if you have a very big database in the Terabyte range, this may be the only viable option. Remember that I just told you at the beginning of this section that creating a snapshot is pretty fast, then downtime will be minimal. Now that you have your snapshots for every disk where SQL Server reside, what you should do? An interesting characteristic of Azure storage snapshots is that you can copy them, also in different storage accounts with GRS enabled, and generate new independent blobs. The advantage here is that this copy operation will not involve the VM, it is an Azure storage infrastructure backend operation that will run asynchronously, and SQL Server can be online without any consistency problem. Once copied, it is highly recommended to drop the snapshots. At this point, I exposed all the technical details and probably some experienced DBA will argue that this approach can be used only for database in SIMPLE recovery mode. This is absolutely correct: if you don’t use native SQL Server built-in backup feature (BACKUP TSQL statement for your understanding), SQL Server will not realize that a full (even offline) backup has been taken and will prohibit subsequent incremental transaction log backups. Without
incremental transaction log backup, your RPO will be eventually high since you will lose all data between the two snapshot operations. Additionally, database transaction log will growth forever since cannot be truncated, and you easily imagine this is not a viable option. My recommendation here is only to use this approach if nothing else will work due to the size of the database, putting a database in SIMPLE recovery mode is not generally recommended since may involve huge data loss and no point-in-time restore will be possible. The same considerations I have just written here also apply in the scenario where you don’t use Azure VM disks and place SQL Server database files directly on Azure blob storage. For more information on this scenario, you can read my white-paper below:
New White-Paper on SQL Server 2014 and Azure Blob storage integration
Azure Backup (VM level snapshot)
Azure Backup is a new service recently announced that would permit users to take Azure Virtual Machines backup at the storage infrastructure level. This technology aims to provide application level (then SQL Server) consistency for Windows Server OS leveraging the Azure Fabric built-in capabilities.
Back up Azure virtual machines
https://azure.microsoft.com/en-us/documentation/articles/backup-azure-vms

Essentially, you will simply tell the Azure Fabric to take storage snapshot of all VM disks, you are not requested to do anything else, even at the SQL Server level. The advantage of this solution is that Azure infrastructure will take care of everything in a consistent way, but there is an important drawback: as described previously, from a SQL Server perspective this is an “off-line” backup and will not permit incremental backups or point-in-time restore. You will be able to restore the entire VM, not only the SQL Server database, only at the point the snapshot has been taken.
SQL Server 2016 Native Backup in Azure (preview)
In the previous section “SQL Server Backup to Windows Azure Blob Storage Service”, I introduced you to the possibility for SQL Server to store backups directly on Azure blob storage without using VM disks. This feature suffers, on SQL 2012 and 2014, from two important limitations: only one blob can be used as target, and the blob (page blog) can be only 1TB maximum size. In SQL Server 2016, still in preview, Microsoft is aiming to solve both these limitations: block blob will be used instead of page blob, drastically reducing single blob limit to 200GB, but will allow multiple targets, that is the possibility to use multiple blobs to storage your backup data.
Understanding Block Blobs and Page Blobs
https://msdn.microsoft.com/en-us/library/azure/ee691964.aspx
Additionally, a new backup method will be introduced: backup to file snapshot feature creates a snapshot of the your data files, directly created on Azure blobs, and then creates the backup directly leveraging Azure storage snapshot capabilities, then speeding up the backup process. SQL Server 2016 is still in preview, you can download CTP2 (July 2015) from the link below:
SQL Server 2016 Upgrade Advisor Preview and CTP 2.2 now available
I promise you to write very soon a specific blog post on these enhancements, if everything will work as expected, multi-Terabyte SQL Server database backups will be much easier in Azure Virtual Machines. That’s all folks, let me know about your feedbacks and experiences, you can also follow me on Twitter ( @igorpag).
Regards.