Efficient SQL Server in Azure VM Backup Strategies using DS-SERIES and Premium Storage
With the advent of DS-SERIES and GS-SERIES with Premium Storage, now running big databases in Azure Virtual Machines (VM) is a reality, something that was not fully achievable until few months ago. You now have the power to run up to 64 x 1TB disks and use 32 cores horse-power, with about half Terabyte of memory, or you can obtain up to 114K IOPS from Azure Premium Storage and its Blob cache mechanism. However, big database requires special attention for management: how do you intend to backup “efficiently” such big databases? In this article, I will focus the attention on DS-SERIES and Premium Storage, providing SQL Server backup performance test results and best practices.
IMPORTANT: These tests are not official, results are provided “as-is” and may originate different numbers over time.
Test Configuration
I used the following configuration for my test VM:
- Database size: 50GB;
- VM SKU and size: DS-SERIES DS14;
- 16 cores, 112GB RAM, 512MB/sec max disk bandwidth, 223GB local SSD;
- OS: Windows Server 2012 R2;
- SQL Server: SQL Server 2014 Service Pack 1;
- Disk caching disabled on all disks, both source for database hosting and target backup;
- Azure Premium Storage used:
- 10 P30 disks (1TB) for database files and transactions logs grouped in a single
Storage Pool; - 1 P30 disk (1TB) (OPTION[1])
- 5 P30 disks (1TB) for backup (OPTION[2]) grouped in a single Storage Pool;
- 10 P30 disks (1TB) for database files and transactions logs grouped in a single
- Local SSD storage
- Full backup to local ephemeral SSD storage (OPTION[3]);
For brevity, I didn’t report test results for striped SQL Server backup over multiple Premium disks: results obtained differ only minimally from OPTION [2] scenario mentioned above. For the Storage Pool configuration, I followed the recommendations in the paper below:
Performance Best Practices for SQL Server in Azure Virtual Machines
https://msdn.microsoft.com/en-us/library/azure/dn133149.aspx
For Premium Storage sizing, capacity planning and capabilities, I used references from the article below:
Premium Storage: High-Performance Storage for Azure Virtual Machine Workloads
https://azure.microsoft.com/en-us/documentation/articles/storage-premium-storage-preview-portal
Test Goal
Since I decided to use DS-SERIES SKU and Standard_D14 size, as you can read in the page below, my goal is to obtain a SQL backup Throughput as close as possible to the theoretical VM bandwidth for Premium Storage, that is 512MB/sec:
Virtual Machine and Cloud Service Sizes for Azure
https://msdn.microsoft.com/en-us/library/azure/dn197896.aspx
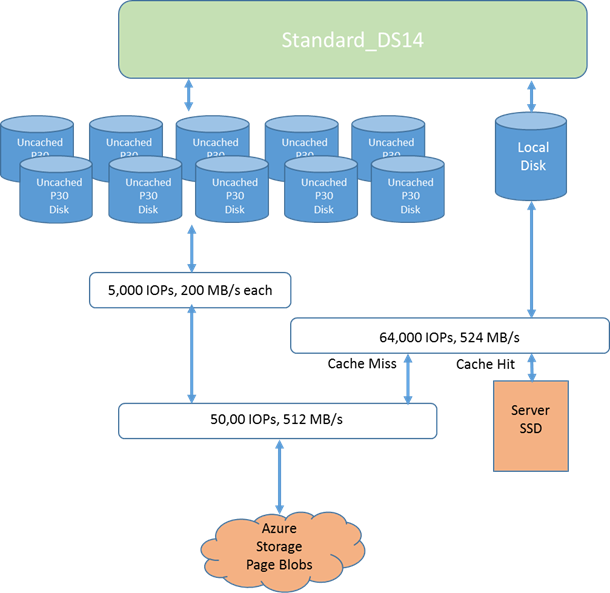
In reality, our target need to be adjusted to 512/2 = 256MB/sec. The reason is simple: during backup operation, SQL Server will need to read from the 5 P30 disks where the database is located, and will need to write at the same time to other Premium disks (depending on the test configuration). Both these operations will consume and compete for the same storage bandwidth. Don’t be wrong here: there is no governance to ensure that read and write I/O will be balanced exactly 50/50.
First Test
I started my first test series with the simplest one that is using a single P30 disk as the target for my SQL full backup operation:

As you can see from the result above, throughput achieved by SQL Server backup using a single P30 disks as target is somewhat surprisingly and not satisfactory at all. As you can read from previous links I mentioned above, a single P30 disks should provide 5K IOPS and 200MB/sec throughput. Since this is my very first “touch” on this new P30 disk, let’s try again exactly the same BACKUP command:

At the third trial, I obtained the result below that seems pretty stable:
BACKUP DATABASE successfully processed 5122010 pages in 243.504 seconds (164.332 MB/sec).
NOTE: Depending on the workload currently running on the VM, Read operations using Blob Cache may take some time to reach the peak performance since the cache needs to build up for providing extremely low latency for Read operations.
At this point we obtained 164MB/sec throughput, let try a small configuration change to see if we can improve. Please remember that a single P30 disk has a maximum throughput of 200MB/sec. In the next test, I will try to use multiple backup files (SQL Server backup striping), still on the same unique P30 disk as target for the backup:

In the example above, I used a SQL Server striped backup set composed by four backup files and obtained an excellent 191.602 MB/sec throughput that is very close to the single P30 disk limit of 200MB. What is changed here? Looking at the Windows Server performance counters, I noticed that with a single backup file, the output queue length for the backup target disk was pretty low, between 2-4. Using four backup files instead, placed more pressure on the storage subsystem (queue length 16-20).
Second Test
Now let’s try to use, as the target for SQL Server backup operations, a Windows Server 2012 R2 Storage Pool to aggregate five P30 Premium Storage disks, only one backup file used to establish baseline of this new configuration:

The result obtained is a poor 177.459 MB/sec that is slightly lower than using a single P30 disk as in the previous test. Using the lesson learned before, now I’m going to use multiple backup files placed on the virtual disk created from the Storage Pool. Let’s try using 20
backup files, that is five per physical disk:
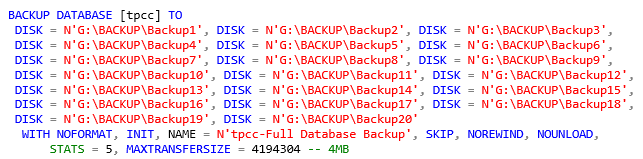
As expected, this test scored an excellent 247.155 MB/sec that is very close to the theoretical limit of 256MB/sec we established as a goal to the beginning. As this point, you may argue if it is really necessary to use, as I have done, five P30 disks and Storage Pool: based
on some other tests I have done, the answer is “NO”. I had to use this specific customer configuration, but I was able to reach the same optimal performances with two P30 disks, no Storage Pool and eight total backup files (four for each disk). NOTE: In the test above I was able to achieve the same throughput using only ten and eight backup files.
Third Test
Finally, I want to measure the throughput obtainable using the local ephemeral SSD drive on DS-SERIES. I know that this disk content may be lost, but as I will explain in a future post, sometimes may be useful to leverage also this Azure capability. As a starting point to
establish a baseline, let’s use a single backup file as target:

With these two backup files, I obtained variable results between 300MB/sec and 400MB/sec. I also tried to use more files (four and eight) but throughput suddenly decreased to less than 100MB/sec. The reason is simple: local SSD is a shared resource and there is a governance on usage, if you cross certain limits, throttling will happen. Finally, keep in mind that there is no SLA/SLO on performances of local SSD disk, then results may vary over time.
Lessons Learned & Best Practices
Let me recap findings of these tests and some recommendations on SQL Server backup for Azure VMs using Premium Storage:
- Disable “Host Caching” for Premium Storage disks used as backup targets;
- Based on my previous test experience, confirmed also this time, MAXTRANSFERSIZE parameter in TSQL backup statement can be greatly beneficial when configured at the maximum value, that is 4MB.
- Conversely, tweaking BUFFERCOUNT parameter is not beneficial, sometimes will also lead to worst performances, then leave it unspecified then SQL Server will use default values.
- Formatting backup disks using 64KB provides some minimal benefits, then why not using it.
- Even on Premium Storage is recommended, if possible, to warm-up disks for optimal performances.
- Using Windows Server Storage Pools for SQL Server backup is not necessary to achieve optimal backup performances.
- For SQL Server backup, MB/sec throughput matters for proper sizing and capacity planning, not IOPS;
- The optimal number and size (P10, P20, P30) of Premium Storage disks to use for backup are based on VM storage bandwidth: use only the minimal number necessary to saturate VM bandwidth (i.e. = 2 P30 for DS14).
- Use multiple backup files and leverage SQL Server backup striping capability: optimal number of files is 4 for each physical disk, up to 8 in total.
- If using local SSD for SQL Server backup, do not use more than 2 backup files.
As specified at the beginning of this article, it is highly recommended to enable compression for SQL Server backup.
SQL Server Backup internals
In SQL Server 2012 (and later versions), the engine will choose backup parameter values based on number of source and destination files/disks. In order to have more details on backup internals, it’s possible to use the following trace flags and obtain an output, from SQL Server ERRORLOG, similar to the one below:
- Trace Flag 3004: outputs what operations Backup and Restore are performing;
- Trace Flag 3014: outputs additional information about Backup and File operations;
- Trace Flag 3213: outputs the Backup Buffer configuration information;
- Trace Flag 3605: required to force the output into the error log;
Here is an example of what you will see once these trace flags will be enabled:
Backup: DBReaderCount = 4
Memory limit: 895MB
BufferCount: 13
Sets of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 13 MB
Tabular data device count: 4
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem I/O alignment: 512
Media Buffer count: 13
Media Buffer size: 1024KB
Hope you will find this content useful; you can follow me also on Twitter ( @igorpag). Regards.