Microsoft Azure Universal Storage for SQL Server 2014
I finally decided to write this blog post after the recent announcement, at last US TechEd in May, of a new Azure Storage feature called “Azure Files”, that is the possibility to mount Azure Blob storage as SMB shares inside Azure IaaS Virtual Machines (VM). Now, you have three different way (Azure Files, Azure Disks, and Azure Blobs) to allocate your SQL Server 2014 database files in Azure and might be useful to have a clear understanding of the PROs and CONs of each method, performance targets and limits, along with some recommendations on typical usage scenarios. In the context of this blog post, I will refer to SQL Server 2014 running inside an Azure IaaS Virtual Machine (VM).
Before mentioning and comparing each one, if you want to know more about “Azure Files”, I would recommend you to see this TechEd Session on Channel 9, along with the official blog post from Brad Calder and his team:
Introducing Microsoft Azure File Service
Microsoft Azure Storage
https://channel9.msdn.com/Events/TechEd/NorthAmerica/2014/DCIM-B384#fbid=
Since all the three features that I’m going to discuss are related to Azure Storage, even if under different forms, it’s always important to keep in mind the ultimate scalability targets mentioned in the link below:
Azure Storage Scalability and Performance Targets
http://msdn.microsoft.com/library/azure/dn249410.aspx
Azure Files
Since it is completely new, and actually still in preview, let’s start with some details on how “Azure Files” works. The concept is very simple and involves exposing Azure Blob storage using SMB 2.1 interface: it is worth mentioning that “Azure Files” is a separate Azure service that is built on top of well-known Azure Storage stack. If you want to talk to this service, you have to use a separate and new endpoint (see below) that is provided once you create a new Azure Storage account with preview access to this feature enabled:
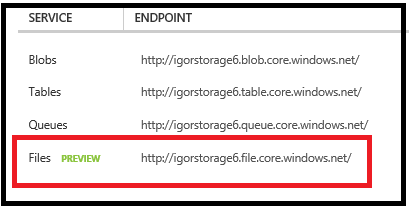
Please note that SMB used here is version 2.1, which is the one used in Windows Server 2008 R2 Service Pack 1, not the latest version 3.0 introduced in Windows Server 2012: this is very important to notice because v2.1 is not encrypted, that’s why access to Azure Blob storage, using SMB, is restricted to the same Azure datacenter, while access using REST interfaces does not suffer from this limitation, HTTPS is used in this case. Once you have created a new storage account with “Azure Files” enabled, you can start using it inside an Azure VM using the most traditional and NT-styled command below:

I really like the way the Azure Storage development team adapted NET USE syntax to use the Azure Blob Storage. Please note that the file server URL is composed by the Azure Storage endpoint, plus the storage account name (and obviously the share name), the user you have to use is the storage account name itself and the password is the storage secret (master key)! This logic is fluent, simple and in my personal opinion is great.
NOTE: In order to create the share for the new “Azure Files” feature, since it is still in preview, you have to use PowerShell script and a special setup procedure, as explained in the FAQ contained in the first link I mentioned at the beginning of this post.
Now, let me spend some words to describe you a very annoying problem I found during my tests: even if you try to use the “/PERSISTENT:YES” switch in “NET USE” command, after reboot Windows Server will not be able to automatically reconnect the SMB Shares.

I solved the problem using a SQL DBA approach, but just today, I saw a new blog post from my colleague Andrew Edwards from the Azure Storage team that I want to recommend you:
Persisting connections to Microsoft Azure Files
In short, the approach here is to save credentials required to connect to the “Azure Files” SMB share using CMDKEY command line tool:
Cmdkey /add:<yourstorageaccountname>.file.core.windows.net /user:<yourstorageaccountname>
/pass:<YourStorageAccountKeyWhichEndsIn==>
Now, once you will run NET USE, SMB network shares will be automatically re-connected and SQL Server databases created there will come up online without requiring NET USE execution anymore.What is really unique in this feature, is the possibility for more VMs to mount and use the same Azure storage at the same time: all the VMs will have read/write access to the same SMB share but remember that, since we are talking about SQL Server, each data or log file can be mounted only by one SQL Server instance at any time.
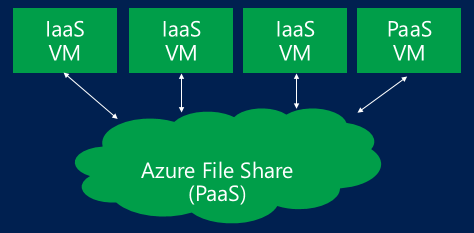
Even with this limitation, this feature is interesting because it is very easy to detach a SQL database from one SQL VM and mount on a different one, then you may want to consider this aspect. Be very careful with your VM network bandwidth: if you use this feature, then SMB, you are going to consume Azure network bandwidth, not storage bandwidth! Since Azure, today, only provide a single network interface, you cannot distinguish incoming application traffic from SMB traffic accessing the storage, then you need to do some maths to be sure you will have enough network power. Also, note that is you are going to use AlwaysOn Availability group for high-availability and/or disaster recovery, this will also count toward network bandwidth usage. If you are a SQL guy, you know for sure that SQL Server supports creating database on SMB shares since version 2012 as reported in the link below:
Install SQL Server with SMB Fileshare as a Storage Option
http://msdn.microsoft.com/en-us/library/hh759341(v=sql.120).aspx
Then, why not using SMB UNC path directly instead of mounting disk volumes with NET USE and waste a drive letter? Unfortunately, you (and SQL Server) cannot access the “Azure Files” SMB share without mounting the share explicitly, each time after each VM reboot: there is no limit imposed by Azure on the number of SMB shares you can mount, but in this specific context you are limited to the drive letters available inside the Guest OS image.
IMPORTANT: If you are going to use Windows Server 2008 R2 as Guest OS, be sure to have the following hotfix applied:
Slow SQL Online Transaction Processing performance when SQL database files are stored on an SMB network file share in Windows 7, in Windows Server 2008 R2, or in Windows Storage Server 2008 R2
http://support.microsoft.com/kb/2536493
Finally, here are some very useful numbers on scalability, performances and limits; I will provide more details in the final comparison table:
- Up to 5TB per share
- A file can be up to 1 TB
- Up to 1000 IOPS (of size 8KB) per share
- Up to 60MBps per share of data transfer for large IOs
IMPORTANT: This feature is still in preview, and then the numbers above may change in the future.
Azure Data Disks
“Azure Data Disks” was the first and it is the most traditional way to attach more storage to an Azure VM and scale not only on the amount of space, but on the maximum number of IOPS for your SQL Server instance: you can read more about this feature at the link below:
How to Attach a Data Disk to a Virtual Machine
http://azure.microsoft.com/en-us/documentation/articles/storage-windows-attach-disk
They are essentially VHD files stored in Azure Blob storage (page blob type) with a maximum size of 1TB, 500 IOPS target performance for Standard VM SKU and 300 IOPS for Basic VM SKU. Finally, there is a limit on the maximum number you can attach to each VM size, as reported at the link below (max = 16):
Virtual Machine and Cloud Service Sizes for Azure
http://msdn.microsoft.com/en-us/library/azure/dn197896.aspx
The first (and most important) consideration that apply for this specific feature, compared to the others mentioned in this post, is that you are going to consume storage bandwidth and not network bandwidth: if you are already constrained on network bandwidth usage, you should use “Azure Data Disks” first, then use “Azure Blobs” or “Azure Files” if you need more disk space and/or IOPS for your SQL Server databases. Second consideration applies to SQL Server database transaction log: independently of which Azure storage feature you are going to use, there is always a limit on single file/blob IOPS, which is 500 for Standard VM SKUs (and 300 for Basic VM SKUs) and as you know for sure, SQL Server can only use one single transaction log file at any time. Then, how to scale up if 500 IOPS are not sufficient? Since today Azure does not provide (yet) something similar to AWS “Provisioned IOPS”, the only possible solution is to use Windows Server 2012 (or R2) “Storage Spaces” feature and group together multiple Azure disks at the Guest OS level. Be careful on this approach is scalable, you can read about this solution and related performance targets, in the white paper below:
Performance Guidance for SQL Server in Windows Azure Virtual Machines
http://msdn.microsoft.com/en-us/library/dn248436.aspx
Azure Blobs
This is my favorite SQL Server 2014 feature, I wrote 116-pages white paper on that, you can download from official SQL Server MSDN page here:
New White-Paper on SQL Server 2014 and Azure Blob storage integration
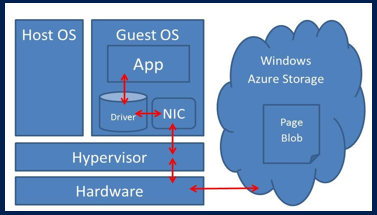
Starting version 2014, SQL Server is able to directly using Azure Blob storage at the storage engine level (see the image below), then not requiring users to create and attach “Azure Data Disks”:
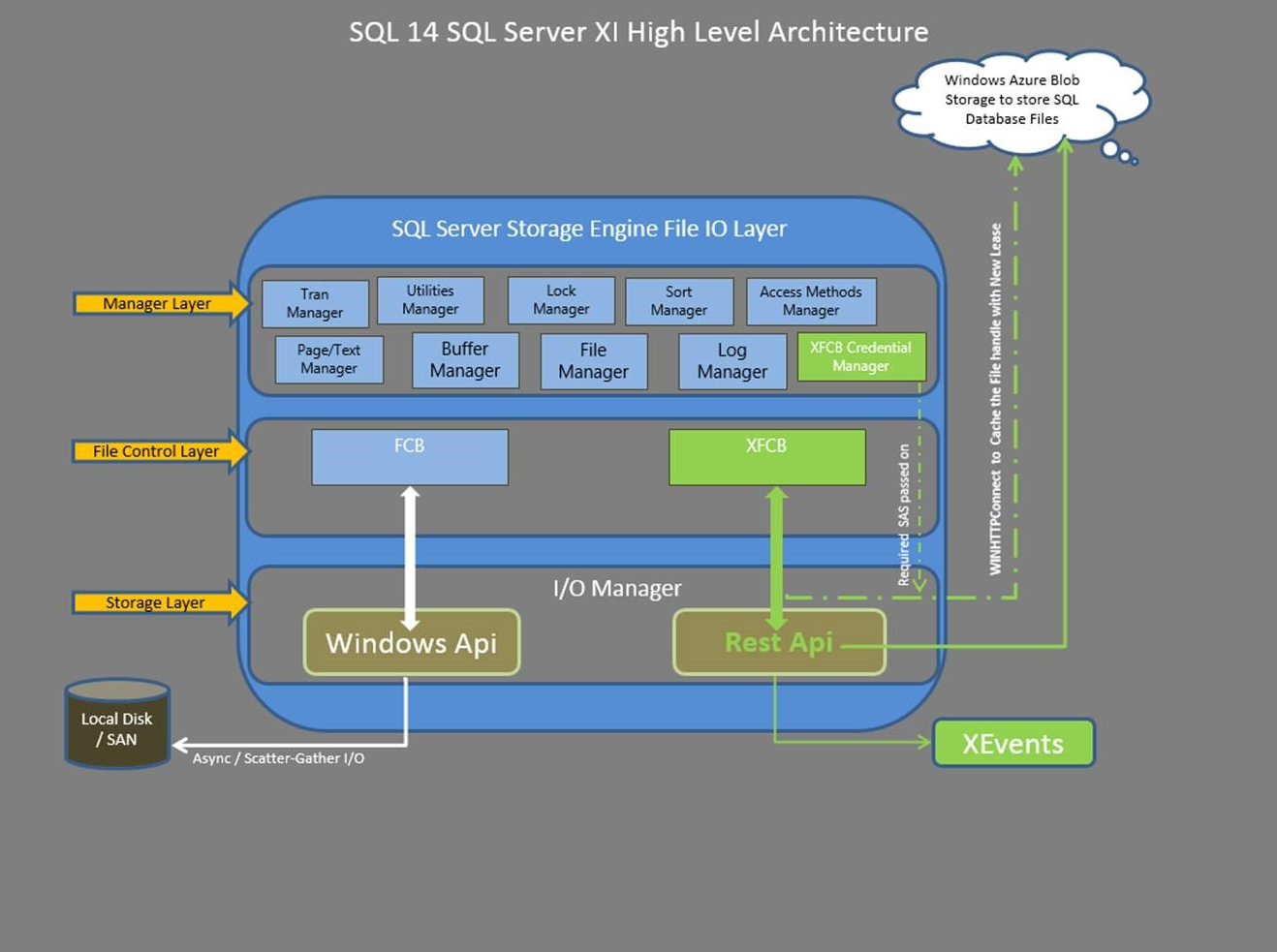
The first consequence is that you are not limited to 16 disks (for A4, A7, A8 and A9 VM SKUs) anymore, in theory you can add up to 32767 SQL Server files, 1TB each. As for “Azure Files”, it is important to note that here you are going to use VM network bandwidth, not storage bandwidth as for “Azure Data Disks”. The path to Windows Azure Storage is different using this new feature. If you use the Windows Azure data disk and then create a database on it, I/O traffic passes through the Virtual Disk Driver on the Windows Azure Host node. However, if you use SQL Server Data Files in Windows Azure, I/O traffic uses the Virtual Network Driver.
You can read full details inside my white paper, but let me list here main PROs and CONs of this specific feature:
PROs
- It is possible to scale on the number of IOPS, on database data files, far beyond the (500 IOPS x 16 disks) = 8000 IOPS limit imposed by usage of Windows Azure additional disks.
- Databases can be easily detached and migrated or moved to different virtual machines (that is, portability).
- Standby SQL Server virtual machines can be easily used for fast disaster recovery.
- You can easily implement custom failover mechanisms; in the white paper, you can find a complete example.
- This mechanism is almost orthogonal to all main SQL Server 2014 features (such as AlwaysOn and backup and restore) and it is well integrated into the SQL Server management tools like SQL Server Management Studio, SMO, and SQL Server PowerShell.
- You can have a fully encrypted database with decryption only occurring on compute instance but not in a storage instance. In other words, using this new enhancement, you can encrypt all data in public cloud using Transparent Data Encryption (TDE) certificates, which are physically separated from the data. The TDE keys can be stored in the master database, which is stored locally in your physically secure on-premises machine and backed up locally. You can use these local keys to encrypt the data, which resides in Windows Azure Storage. If your cloud storage account credentials are stolen, your data still stays secure because the TDE certificates always reside on-premises.
CONs
- I/O generated against single database files, using SQL Server Data Files in Windows Azure, count against network bandwidth allocated to the virtual machine and pass through the same single network interface card used to receive client/application traffic.
- It is not possible to scale on the number of IOPS on the single transaction log file. Instead, using Windows Azure data disks, you can use the Windows Server 2012 Storage Spaces feature and then stripe up to four disks to improve performance.
- Geo-replication for database file blobs is not supported. Note: Even if you are using traditional Windows Azure data disks, geo-replication is not supported if more than one single disk is used to contain all data files and transaction log file together.
Comparison Table
Now that you have intimate knowledge of each feature, let me recap the major characteristics of each solution:
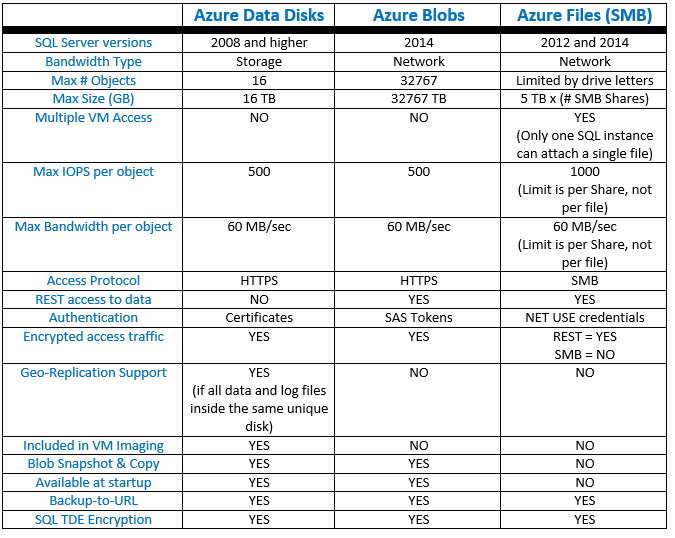
Then, which one to use?
At the end, this is the most important question. The table above should help you, but let me emphasize some important considerations. Storage and Network bandwidth are very limited resources, then you should pay great attention to what you are consuming: if your workload is huge in terms of storage IOPS, you should leverage first “Azure Data Disks”, then “Azure Blobs” if you need more space or bandwidth. Additionally, if you have huge network application traffic and/or using AlwaysOn Availability Group, which in turn consume network bandwidth, you must be very careful in using “Azure Files” or “Azure Blobs” since these also use network bandwidth. Finally, let me be honest about using “Azure Files”: since you will not ave greater IOPS and since SQL Server 2014 can already use “Azure Blobs” directly to scale above “Azure Data Disks”, I do not see any reason to use “Azure Files”! The only exception would be for SQL Server 2012: since here “Azure Blobs” is not supported, if you need more IOPS and /or disk space, there is no other way except using “Azure Files”.
That's all for this post, remember that you can follow me on Twitter ( @igorpag ). Regards.