Kinect For Windows Sensor + SDK - その4 深度情報と実画像のマッピング
その3のポストの最後に挙げた写真、注意深く見ると、深度と実画像の重ねあわせが微妙にずれている・・・なんて思いませんか?
実はずれているんです。深度画像のフォーマットと実画像のフォーマットをもう一度おさらいすると、
深度画像
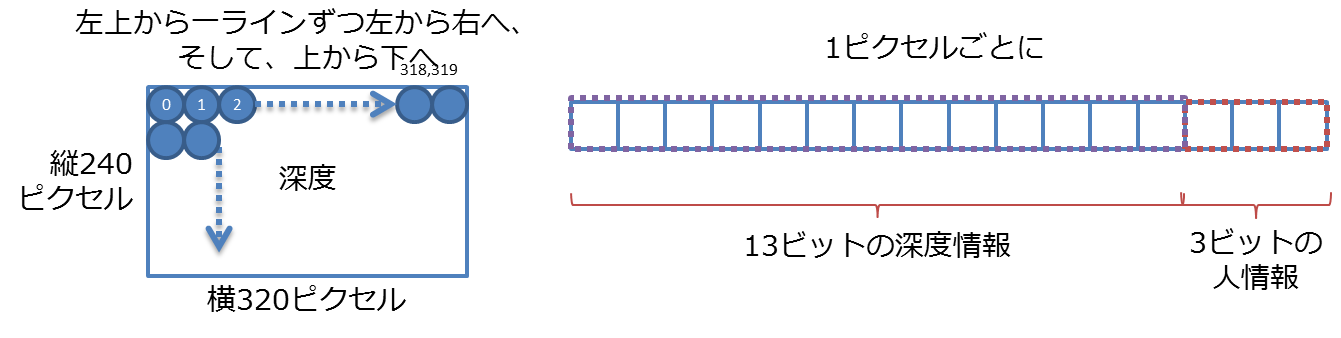
実画像

というデータ列です。縦横のピクセル数を比較すれば一目瞭然、2倍ずつ異なるので、私のような画像処理と数学をちょっとだけ齧ったような輩は「じゃあ深度の各ピクセルを2倍にして重ねればいいじゃん!」なんて浅はかな考えを持ってしまいます。例えばこんな感じ。
for (int i16 = 0; i16 < depthFrame.Length ; i16++, i32 += 4)
{
int player = depthFrame[i16] & DepthImageFrame.PlayerIndexBitmask;
int realDepth = depthFrame[i16] >> DepthImageFrame.PlayerIndexBitmaskWidth;
byte redIntensity = 0;
byte greenIntensity = 0;
byte blueIntensity = 0;
// playerとrealDepthを元に、各点の色合いを決めて、redintensity,greenIntensity,blueIntensityを決める。詳細は割愛
int x = i16 % picxelWidth;
int y = i16 / picxelWidth;
for (int ix = 0; ix < 2; ix++)
{
for (int iy = 0; iy < 2; iy++)
{
int pos = 4 * (2 * picxelWidth * (2 * y + iy) + 2 * x + ix);
colorData[pos + RedIndex] = redIntensity;
colorData[pos + GreenIndex] = greenIntensity;
colorData[pos + BlueIndex] = blueIntensity;
}
}
}
こんな計算をやって、書いたのがその3の最後の写真です。
実際には、深度情報と、実画像の重なり具合はずれているので、そのまま2倍などにして重ね合わせてしまうと、画像がずれてしまいます。これは深度情報だけでなくスケルトンで得られる座標でも同じです。
KinectのAPIをよ~く見てみると、深度情報の座標を実画像の座標に変換してマップしてくれるメソッドが用意されています。それを使えば、複雑な計算をすることなく、実画像上での深度情報の各ピクセルの位置を得ることが出来るわけです。
その3で説明したDepthStreamのイベントハンドラのコードを以下の用に修正します。
private ColorImagePoint[] mappedDepthData;
void mySensor_DepthFrameReady(object sender, DepthImageFrameReadyEventArgs e)
{
KinectSensor kinectSensor = (KinectSensor)sender;
SkeltonField.Children.Clear();
using (DepthImageFrame depthFrame = e.OpenDepthImageFrame())
{
if (depthFrame != null)
{
using (ColorImageFrame colorFrame = ((KinectSensor)sender).ColorStream.OpenNextFrame(0))
{
if (colorFrame != null)
{
bool formatChanged = (lastDepthImageFormat != depthFrame.Format);
if (formatChanged)
{
depthData = new short[depthFrame.PixelDataLength];
mappedDepthData = new ColorImagePoint[depthFrame.PixelDataLength];
lastDepthImageFormat = depthFrame.Format;
}
depthFrame.CopyPixelDataTo(depthData);
formatChanged = (lastColorImageFormat != colorFrame.Format);
if (formatChanged)
{
colorFrame32 = new byte[colorFrame.PixelDataLength];
lastColorImageFormat = colorFrame.Format;
}
colorFrame.CopyPixelDataTo(colorFrame32);
kinectSensor.MapDepthFrameToColorFrame(depthFrame.Format, depthData, colorFrame.Format, mappedDepthData);
赤で記載したMapDepthFrameToColorFrame()メソッドが、深度情報を実画像に変換してくれるメソッドです。depthDataは、DepthFrameから取得した320×240のshort配列に格納されたデータ列です。深度情報のフォーマットと、実画像情報のフォーマットを指定してやると、ColorImagePoint型の配列にマップ後のデータを格納してくれます。
ColorImagePoint型は、X座標、Y座標のプロパティを持っています。
深度情報(320×240)の平面上の座標(dx、dy)の深度情報は、depthData配列には、dx+320×dy番目に入っています。mappedDepthDataには、同じ順番の場所に、(dx,dy)を実画像(640×320)上の座標に変換した値が入っています。なので
実画像座標(mappedDepthData[dx+320*dy].X, mappedDepthData[dx+320*dy].Y)の深度は、depthData[dx+320*dy]に格納された値になるわけです。
ちょっと説明がまだろっこしくて、判りにくいかもしれませんが、やっていることは非常にシンプルです。
例えばプログラム上で、mappedDepthDataの0番目から順に取り出して得られる(X,Y)座標に、同じ順番目のdepthData[]配列の値を元に算出した色合いを、colorFrame32配列(ColorImageStreamから取り出した実画像情報)に重ねると、
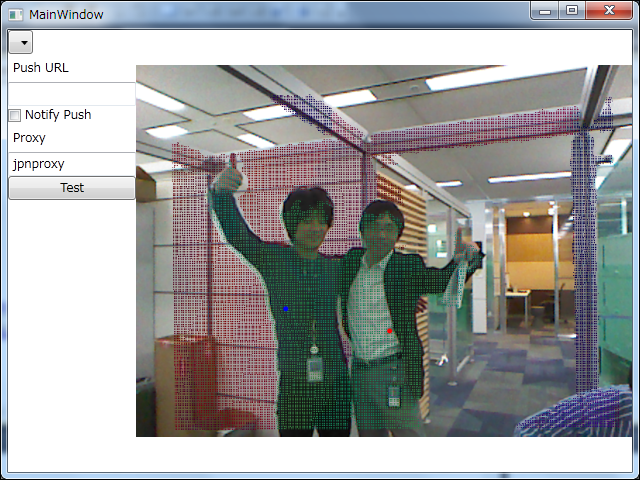
その3で紹介した画像は、単純二倍(面積的には4倍)なのでべた塗りな感じでしたが、こちらの画像は、320×240の点を拡大せずに640x480の画像に点描しているので、網がかかっているような画像になっています。深度情報がちょっと大きな感じですが、シルエットのずれは一応なくなっています。
他にも、
- MapDepthToColorImagePoint
- MapDepthToSkeletonPoint
- MapSkeletonPointToColor
- MapSkeletonPointToDepth
という4つのメソッドがあって、深度情報をスケルトンの座標に併せたり、スケルトン座標を実画像や深度画像のピクセルにマップする機能が用意されています。