Working with compressed files in HDInsight
Ability to work with compressed data in a data-warehouse is well understood. It becomes even more pronounced when warehouse size runs in hundreds of terabytes and petabytes. Hodaap provides a way to interact with compressed files natively. Tools like Hive and Pig can read these compressed files and process them, thereby reducing storage requirements to a great extent.
In this post, I am going to describe how easily a hive query can be executed against a compressed data file. All screen shots are from my HDInsight cluster.
I am also using the new Windows Azure Powershell tool to interact with my HDInsight cluster. This is pretty straight forward and simple to interact.
(1) I first used the following commands to connect to my HDInsight cluster
# Provide Windows Azure subscription name, and the Azure Storage account and container that is used for the default HDInsight file system. $subscriptionName = "Windows Azure MSDN - Visual Studio Ultimate" $storageAccountName = "mydemocluster" $containerName = "sample"
# Provide HDInsight cluster name Where you want to run the Hive job $clusterName = "mydemocluster" Add-AzureAccount Select-AzureSubscription -SubscriptionName $subscriptionName Use-AzureHDInsightCluster $clusterName |
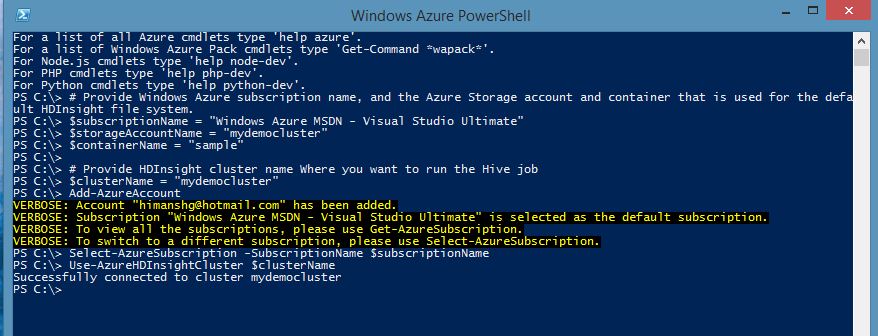
Although I have used "Add-AzureAccount" to authenticate myself on the interactive console. The same can also be scripted using certificates.
(2) Next, I created a sample table by invoking Hive for the PowerShell
$queryString = "CREATE EXTERNAL TABLE Sample_Data (Exchange STRING,Stock STRING,Date STRING, High STRING,Low STRING,Open STRING,Close STRING,Field1 STRING,Field2 STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/Data/HiveExternal';" Invoke-Hive -Query $queryString |

Notice that I have created an external table in hive as I am not doing any aggregation in this example.
(3) Now I will move compressed file in this location so that I can run hive query on this data. I am using Cloud Explorer to move file. Cloud Explorer also has a free version and presents a windows explorer like interface to interact with azure blob storage.
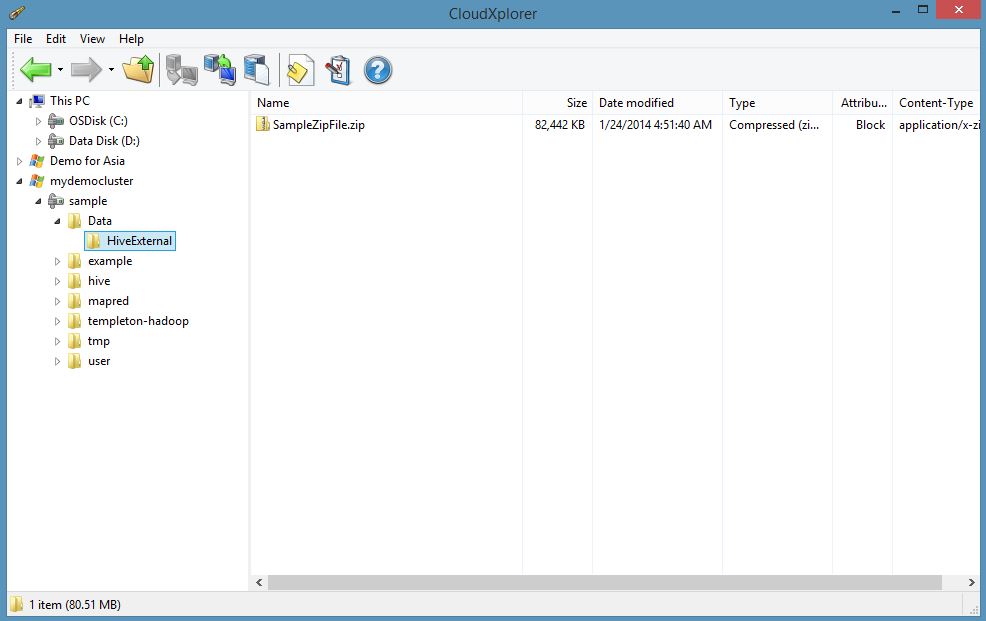
SampleZipFile.zip contains a bunch of CSV files all compressed together. The files are copied to the same location where the external hive table is point to.
(4) Now that data is in there, I can simple query this data using hive query. Hive will automatically run map/reduce jobs on the data nodes which hold a chunk of this compressed file!!
$queryString = "select count(*) from sample_data;" Invoke-Hive -Query $queryString |

That's it !!!