La scalabilità ed il partizionamento in Entità (parte 1)
Tra le tematiche che mi capita più di frequente di discutere con gli architetti ed i senior developer delle grandi aziende che incontro nel mio lavoro, ricopre un posto rilevante , subito dopo i principi della oramai mitica "soa", la scalabilità delle soluzioni applicative.
Come prima cosa chiarisco il significato che comunemente viene associato al termine scalabilità, con lo scopo di evitare la classica confusione che si genera utilizzandolo. Capita spesso , infatti, che questo termine venga confuso con gli altri aspetti di performance di una applicazione , di solito i tempi di esecuzione medi o la cosiddetta "velocità " di risposta dell'applicativo nell'interazione con l'utente. La scalabilità , invece, è la capacità dell'applicazione di supportare un numero crescente di utenti , mantenedo le performance costanti, attraverso un piano prefissato e pianificato di incremento delle risorse hardware (hw) e software (sw) necessarie. In altre parole, per avere un'applicazione scalabile dobbiamo avere nella nostra soluzione un'architettura che ci consenta di sfruttare le eventuali aggiunte di hardware. Nessun limite deve essere posto in questo tipo operazione necessaria per ottenere la possibilità di sostenere un carico crescente di utenti, sia nella possibilità di incrementare le risorse sia nella possibilità di sfruttarle in modo più vicino possibile alla linearità e comunque in modo pianificabile.
Ovviamente alla base della capacità di misurare la scalabilità e pianificarla , oltre ad una buona base architetturale, deve essere previsto sin dall'inizio un approccio allo sviluppo della soluzione che preveda specifici e mirati test di verifica , misurazione dei limiti e pianificazione dei meccanismi che possono permetterci di "scalare" la soluzione al crescere delle esigenze di carico. In pratica la scalabilità deve essere trattata come un vincolo ed un requisito funzionale della soluzione.
La domanda più frequente in relazione alla scalabilità riguarda le potenzialità delle piattaforme impiegate, l'approccio tipico relega la problematica ad una delle funzionalità dell'application server o della tecnologia in uso. Tra le frasi più frequenti mi capita spesso di sentire: " uso la tecnologia tal dei tali perchè quella si che scala ...." .
Dal mio punto di vista la realtà è che uno degli aspetti fondamentali nell'ottenere la scalabilità in una soluzione è in relazione all'architettura complessiva della soluzione stessa; ovvio che la tecnologia e la piattaforma di base giocano un ruolo ma , nella mia esperienza, raramente rappresentano un ostacolo al raggiungimento dell'obiettivo.
Per ottenere scalabilità occorre fondamentalmente che la nostra architettura sia in grado di avvantaggiarsi dell'aggiunta di risorse hw senza imporre specifici limiti. Quando si parla di scalabilità , quindi, saltano fuori immediatamente i due modelli fondamentali attraverso i quali è possibile incrementare le risorse hw in una soluzione e si parla quindi di :
- - Scalabilità verticale: quando andiamo ad aggiungere risorse hw sulla stessa macchina su cui sta funzionando la nostra soluzione (aggiunta CPU, Memoria, dischi, schede di rete, etc)
- - Scalabilità orizzontale : quando andiamo ad aggiungere macchine nella nostra soluzione su cui distribuire\dividere l'applicazione, incrementando la potenza di elaborazione complessiva
Volendo ragionare sui principi fondamentali su cui basare l'architettura di una soluzione applicativa e strutturare una soluzione che possa continuare ad indirizzare un carico crescente in modo teoricamente illimitato, è immediatamente evidente che la soluzione deve consentire un approccio orizzontale alla scalabilità. Un approccio verticale, infatti, avrà sempre un limite dovuto alla possibilità fisica di aggiungere elementi ad una stessa macchina (cpu, memoria, etc). Nella pratica, ovviamente, questo limite può essere anche notevolmente superiore alle nostre esigenze ma, a mio avviso, ragionare considerando esclusivamente questo tipo di approccio può portare ad architetture rigide. Il rischio è un vero e proprio impedimento nell'aggiunta di risorse in modo orizzontale, ponendo di fatto un limite che a soluzione implementata diventa difficile da modificare senza un impatto significativo.
Un esempio classico che mi capita spesso di incontrare e su cui torneremo anche successivamente è rappresentato dalla sessione utente delle applicazioni Web . Una volta implementata una sessione utente di dimensioni rilevanti e non "serializzabile", ovvero che può soltanto rimanere nella memoria della macchina in cui viene generate e non persistita in un database o spostata su specifiche macchine dedicate, per poter indirizzare in modo completo l'aggiunta di nuove macchine alla nostra soluzione occorre mantenere il vincolo dell'affinità tra un utente e la macchina server in cui la sessione è caricata. Questo impedisce il completo sfruttamento della potenzialità di elaborazione delle macchine eventualmente aggiunte, impedendo ad esempio, che le richieste possano essere staticamente distribuite tra tutti i server disponibili, creando di fatto un limite significativo nella scalabilità. In una simile situazione è banalmente dimostrabile che il carico delle macchine sarà realmente bilanciato solo per valori di utenza molto elevati (es. svariate migliaia di utenti e centinaia di sessioni) per valori di utenza inferiori il carico delle macchine sarà spesso fortemente sbilanciato.
Dal mio punto di vista, uno dei principi fondamentali della scalabilità di una soluzione è nella capacità di non creare vincoli rispetto alla possibilità di distribuire nel modo più granulare possibile le attività di elaborazione rispetto alle risorse hw disponibili , rendendo di fatto possibile l'aggiunta e lo sfruttamento di risorse sia verticalmente che , in particolare in modo orizzontale.
L'architettura con cui vengono genericamente costruite le applicazioni transazionali moderne è genericamente basata su applicazioni web o smart client\web service costruite su tre livelli logici, distribuiti su due o tre livelli fisici. I tre livelli corrispondono genericamente a:
- - un livello in cui inseriamo la logica di presentazione
- - un livello in cui inseriamo la logica di business
- - un livello in cui inseriamo la logica di accesso ai dati
Nella maggioranza delle applicazioni in realtà, oggi si tende (contrariamente al recente passato) a concentrare i tre livelli logici su due soli livelli fisici, in quanto nella maggioranza dei casi si sviluppano applicazioni "data intensive". Essenzialmente la logica di business in queste applicazioni non effettua grandi calcoli ma accede a dati e spende la maggior parte del tempo in attesa di tempo di I\O consumando di fatto pochissime risorse di elaborazione.
Per quanto riguarda i primi due livelli, ottenere un'architettura che possa essere facilmente "scalata" anche in modo orizzontale tramite l'aggiunta di macchine è tipicamente semplice da ottenere. Aggiungendo hw alla soluzione, possiamo continuare a installare la nostra applicazione sulle nuove risorse ed a distribuire il carico degli utenti sulle stesse. Buona norma per sfruttare al massimo la capacità di elaborazione di tutte le macchine, come già accennato, evitare tutti quegli elementi che legano uno specifico utente ad una delle macchine in modo permanente.
La questione per lo strato di persistenza\dati si complica. Qui, infatti, abbiamo un insieme di risorse che sono contenute in uno stesso storage che logicamente è collegato ad una specifica macchina. Alcune piattaforme indirizzano in parte il problema consentendo l'utilizzo dello stesso storage a più motori relazionali, anche se installati su macchine differenti. Questo approccio ha dei limiti fisici nei conflitti che si generano rispetto alla concorrenza sullo storage.
Per indirizzare lo sfruttamento di hw multiplo nello strato dati la tecnica migliore ed anche la più utilizzata nei siti che necessitano di grande scalabilità (amazon, hotmail, myspace, etc) consiste nel partizionare i dati in entità logiche univocamente determinabili da una chiave. Questo tipo di partizionamento ci permette di poter in qualunque momento di separare le entità in storage e macchine diverse potendo in qualunque momento determinarne la posizione. L'approccio consente , inoltre, la possibilità di ridistribuire le entità tra le risorse hw disponibili in modo dinamico, raggruppandole anche in base al carico che ricevono. Si possono ad esempio costruire script che ridistribuiscono le entità tra le risorse hardware in base al carico che ricevono, tecnica classica utilizzata ad esempio per la gestione delle cassette postali o dei basket.

Ovviamente per gli strati applicativi sovrastanti alla parte di accesso ai dati , questo tipo di distribuzione deve essere assolutamente trasparente. Questo significa costruire uno strato di accesso ai dati che renda indipendente il codice chiamante da questo aspetto, attraverso l'implementazione di un algoritmo che distribuisca le entità sulle macchine e che ci permetta di determinare la posizione attraverso la chiave delle stesse. In questo modo la logica di business richiede l'esecuzione di una specifica attività su una entità fornendone la chiave e lo strato di accesso ai dati, in base ad una logica predeterminata o uno specifico catalogo, determina la posizione dell'entità e vi accede in modo trasparente al chiamante.
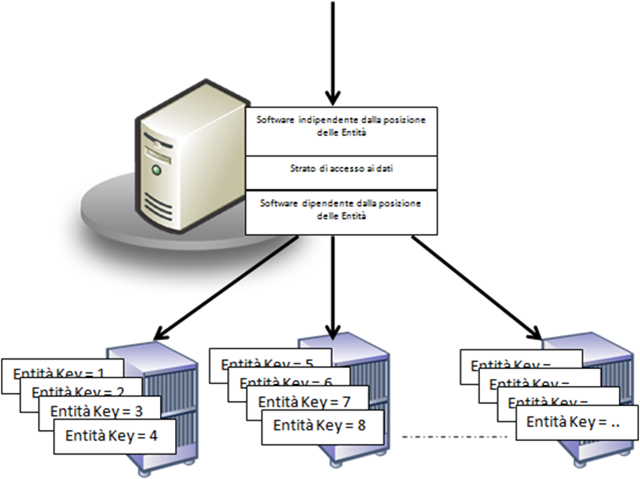
L'ideale sarebbe ovviamente quello di avere nelle piattaforme applicative di base e nei database relazionali questo tipo di concetto implementato in modo trasparente alle nostre applicazioni, così da permettere una semplice ed efficace implementazione dello stesso così come in passato i TP Monitor e motori dei database hanno implementato in modo dichiarativo altri concetti, come ad esempio le transazioni. Alcune piattaforme forniscono una parte dei principi descritti come ad esempio MS SQL Server con le funzionalità di federation, ma la strada per poter ottenere maggiori livelli di granularita per il partizionamento e la semplicità e la flessibilità di modifica e redistribuzione dei dati partizionati, come una funzionalità di base e di largo consumo è ancora lunga.
Un buon esempio di questo concetto può essere fatto tornando a riprendere la sessione utente nelle applicazioni Web che, infatti, si presta facilmente ad essere partizionato in entità univocamente determinate attraverso una chiave. Ogni sessione, infatti, corrisponde ad un utente e viene genericamente indicata univocamente con un GUID a 128 bit. Attraverso l'implementazione di uno specifico algoritmo di logica si può partizionare la posizione di una sssione, associandola ad una specifica macchina, facendo in modo che lo strato di software che gestisce questo aspetto sappia determinarne la posizione in modo trasparente alla macchina che la richiede.
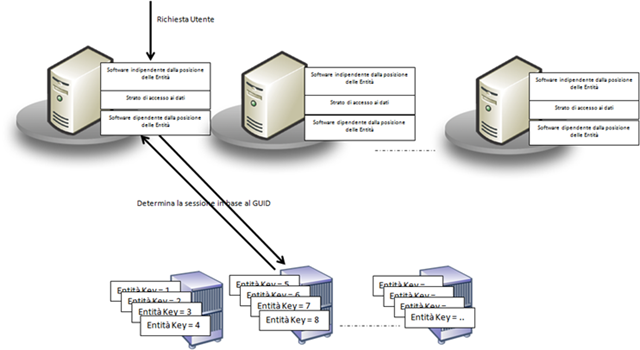
In ASP.NET 2.0 il provider di gestione della sessione prevede questo tipo di partizionamento. Il concetto è indicato come Partition Resolver e ASP.NET 2.0 mette a disposizione una specifica interfaccia (System.Web.IPartitionResolver) da implementare
public class CustomPartitionResolver : System.Web.IPartitionResolver {
private String[] partitions;
public void Initialize() {
// create the partition connection string table
partitions = new String[] { "tcpip=machine1:42424", "tcpip=machine2:42424",
"tcpip=machine3:42424" };
}
public String ResolvePartition(Object key) {
String sid = (String)key;
// hash the incoming session ID into one of the available partitions
int partitionID = Math.Abs(sid.GetHashCode()) % partitions.Length;
return partitions[partitionID];
}
}
che va poi indicata nel web.config all'interno del tag di gestione della sessione con l'apposito attributo:
<sessionState mode="StateServer" .. .... partitionResolverType="Nome ClasseCustomPartitionResolver">
Dopo tale configurazione ed in modo del tutto trasparente alle API di gestione della sessione, nell'applicazione è possibile implementare logiche di partizionamento che consentono di coinvolgere quante macchine sia necessario, aumentando notevolmente le capacità di scalabilità di questo aspetto della piattaforma. L'esempio mostra un partizionamento statico ma evidentemente possono essere sviluppati algoritmi più sofisticati.
Ovviamente il partizionamento in "Entità" così come l'ho definito prima non è l'unico fattore che influenza la scalabilità e la sua applicazione pone vincoli significativi alle performance ed in particolare a tutte quelle situazioni dove ad esempio, in una transazione abbiamo la necessità di effettuare modifiche a più entità, ma di questo parlerò in un altro post, qui volevo solo evidenziare come sia possibile con questa tecnica ed in alcuni casi anche in modo semplice e supportato come la sessione ASP.NET 2.0, gestire una maggiore flessibilità nella scalabilità.
Parte seconda del post a https://blogs.msdn.com/giuseppeguerrasio/archive/2007/06/18/la-scalabilit-ed-il-partizionamento-in-entit-parte-2.aspx