The VLF Trap
While working on one of the migration there is something which I discovered so sharing all what I know about VLF’s and how we can ensure that we don’t get into VLF trap:
Few issues which you can see if there are too many VLF’s:
- In cluster failover the database takes long time to come online.
- Transaction replication log reader is running, however there the data is not getting delivered to the distribution database.
- You are trying to restore the database and its taking ages to restore on the new server.
- Backups takes a long time.
- Delete/Update/Insert is going to take a long time and hence going to impact the performance of the SQL instance.
When you check sysprocesses, you would see last wait type as mentioned below and the SPID would be in a running state in few scenarios:
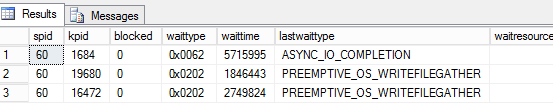
Things which needs to be checked:
- SQL Server service account is either part of the “Local admin” or have been explicitly granted the permission to “Perform Volume Maintenance Task”. This would make sure that we don’t have to zero out the file before writing and help in getting data moved
to MDF file faster ( this doesn’t apply to T-log file as instant file initialization is not applicable in the case of T-log file). - DBCC LOG INFO is returning <100 rows when ran against the database. If the number of rows are more than >1000, then please act immediately.
- Check DBCC OPENTRAN and check if there are any pending open transactions.
- Check if Log reader have to scan a lot of data and it’s not able to see any replicated transaction ( use replication monitor) for this.
- Check the Windows event logs when SQL server is starting and it would give you the information about the VLF’s if it’s too many.
- Check if CDC is enabled.
- If we have found that the number of VLF’s are too many then please do the following :
a. If the database is in full recovery mode, take the T- log backup so that the VLF’s which are active and just waiting for the T-log backup would be showing a “Status” value of zero ( before the backup the status would be 2) in DBCC LOG INFO.
b. Check why we are not able to re-use the existing VLF’s if any using the following : select log_reuse_wait_desc,is_cdc_enabled from sys.databases.
c. Check if log reader is performing optimally and delivering the transactions, else we have to tweak the parameters so that it delivers the data and clean the VLF’s.
8. Shrink the Log file. You may have to check if the initial file size value have increased to a higher value then you have set. This is seen very often on the systems. If you want to find what was the initial value which was set for the file when it was created
(once you increase the size of the file using SSMS or ALTER DATABASE, the size value in system tables is now the new increased size of the file. DBTABLE and the file header page will still retain the MinSize which is the original file size.)
you can either use DBTABLE or DBCC PAGE (DBCC PAGE(TEST, 1, 0, 3)). You can find with MinSize.
9. Once the log file have been shrunk, increase the initial size to a large chunk so that auto-growth doesn’t come into picture every-time there is some huge inserts.There is no good value for the initial size and you have to set it up based on your monitoring of the log file size.
10. When deciding the size of the file, have the size in multiple of 8 GB. This helps in ideally sizing them ( I don’t have a justification but got this from SQL big shot ).
11. Don’t have a big value for the auto-growth as well ( ideally 512 MB is a good value).
12. Also, if the VLF size is too big then also we can see performance issues ( generally during the T-log backups).
Disclaimer: I work at Microsoft. Everything here, though, is my personal opinion and is not read or approved by Microsoft before it is posted. No warranties or other guarantees will be offered as to the quality of the opinions or anything else offered here.