Sneak peek: Horizontal scaling using “Azure SQL Database Elastic Scale Preview” – Day 1
Few days ago we announced a new elastic framework for SQL Database. This new framework is very exciting because will help developers to scale SQL Server workloads in a horizontal way. This is very, very difficult to achieve on your own: I’ve seen many implementations – with varying degrees of complexity –often build around the SQL Server federation concept. The federation was fairly simple but lacked the depth required to exploit the “elasticity” every cloud service promises to give.
For this reason the federation (see https://msdn.microsoft.com/library/azure/hh597470.aspx) has been superseded by the Azure SQL Database Elastic Scale framework. I won’t dig into the concepts here as they are very well covered in the Microsoft Azure documentation: https://azure.microsoft.com/en-us/documentation/articles/sql-database-elastic-scale-get-started/ .
What I want to show today is how easy is to use the framework even with your on-premise SQL Server instances. Starting to develop in an elastic way is the key to be able to fully exploit the cloud power (even if you are not using it right now you will in time).
What we want to simulate here is a veeery simple database application: an append-only log. Our database will have only one table with an int primary key, a date and an nvarchar field. Something like:
CREATE TABLE [log].[LogEntry](
[ID] [int] NOT NULL,
[Entry] [nvarchar](max) NULL,
[EventTime] [datetime] NULL DEFAULT (getdate()),
PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
If you are a seasoned DBA you will scream “contention!” as soon as I tell you that my int clustered key will be an monotonically increasing number (if not, don’t worry, you can read this post to find out: https://blogs.msdn.com/b/sqlserverfaq/archive/2010/05/27/monotonically-increasing-clustered-index-keys-can-cause-latch-contention.aspx).
Of course there are many tricks to avoid this – ie partitioning – but what about using different databases altogether? Or, even better, different servers?
This is where Azure SQL Database Elastic Scale framework will come to play. Instead of using a single SQLConnection we will use a ShardMap. A (list) shard map is the framework equivalent of a table partitioning: you map ShardLocations to specific values (aka lookup table). Once mapped all you have to do is to ask the framework the “right” connection for your value. The connection will contain everything needed including the initial_catalog entry. As soon as you have the connection, you can simply use it as you would with a standard connection (in fact, it is a standard connection).
This is done using these simple lines of code:
int iServerIndex = i % lServersShards.Count;
using (SqlConnection conn = listShardMapMain.OpenConnectionForKey(iServerIndex, ssShardMapManager.ConnectionString))
{
// insert here
}
Knowing how many shards we have (lServersShards.Count) we can implement a round-robin algorithm with just “ID modulus shard number”. This approach is often referred to as “data dependent routing”: in a nutshell you are creating a link between your values and their location.
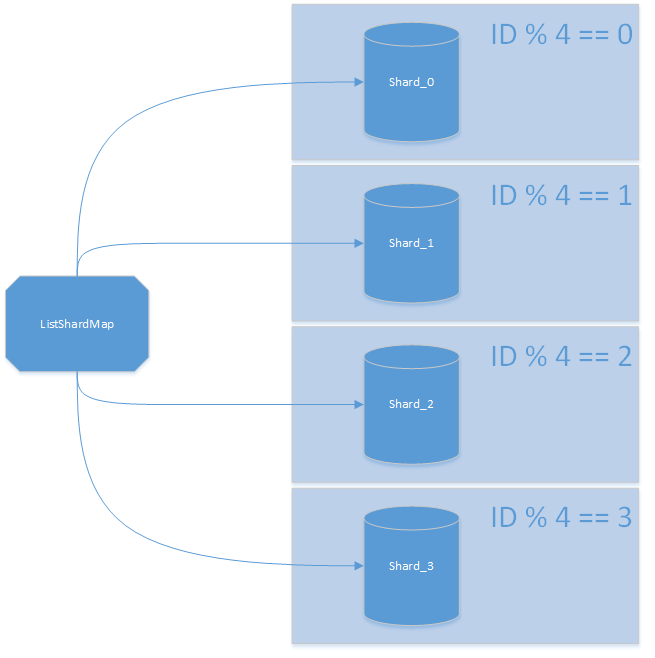
The mapping between a value and its physical shard is maintained by a ListShardMap instance (https://msdn.microsoft.com/en-us/library/azure/dn807370.aspx). It works as a keyvaluestore mapping a value to its ShardLocation (https://msdn.microsoft.com/en-us/library/azure/microsoft.azure.sqldatabase.elasticscale.shardmanagement.shardlocation.aspx).
ShardLocation sl = new ShardLocation(<where>, <db_name>);
shard = listShardMapMain.CreateShard(sl);
// create shard mapping
listShardMapMain.CreatePointMapping(i, shard);
The ShardMap itself is maintained by the ShardMapManager (https://msdn.microsoft.com/en-us/library/azure/microsoft.azure.sqldatabase.elasticscale.shardmanagement.shardmapmanager.aspx):
listShardMapMain = shardMapManager.CreateListShardMap<int>(SHARDMAP);
You can have more than one ShardMap active at the same time and they are persisted by the ShardMapManager itself. You can create a new one this way:
shardMapManager = ShardMapManagerFactory.CreateSqlShardMapManager(ssShardMapManager.ConnectionString);
Or you can retrieve an existing instance this way:
ShardMapManagerFactory.TryGetSqlShardMapManager(
ssShardMapManager.ConnectionString,
ShardMapManagerLoadPolicy.Lazy,
out shardMapManager);
So in order to build our client we need:
- Create a ShardMapManager.
- Create an int based ShardMap.
- Add our table schema to the ShardMapManager.
- Create the shards (including the table if needed).
- Store the shard locations into the int based ShardMap.
- Insert data (using multiple threads of course).
The full source code is available here (https://gist.github.com/MindFlavor/99a70650961e47a3f767) if you want to try it yourself (I’ve cheated a bit to make the problem bigger but I’ll leave up to you to find how ;)). Make sure to add the required NuGet packages to your solution before building it.
What I want to show you is how the application scales. The first test if using a single shard: this is, we don’t use the elastic framework at all:

As you can see, inserting about 50k row took more than 2 minutes.
Now I’ve added a second instance. Note that since our ShardMap entries are the number of server passed as parameter (remember the modulus operator) our entries will be splitted in the two instances. The elegance of the framework allows the code to scale without any change:

The time is much less. We can go on just as easily. Three instances:

Or even four:

Please note that we are not bound to different instances: we can have more shards in the same instance and still solve the last page latch contention problem. Adding more servers in my lab won’t change much more because right now the bottleneck is somewhere else (my money is on the storage since it’s shared).
In order to query the data you can still use the “data dependent routing” approach show above or use a specific class: MultiShardConnection (https://azure.microsoft.com/en-us/documentation/articles/sql-database-elastic-scale-multishard-querying/). This class – along with its helper classes – will be covered in the next Azure SQL Database Elastic Scale sneak peek.
Happy coding,
Francesco Cogno