Windows Azure Guidance - Additional notes on failure recovery on Windows Azure
Things will eventually fail in your application and you need to be prepared. So most components should be designed for something going wrong and recover gracefully (or as gracefully as possible) and leaving the system in a consistent state (eventually in some cases).
In this post I wrote about dealing with data consistency when interacting with multiple tables in a single “unit of work”:
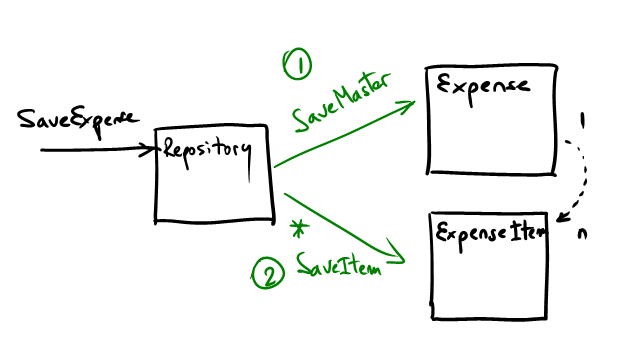
To summarize, step #1 and step #2 belong to a single logic unit of work. However, since there’s no support for ACID transactions between 2 tables in Windows Azure, you might end up with “orphaned” records if something happens in between and you don’t have any logic to clean things up.
Things get even more complicated as you add other resources to the Unit of Work. For example, in the latest version of aExpense, we also (optionally) save the images to blobs. For each blob we then write messages to a queue to notify workers that there are new images to compress. in this case, writing to the tables, writing to the blobs and writing to queues is a single logical unit of work. And of course, there are no ACID transactions supported across all these resources.
One approach (showed in the aExpense sample) is to handle all errors in the Repository. Roughly, there’s a big try in the body of the method responsible for coordinating all the work and then there’s a catch that cleans up things that were left over.

This would probably work for most cases, but…there’re some problems with this approach though. Can you spot the issue(s)?
I want to thank Shy Cohen which whom I had a great discussion yesterday on this specific problem. I also learned how to break someone’s wrist and defend from a knife attack on your throat, but that’s worth an entire post.