LitwareHR on SSDS - Part IV - Data access enhancements 2: developing offline
SQL Server Data Service is well...an online service. That means that you have to be connected to the network 100% of the time if you are using it. What if you are not connected? well...you know the whole story.
Our goal while developing LitwareHR was to actually make the dev team as independent and autonomous as possible. Notice I say the dev team, not the application itself. We were comfortable in taking a dependency with SSDS for runtime, that is when LitwareHR would be deployed in a production data center. But we wanted developers to be able to work even if they are flying on a plane with no connectivity (like I was!). In one sentence we wanted a "mock SSDS" .
With this in mind, we developed a new proxy implementing the same interface the real proxy implements, but against a local SQL Server Express database.
Again: our goal was not to create full-fledged offline SSDS, but rather an implementation complete enough to support our TDD development practices, and "complete enough" is key here. We gradually made it more complex as needed by LitwareHR, so no guarantees that it would actually work in another application, and no optimizations whatsoever.
Each dev in our team would configure he's own solution to use the offline version of the proxy, make sure all tests pass, etc. then we would test against the real one. Features on the offline client were strictly added as necessary as we made progress with the project and tests passed with the real proxy but failed with the mocked one.
The ProxyFactory class allows us to switch between one implementation and the other. Repository doesn't really know or care about what version is using.
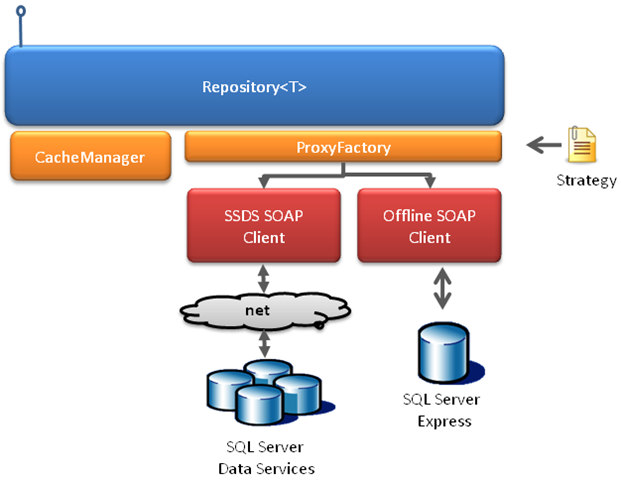
The implementation is quite straight forward actually. There are 2 tables: CONTAINERS and DATA. The table CONTAINERS is only used to record the existence of a new container (because Containers can be empty). The table DATA contains the entity instances themselves. Structure of these tables is as simple as you could imagine:
CONTAINER:
[containerId] [nvarchar](255) NOT NULL
DATA:
[containerId] [nchar](255) NOT NULL,
[id] [nvarchar](255) NOT NULL,
[version] [int] NOT NULL,
[kind] [nvarchar](255) NOT NULL,
[entity] [xml] NOT NULL
containerId, Id, version and kind translate into SSDS entities' intrinsic properties. Queries against these being frequent. entity is the field that contains the serialized flexible entity.
The schema of the serialized entity is also quite simple and direct. A "book" entity with 3 fields: Title, ISBN and Author would be serialized like this:
<entity>
<field name="Title" type="System.String">The Aleph</field>
<field name="ISBN" type="System.String">78755</field>
<field name="Author" type="System.String">J.L.Borges</field>
</entity>
Operations like Insert, GetById, Delete and Update are trivial. Query is trickier because we had to (re) implement a parser for SLINQ. Good for us that SLINQ is fairly simple today. Once again, we just developed the basics so LitwareHR would work.
In a nutshell, it's simply a translator from SLINQ syntax into a mix of T-SQL and XQuery. Searches involving intrinsic properties (Id, Kind, etc) are straight forward T-SQL statements. XQuery is only involved when the search criteria includes properties within the entity. For example:
This query against a "C_1" container, looking for an entity with Id = E_1:
from e in entites where e.Id=='E_1" select e
is translated into:
SELECT id, entity, version, kind FROM DATA WHERE containerId='C_1' AND Id = 'E_1'
and getting all entities with a flexible property named "Title" equal to "The Aleph":
from e in entities where e["Title"]=="The Aleph" select e
will become:
SELECT id, entity, version, kind FROM DATA WHERE containerId='C_1' AND entity.value('(/entity/field[@name="Title"])[1]','NVARCHAR(MAX)') = 'The Aleph'
We definitely recovered the investments we made in creating this facility. When we started development, SSDS was still changing and under development (this was far before MIX08), it was only available from our intranet (making it more difficult for our non-MSFT team members to access it: VPN, etc). With this approach, we definitely increased our productivity.
For serious, production offline access I'd look at Sync Services.