Hosting LitwareHR on a Service Delivery Platform - Part IV - Service Level Agreements
Part III of this series of articles introduced a common design pattern (using an interceptor) to provide value added services such as billing and metering. The interceptor works at the operation level, and uses both information provided by the ISV (Litware) and information the hoster manages (like disabling and enabling an Operation).
What we didn't mention was that this is a very powerful mechanism that Northwind Hosting uses for a lot of other value added services, minimizing the impact on the ISV application architecture and design.
Those of you who have observed in detail the "Application Manifest" introduced in Part II of this series, might have noticed another field associated to the "Business Action" besides the billing event: "Expected Response Time"
{kind=link}
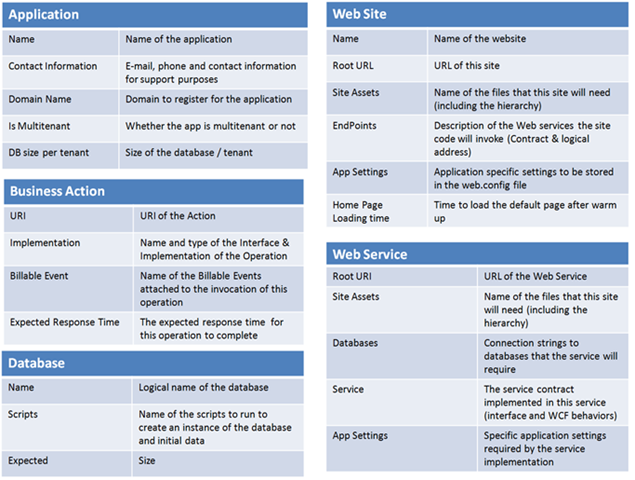
To Northwind Hosting, defining an expected response time on an Operation means that it is an something worth looking after and monitor. So every time someone invokes it, it will measure the total amount of time it takes from the moment it starts until it completes, and log it.
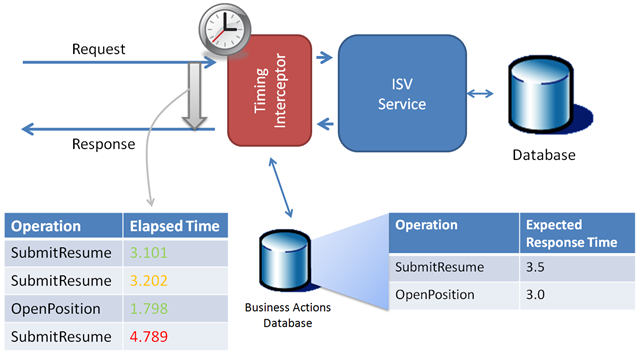
Figure 1: Timing configurations associated with App Operations
In the example above, SubmitResume is a business action that has an expected response time of 3.5 seconds defined. Because it has an entry in the business action database, every time it is invoked, the total execution time will be recorded by NWH infrastructure. In the example, two invocations were below the threshold, the third is above.
Now of course the question is: what should NWH do with this information? Well it turns out that NWH "by design" defines and commits to execution SLAs around Operations timing.
What Litware buys from NWH is: a given availability (service available x% of the time) and a performance SLA like: "monthly average response time below ERT with an X% of consecutive time above it, for Y tenants".
For example, if X were 12%, then month 1 and month 2 are OK, but the 3rd month, even with a better average than month 2, has a higher number of consecutive days above threshold and therefore the SLA is not fulfilled. NWH would pay penalties for month 3, even with a better average response time.
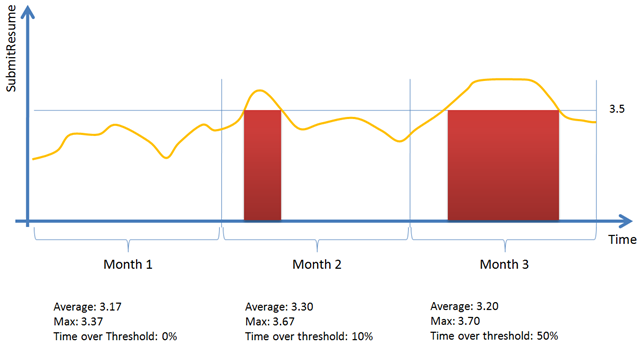
Figure 2: Performance management and SLAs
Note: this is just an example of course. One could think of all sorts of sophisticated statistics to associate with a SLA like the above: use the 95th percentile, use Kurtosis based SLA (making this up), who knows... I'm sure there're proven and established rules for SLAs.
What I want to surface is the design implications in LitwareHR and on Northwind's hosting platform it will run on. Notice that Litware is not required to create any performance counters or logs, the same interception mechanism used for billing and metering is used here for measuring execution time.
NWH can use all sort of smart approaches to keep their infrastructure utilized at a maximum (remember, a core objective is to maximize the application density in their environment to minimize costs), dynamically provisioning new servers and resources as the application behavior threatens missing a given SLA. They can do this, because the have knowledge of how the application is architected.
Given the restrictions NWH imposes on the hosted ISVs, they could use these strategies for managing performance (and SLA):
- Scale out the Web Services layer, adding new servers and load balancing between them.
- Partitioning databases per tenant (distributing tenant databases into different instances and servers).
They can do this transparently because they know the application by design is compatible with these strategies. #1 because of how the middle tier is designed (stateless, web services based). #2 because Northwind requires all data access to be done through Enterprise Library Data Access Application Block, and they can include this "database load balancing" in their own version of Enterprise Library. (I'll cover more of this in another post).
A critical step for NWH though, is the ability to predict how the application scales (Figure 3), because this will determine the acceptable threshold, the resources needed to meet the SLA and therefore the hosting costs for a given SLA.
Figure 3: Scalability curves for two different applications. Yellow curve shows a better scalability behavior.
These curves should be obtained during the application on-boarding and dynamically adjusted during actual operation as real life information is gathered.
Technorati tags: SaaS, Service Delivery Platform, On Demand, SLA