
Click here if you want to skip all the theory and just go to the Security Reviews Heuristics Zoo
If you are a software security professional, you might’ve been asked sometimes to conduct a “security design review”. If you felt lost at that point, this article may help you. Here I tried to summarize my experience of working on the security reviews of over 200 Microsoft products since year 2000.
Being practical, I focused on the approaches that I personally found helpful at least in some circumstances.
Microsoft Research Podcast

Collaborators: Holoportation™ communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
However, I’m also mathematically inclined. So I did not resist providing a theoretical justification – or something that looked like one – where it seemed applicable. Please don’t take it too seriously. Many of these things are way too vague to be even formally defined, so the math often only illustrates the train of thought rather than formally proves anything.
To make reading easier, I split the article into three parts.
In the first one, I propose a working definition of a “security design review”, estimate the computational complexity of doing it, and show that it is at least exponentially complex with respect to the number of the components involved.
Second, as running such an algorithm is prohibitively expensive, I list some simpler heuristics that I have used in the past to get security reviews done.
Finally, the article is closed with couple rather philosophical thoughts on quantitative definitions of security and possible role models for a security reviewer.
And, inevitably, the Disclaimer:
Information and opinions expressed in this post do not necessarily reflect those of my employer (Microsoft). My recommendations in no way imply that Microsoft officially recommends doing the same. Any phrases where it may look as if I don’t care about customer’s security or recommend practices that increase the risk should be treated as purely accidental failures of expression. The intent of this text is to share knowledge that aims to improve security of software products in the face of limited time and resources allocated for development. The emotional content represents my personal ways of writing rather than any part of the emotional atmosphere within the company.
Part 1 — The Theory
So, your manager is asking you to ensure “design security” of a large product or an online service.
You look at it and it turns out to be a huge thing. Dozens of people, hundreds of features, countless source files… Even though you might’ve done Threat Modeling before, it’s hard to see where and how to apply it. To add to the confusion, some security experts recommend running a “security design review”. Everybody is sure it’s more than just a Threat Model but nobody’s quite certain in how exactly.
If I had received a request like that, my [personal] interpretation of it would be the following:
- Do whatever is possible within the allocated time and resources to minimize the number of security defects at the design level, and
- Be ready to go beyond Threat Modeling if you see that something different is needed to address the request.
How that goal could be approached “from the ground up”?
If a product is too large to even comprehend it as a whole, you may start with logically splitting it into smaller manageable units. Depending on the situation, those could be product features, binaries, source files, or infrastructure servers. Let’s say there are N of them at the end of that work. Further, I’ll be calling them “elements”, “pieces”, “components”, or “features”, but it’s important to understand that they may not really be functionality features. They are just any small elements that comprise and logically represent a product as whole.
What’s next? The next natural move could be to check the security of each piece individually. If pieces are small enough, the checks would likely be simple – such as a question you can ask to component owner(s), or a statement a scanning tool could verify. For example:
- Does it use MD5 hashing?
- Does it communicate over the wire in clear?
- Does it need to reflect user’s input to a Web page?
- Does it copy anything into memory buffers with lengths controlled by an external input?
- Is it built with a current, secure compiler?
- Does it sit in a dual-homed network?
- Does it collect PII data?
The resulting process, for the purposes of this text, will be called “an audit” or a “security audit”.
One thing I want to be very clear is that it is absolutely irrelevant for now who does these checks. It could be either a human or some testing tool. That does not matter. Nor I want to discuss how to (possibly) automate these checks — not now at least.
Instead, let’s just count them.
If there were N logical elements within the product (e.g., N features), and m checks to run against each of them, the audit will take m*N questions to be done. To those familiar with a big-O notation I can say that the cost of a security audit is O(N), or just “linear”.
Does audit solve the initially stated problem? Certainly it can detect some security issues so it may improve the security of the product. But if all checks are clear, does that mean a product is 100% secure? Even if we assume that there are no security holes inside each feature?
Well, not necessarily.
An audit (at least as defined here) is concerned mostly with individual features, but not with their interactions. Now imagine the following situation:
- Feature A: “We are an internal component, we expect all our callers to pass us only well-formatted data!”
- Feature B: “We don’t sanitize any data, it is the responsibility of the parser who consumes our data to do so!”
If B takes a malicious input and passes it to A, what happens next? Quite possibly A will choke on it, resulting in a crash, a memory corruption, or another kind of unexpected behavior. In other words, there is a good chance of a security hole arising from such a design level disagreement between the components!
As an example, consider the infamous strcpy API. It actually can be perfectly safe! For that, it “only” requires meeting a few conditions, namely:
-
- That the source string is correctly null-terminated
- That argument strings don’t overlap
- That nobody changes them while copying is in progress
- That the destination is not shorter than the source (with its ‘\0’ character)
The problem is, those conditions are often impossible to verify within the context where strcpy is invoked. If all you have from your caller is a string, you (generally) won’t even know if that string is null-terminated where it was supposed to be! The information necessary for that determination may reside a dozen frames above within some of the (unknown) callers, creating an implicit dependency that is very difficult to track. That is the reason the use of that API is discouraged.
So in general, any case of two components having mismatching expectations about each other’s behavior carries a risk of a security weakness, if not through an unexpected data manipulation/propagation than at least via a simple crash that can shut down a server.
Therefore to guarantee product security, we must verify that there are no disagreements on the expected format of interaction between any pair of product components. Thus we’ll need to check all pairwise feature interactions there – either real or potential ones.
What would that look like?
Start with Feature A. List all features it interacts with (both explicitly, such as through function calls, and implicitly, such as via a shared state). Verify that each interaction does not create any recognized security weaknesses. Don’t forget A itself — what if it’s re-entrant? Then move to feature B. Check for potential interactions with all features A, B, C, D, E, F, … etc. Then do the same for C, D, and so on.
How many checks would that consume? If there are N elements in the system, and we need to check each one against other N-1 components plus itself, that comes to N*N = N2. In reality, many of these checks are unordered (e.g., A vs. B is the same as B vs. A). If that is always the case, the count would be N*(N-1)/2, which is still proportional to N2.
It is true that most pairwise interactions would be outright impossible in reality. But even confirming so in each case still requires (at least mentally) matching a pair of features, therefore we still arrive at the O(N2) overall complexity estimate.
And this is pretty much what a “classical” Threat Modeling does. Its Data Flow Diagram is a map of all recognized pairwise interactions in the system, and “a threat” represents a recorded analysis summary for each such interaction or component.
Fine. Let’s say that all pairwise checks are done, all discovered weaknesses are documented and even fixed. Can you guarantee now that a product’s design is 100% free from security flaws?
Well, not quite yet.
Because some use cases within the product may involve three features interacting with each other! And at least sometimes such three-way interactions could not be fully described as a trivial superposition of independent simpler interactions.
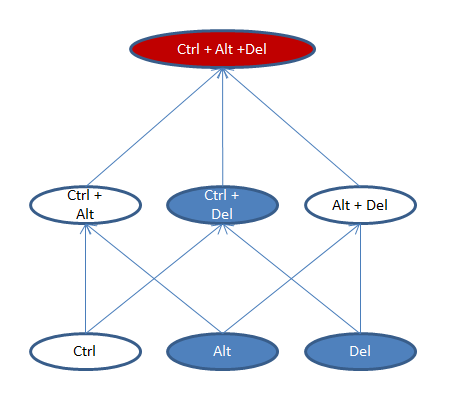
The simplest and the most recognized example of such a behavior (although not a security hole) is… Ctrl+Alt+Del keys sequence on a Windows 7 PC!
What happens if all possible k-keys combinations of those keys are tried in Microsoft Word where I (originaly) typed this text?
Complexity level 1 (individual features)
Ctrl: nothing happens
Alt: shortcut keys are highlighted
Del: a symbol is deleted
Complexity level 2 (pairwise combinations)
Ctrl + Alt: nothing happens
Ctrl + Del: the end of the word is deleted
Alt + Del: nothing happens
Complexity level 3 (three-way combinations):
Ctrl + Alt + Del: Windows Logon prompt shows up!
Lets’ visualize that with a diagram. Here vertical “floors” represent complexity levels (i.e., the number of features activated simultaneously). White ovals are “empty” combinations, resulting in no functionality. Blue ones are usable interactions. And red color represents a functionality combination that (while not a security hole in this case) appears quite unexpected from the standpoint of basic expectations:
Sigh… So to *really* ensure product security, we need to check all three-way combinations? There are N3 of them and so the complexity of this new algorithm is N-cubed… Even if none of the combinations are sensitive to permutations (e.g.,
If you feel like screaming “but what about a secure design, or layers of abstraction?” — hold on for a moment, please. I’ll talk about that later.
But wait… At this point, you probably see where this is all going. Even certifying all three-way interactions within a product as safe won’t technically certify a 100% secure design, because there could be 4-component interactions there, some potentially insecure!
And after that — there are 5-component combinations, 6-component, and so on up to the very N-component where (theoretically) all product features are impacting each other at the same time. And a security flaw (theoretically) may arise at any level of the interaction complexity!
Therefore, an exhaustively complete security design review will require looking at each component tuple at each level of the diagram below:

Again, blue elements here represent “valid” feature combinations (those that result in planned functionality), white ones – impossible combinations, and the reds are unexpected behaviors, some of which could be (due to their unexpected nature) security bugs.
How many security checks will it take to cover it all? Let’s estimate at least the lower boundary cost, assuming the highest possible interaction symmetry between the features.
At the complexity level 4, it will be N*(N-1)*(N-2)*(N-3)/24 checks. At the level 5, the corresponding count is N*(N-1)*(N-2)*(N-3)*(N-4)/120. At the k-th level, this is N!/((N-k)!*k!). The total of this progression is well-known from the math and is simply 2N.
In other words, a complete security design review is at least exponentially complex with respect to the number of elements comprising a product. To get a feeling of what that means, for N = 100 features 2N evaluates to 1.3*1030. That is a lot. In fact, that is way higher than anything practically achievable today!
Further, without much limitation the same conclusion could be derived with respect to many other classes of security assurances, such as:
- Source code review, where a role of a “feature” is played by either a source code file or an API entry point. Surely, with a source code it is much easier to see if function A calls function B. Yet even if there is no direct invocation, the possibility of higher order interference is not excluded. It can arise from many secondary effects such as runtime invocations via a function pointer or a delegate, or from sharing the state. And there is always at least one shared state between nearly any two functions in the process, which is the amount of available free memory. If one function eats it all, another may become unable to allocate even a new *int. Very unlikely? Yes. But possible? Yes, too.
- Security testing. Most who have done penetration testing or fuzzing know very well that calling entry point A with a bad input may produce no crashes… unless you have called B, C, and D before in precisely that order.
This leads us to a rather depressing conclusion: at least in the majority of practical cases, no mathematically solid security assurance is possible for products with more than just ~30 independent components or elements. And since most real life products are way larger, that means security design reviews or writing security tests are destined to miss most problems in a product.
That (surprisingly) may not be a problem on its’ own, but I’ll talk about that later.
Hmm?
“Hold on” – you’d say, – “Did you just prove that no product testing is ever possible at all? That’s certainly not the case!”
Correct. That’s not the case. But there is a big difference between security and functionality testing.
Functionality testing does not need to address all possible feature interactions. As long as it covers 99.x% of what customers typically use, the rest can be declared unsupported. That is practically achievable.
Contrary to that, a functionality combination that results in a security hole cannot be declared “unsupported”, no matter how crazy or unexpected in everyday life it is. If attackers have found it, they will abuse it, no matter if it is a “customer scenario” or not.
That – theoretically – drives the boundary of security testing (or reviewing) way beyond of what’s needed for regular functionality coverage.
What else?
Another objection you may have is the fact that we’ve built a whole mathematical model without even strictly specifying what those logical pieces to review are and how we’ve split a product into them! How’s that possible? What if another person decomposes a product in a completely different manner? Will the conclusion hold?
I believe it will. Splitting a product into different K logical elements may result in different review findings and different cost if K ≠ N. However, an audit will still be linear with respect to K, a thorough “complete” review will still be at least exponential, and any simpler review technique will still contain missed interactions. Some of them will arise because what was considered one element in the previous decomposition is now represented as two — or wise versa.
Enough theory now. Total security assurance may not be possible, but you aren’t going to report that to your manager instead of doing your job, right? A product ships and we still need to do *something* meaningful to protect the customers and the company. What would that *something* be?
When a precise algorithm is too costly to run, it is often replaced with an approximate one that still does an acceptable job.
So welcome to the land of heuristics. In the next chapter, I will explain, review and compare some of them.


