Machine Learning para principiantes - Bonus Track: visualización de datos con PowerBI e interacción desde un bot
Si después de crear los experimentos te quedaste con ganas de más, en este ultimo capítulo veremos como exporter los datos resultantes para que puedan ser consumidos tanto desde PowerBI como desde un bot conversacional.
Lo primero que debemos hacer es cambiar el tipo de datos de la columna "Drafted" a entero, así que vamos a añadir otro modulo "Edit Metadata" y realizar esta transformación:
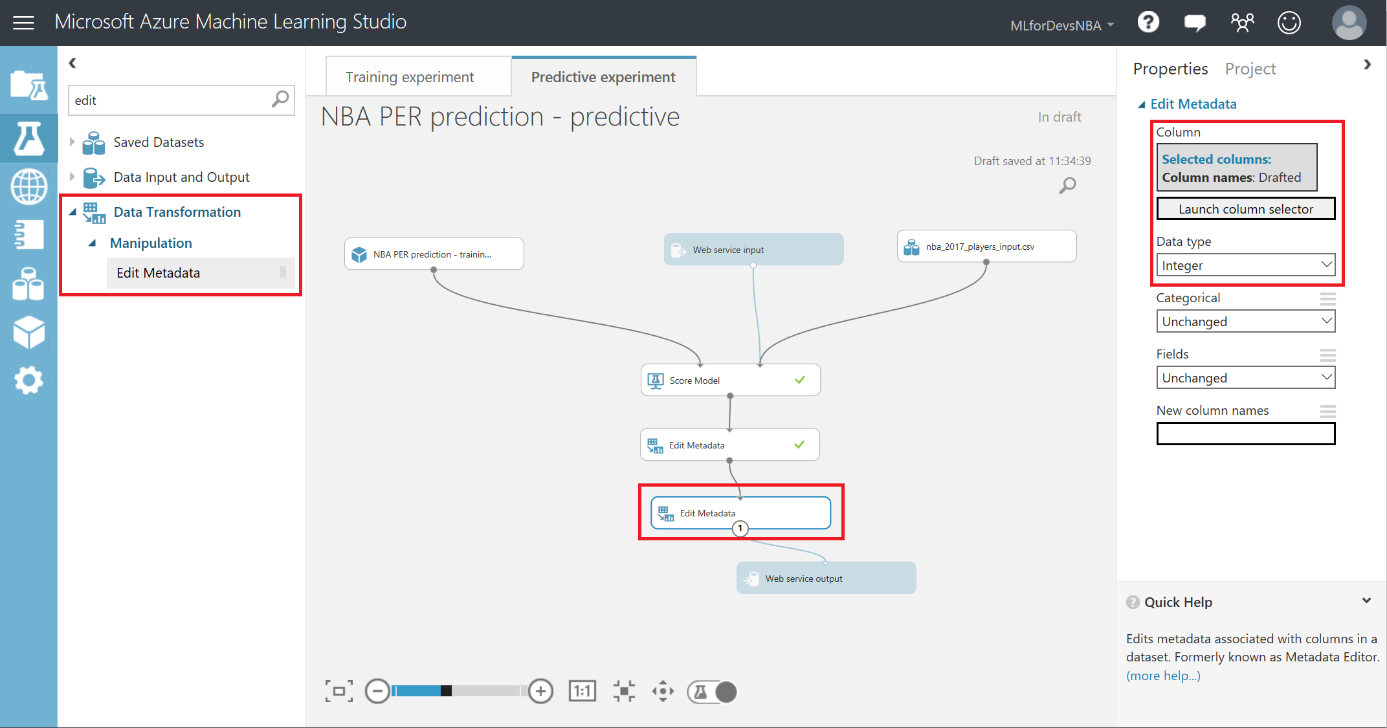
Después de esto, vamos a exportar el resultado de las predicciones a una base de datos SQL en Azure, de forma que tanto PowerBI como el bot puedan conectarse a los datos e interactuar con ellos. Para hacer esto, busca el modulo "Export Data" en el menú de la izquierda, dentro de la categoría "Data Input and Output" , arrástralo al canvas y conecta su entrada con la salida del último modulo "Edit Metadata" :
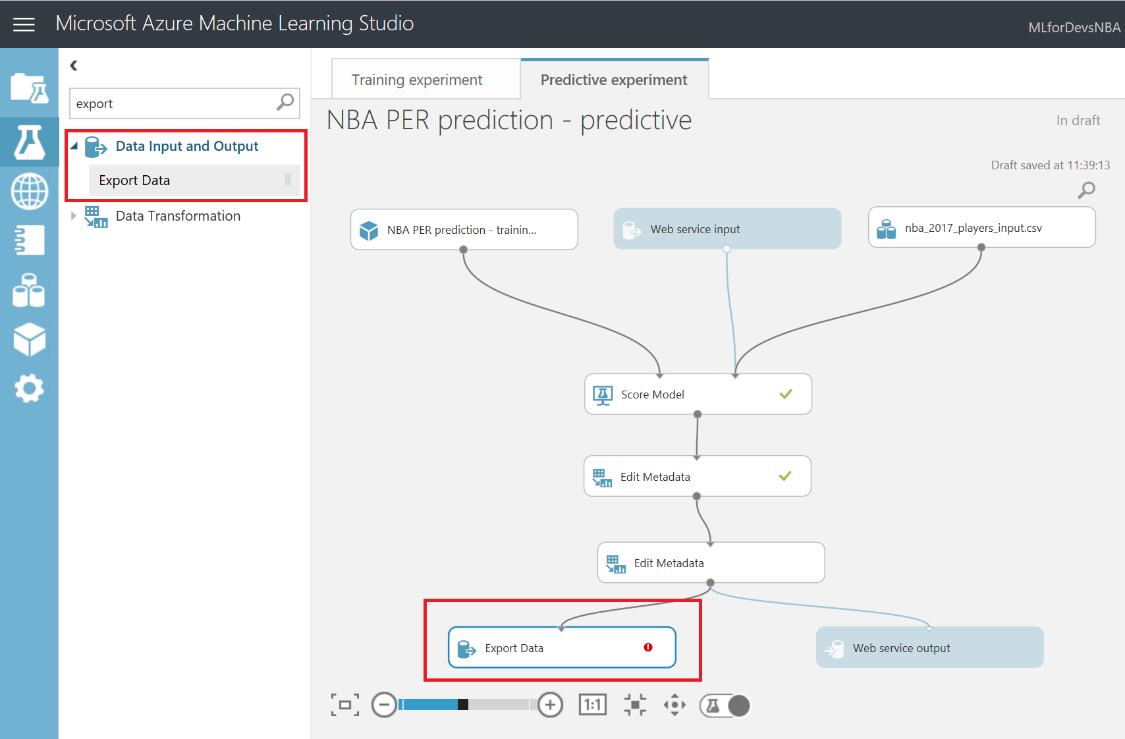
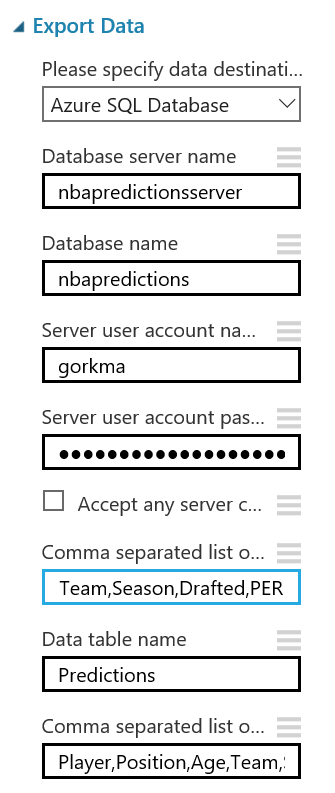
Con el modulo "Export Data" seleccionado, podrás configurar el servicio de almacenamiento en el que prefieras almacenar tus datos. En este caso, la opción elegida es una base de datos Azure SQL, que necesitarás desplegar de antemano. Si no lo has hecho nunca, en este enlace puedes encontrar un tutorial paso a paso para hacerlo. Asegúrate de incluir tu IP en la whitelist del firewall del servidor SQL, o toda consulta será rechazada.
Una vez tengas la base de datos en funcionamiento, necesitarás el nombre del servidor, el nombre de la base de datos y las credenciales del usuario para acceder a ella (todo puedes encontrarlo en el portal de Azure). Para continuar, simplemente escribe la lista (separada por comas) de columnas que se seleccionarán del dataset (en este caso: Player, Position, Age, Team, Season, Drafted, PER), indica el nombre de la tabla en la que quieres que se almacenen estos datos, y con otra lista de nombres de columnas separados por comas puedes elegir el nombre de las columnas en la base de datos (en este caso, se recomienda mantener los mismos nombres y usar la misma lista que antes):
Tras ejecutar de nuevo el experimento predictivo, todas las predicciones se almacenarán en la base de datos y estarán disponibles para que se consulten y consuman desde Power BI y cualquier otra aplicación que pueda leer desde una base de datos SQL.
Con los datos ya almacenados, puedes seguir estos pasos para conectarse a ellos desde Power BI y comenzar a crear visualizaciones interactivas que te ayuden a interactuar con tus datos fácilmente: https://powerbi.microsoft.com/en-us/documentation/powerbi-azure-sql-database-with-direct-connect/
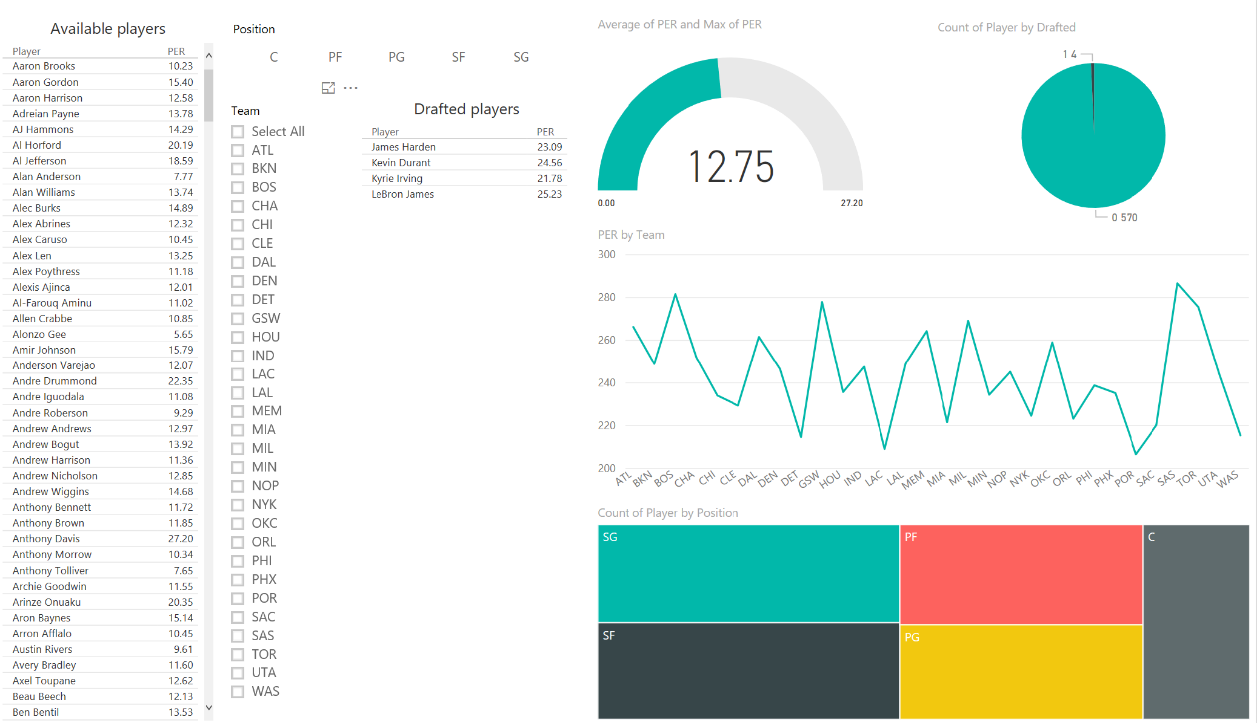
En este repo de Github (https://aka.ms/predict-nba-stats) también puedes encontrar el código de un bot que te permitirá interactuar con las predicciones almacenadas a través de una conversación real. Necesitarás, eso sí, configurar tu LUIS con diferentes intents, para que el bot pueda entender lo que se le está pidiendo (en este caso: saludo, información sobre un jugador específico por nombre, draftear un jugador, lista de los mejores jugadores disponibles y lista los mejores jugadores disponibles por posición). También puedes encontrar el bot publicado en https://aka.ms/nba-draft-bot, incluyendo tarjetas con fotos y noticias sobre los jugadores gracias a los Cognitive Services, que nos ayudan a añadir inteligencia a nuestras apps de una manera tan simple como añadir un par de peticiones HTTP:
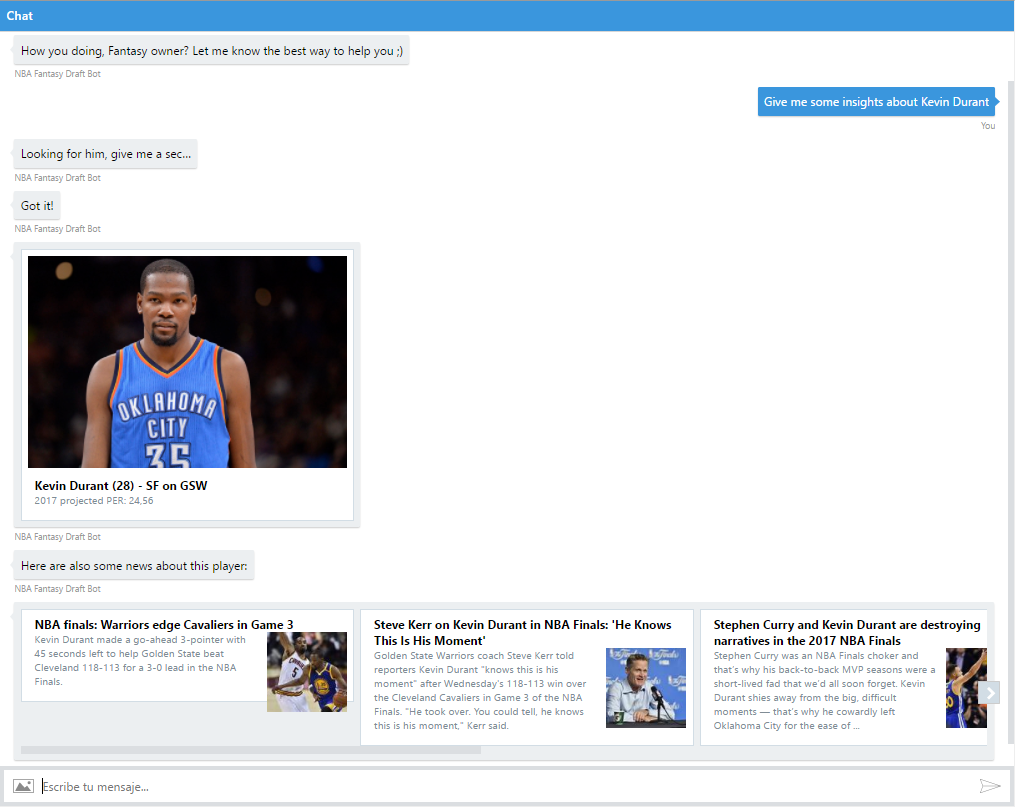
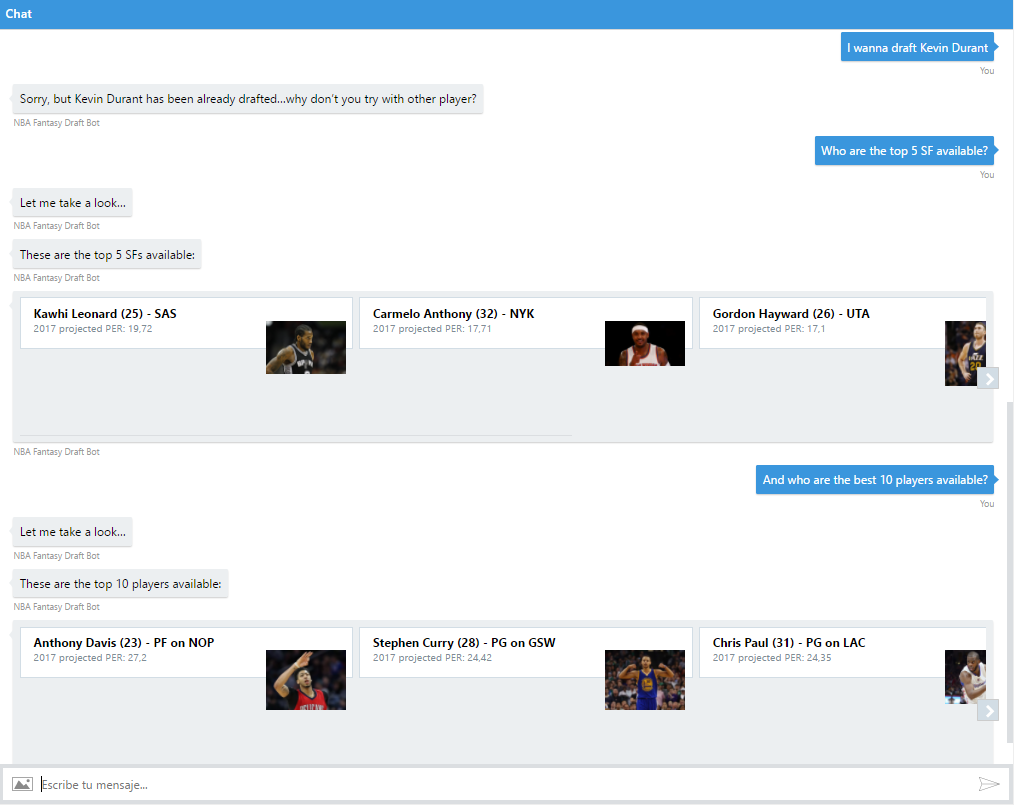
Esto es solo un ejemplo de cómo puedes interactuar fácilmente con los resultados de tus experimentos de Machine Learning y enriquecer los datos con algunas fuentes externas, ya que solo teníamos cold hard facts (números e información sobre el jugador), pero carecíamos de contexto específico sobre el jugador, que podría ayudarnos a entender el aumento/disminución en su valoración, o si deberíamos elegirlo o no debido a distintos factores (lesiones, cambios en el equipo, problemas con el entrenador o con algún compañero...). Es sólo cuestión de tener un objetivo claro en mente y encontrar los datos correctos para crear tu solución.
Como aprendizaje durante la construcción de este experimento, me quedaría con las siguientes ideas:
- Regla del 80/20: la preparación y limpieza de los datos es CLAVE en cualquier experimento de Machine Learning, y se lleva la mayor parte del tiempo empleado en ello.
- Probar diferentes enfoques y ajustes suele mejorar bastante el rendimiento del modelo, y se trata de un proceso de prueba-error (lo de llamarse "experimentos" no es casualidad) en el que cada detalle cuenta...sigue probando hasta que consigas los resultados deseados!
- El conocimiento que se tenga sobre el dominio de los datos a estudiar es crucial para determinar el éxito de una solución de Machine Learning, y no es suficiente con dominar las habilidades técnicas necesarias para crear soluciones de este estilo. Este conocimiento sobre el dominio nos ayudará a entender mejor las posibles correlaciones entre features y el impacto de los ajustes que hagamos, así como la importancia de filtrar los datos acorde a ciertos criterios, con el fin de mejorar la calidad de nuestro dataset.
Por último, algunos enlaces que pueden resultar útiles para continuar aprendiendo sobre Azure ML Studio y Data Science:
- Azure Machine Learning Studio tool (https://studio.azureml.net/) y documentación sobre el servicio (/en-us/azure/machine-learning/)
- Microsoft Professional Program for Data Science - https://academy.microsoft.com/en-us/professional-program/data-science/
- Basketball reference (fuente de los datasets) - https://www.basketball-reference.com/leagues/NBA_2017_advanced.html
- Kaggle (otra fuente gratuita de datasets) - https://www.kaggle.com/datasets
Espero que hayas disfrutado de esta serie tanto como yo creándola :)
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist