Machine Learning para principiantes - Capítulo 5: refinando el modelo y volviendo a evaluar
Como pudimos ver en el capítulo anterior, los resultados de nuestro modelo no son muy prometedores...todavía! Vamos a mejorar algunos aspectos de la limpieza de nuestro conjunto de datos haciendo algunos ajustes que mejorarán el rendimiento de nuestro modelo.
Lo primero que hará que nuestros datos sean más precisos es filtrar por una cantidad mínima de partidos jugados, ya que es "más fácil" destacar en pocos pocos partidos o tener un pico de rendimiento en un partido en concreto en lugar de rendir consistentemente a un nivel alto. Después de algunas pruebas, 55 partidos fue uno de los valores que mejores resultados arrojaba, por lo que debemos actualizar la consulta SQL para reflejar ese filtro:
update t1 set Player=PreprocessedPlayer;
select * from t1 where Rank<>"Rk" AND GamesPlayed>=55
Si vuelves a ejecutar el experimento, notarás que el número de filas en el conjunto de datos disminuye significativamente, el plotting se ve mejor y el rendimiento mejora consistentemente alcanzando un 47% y un 48% de precisión, respectivamente:
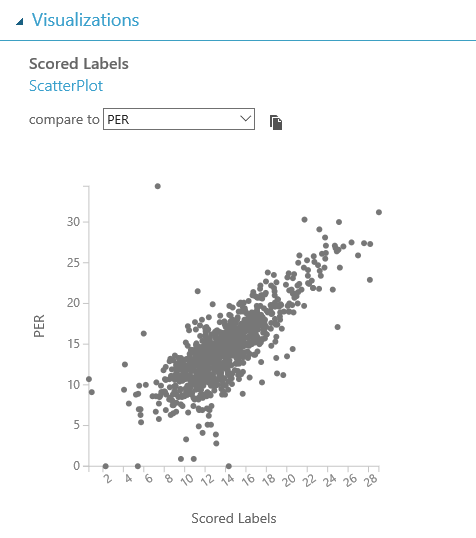
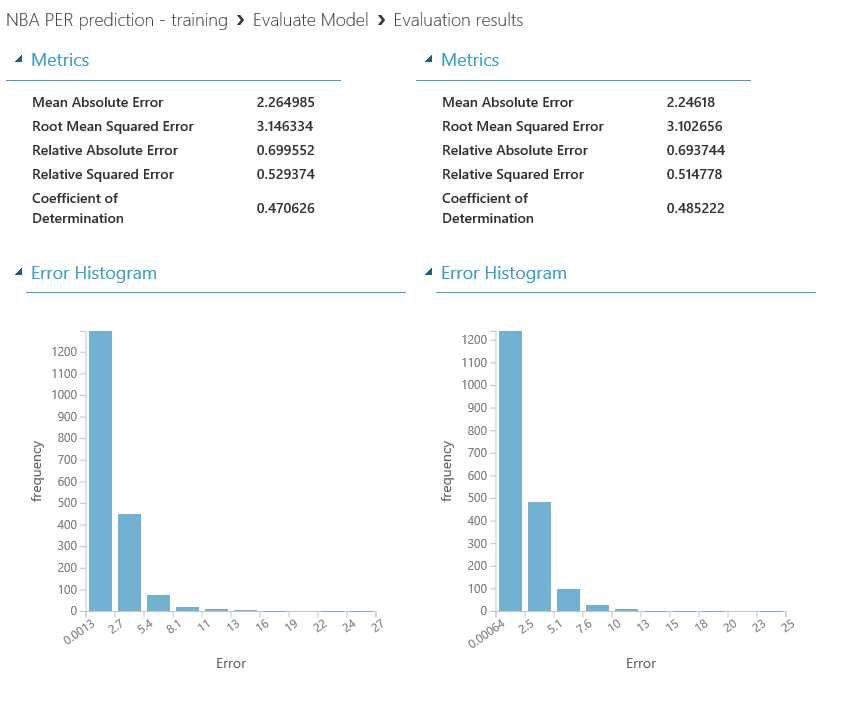
Cosas como esta son claros ejemplos de lo importante que es conocer el dominio de los datos que está manejando, y no sólo los conocimientos técnicos necesarios para estos problemas. En cada experimento de machine learning, tanto científicos de datos como personas de negocio con conocimiento del dominio deben ser incluidos, para que este tipo de detalles no se pierda.
Otra cosa que nos ayudaría a mejorar la calidad de nuestro modelo es usar un conjunto de pruebas de una longitud similar al que usaremos en el caso real. En este punto, nuestro conjunto de testing (el segundo conjunto de datos resultante del split), contiene casi 2k filas, cuando la realidad es que nuestro conjunto de datos de entrada para la predicción de la próxima temporada sólo contendrá 600-700 filas, que es el número de jugadores en activo en la NBA. Vamos a actualizar también la cantidad de datos utilizados para fines de entrenamiento, aumentando a 0.90 la cantidad de datos para el primer conjunto de datos de salida en el módulo "Split Data" , así como usar una semilla aleatoria para la división (en el ejemplo usamos 24832, pero es cuestión de probar diferentes valores y encontrar el que funciona mejor!):
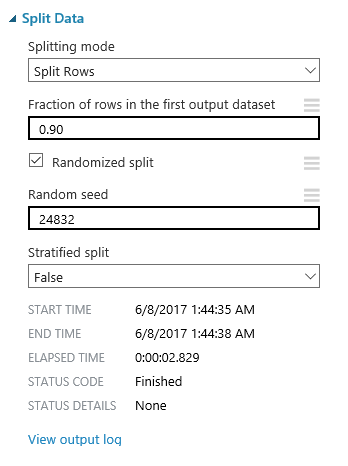
De nuevo, al ejecutar nuestro experimento tras el cambio, la precisión del modelo vuelve a mejorar bastante, alcanzando niveles de precisión de 0.56 y 0.51 respectivamente para cada algoritmo utilizado.
Por último, pero no por ello menos importante, la mayoría de los módulos de algoritmos permiten al usuario ajustar algunas de sus configuraciones, y su uso es muy útil para mejorar el rendimiento del modelo. En este caso, vamos a tomar el módulo de regresión de red neuronal (ya que es el que rinde un poco peor en esta momento) y hacer un pequeño ajuste.
En este algoritmo, hay diferentes parámetros que pueden ser editados, así que reduzcamos el número de nodos ocultos a 32 y también la tasa de aprendizaje a 0.001. Estos ajustes dependen del conjunto de datos utilizado y, de nuevo, sólo obtendrá los valores correctos al intentar diferentes ajustes y analizar el impacto en sus resultados. En este caso, estos ajustes en el algoritmo de regresión de redes neuronales han mejorado el rendimiento, alcanzando un valor de 0,60 en el Coeficiente de Determinación y haciendo que este algoritmo sea el mejor para nuestro modelo:
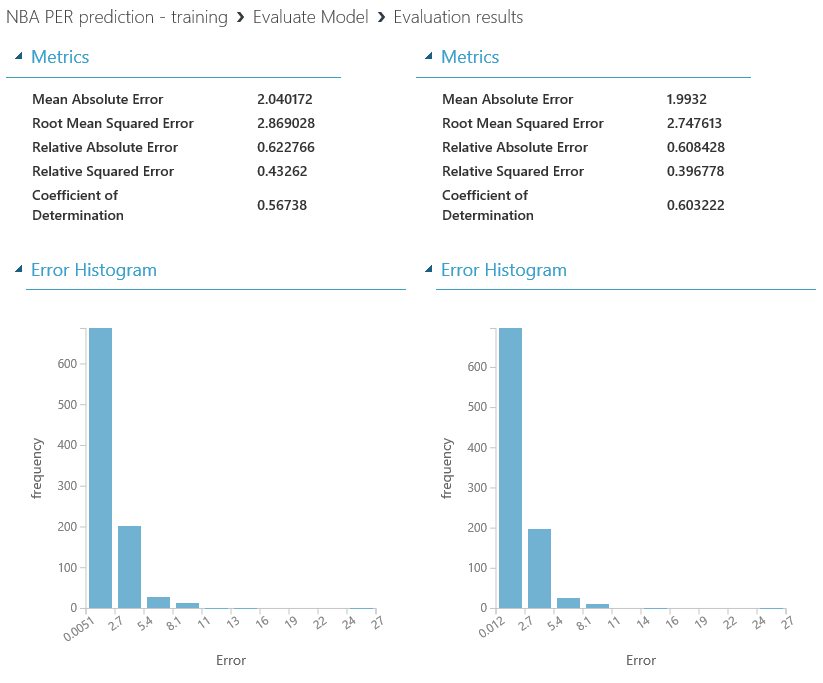
Con estos pequeños ajustes hemos conseguido multiplicar por bastante la precisión de nuestros modelos entrenados, y ahora sí que estamos preparados para predecir las valoraciones de nuestros jugadores favoritos para la próxima temporada...cosa que haremos en el próximo capítulo :)
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist