Machine Learning para principiantes – Capítulo 3: preparación y limpieza de los datos
En este capítulo vamos a pasar a una parte clave de todo experimento de Machine Learning: el procesado previo de los datos, en el que limpiaremos y prepararemos los datos de entrenamiento y evaluación a utilizar, para que nuestro modelo entrenado funcione lo mejor posible.
Como podemos ver al explorar nuestros datos, hay varias cosas que "ensucian" nuestro conjunto de datos (caracteres especiales en los nombres, filas con datos de encabezado por todo el archivo ...), campos sin valor asignado, campos tratados como texto cuando son números...
Con el fin de obtener los mejores resultados de nuestro experimento, debemos preparar y limpiar nuestros datos correctamente, y en este capítulo vamos a aprovechar algunos de los módulos de Azure ML Studio para lograr nuestra meta.
En primer lugar, ya que algunos jugadores tenían algunas condiciones especiales en temporadas específicas, están marcados con un asterisco en sus nombres. Este carácter especial, que no forma parte del nombre real del jugador, podría distorsionar nuestro conjunto de datos afectando a la calidad de nuestros resultados, ya que el mismo jugador podría ser tratado como uno diferente por esta minúscula diferencia en el nombre.
En el menú de la izquierda, bajo la categoría "Text Analytics" , podemos encontrar el módulo "Preprocess Text" , que se ocupará de esto por nosotros simplemente desmarcando todos los checkboxes excepto el de "Remove special characters" . Ten en cuenta que debemos establecer también el idioma (inglés en este caso) en la primera lista desplegable, y seleccionar la columna deseada (Player, en la que encontramos el nombre del jugador) para aplicar la transformación.
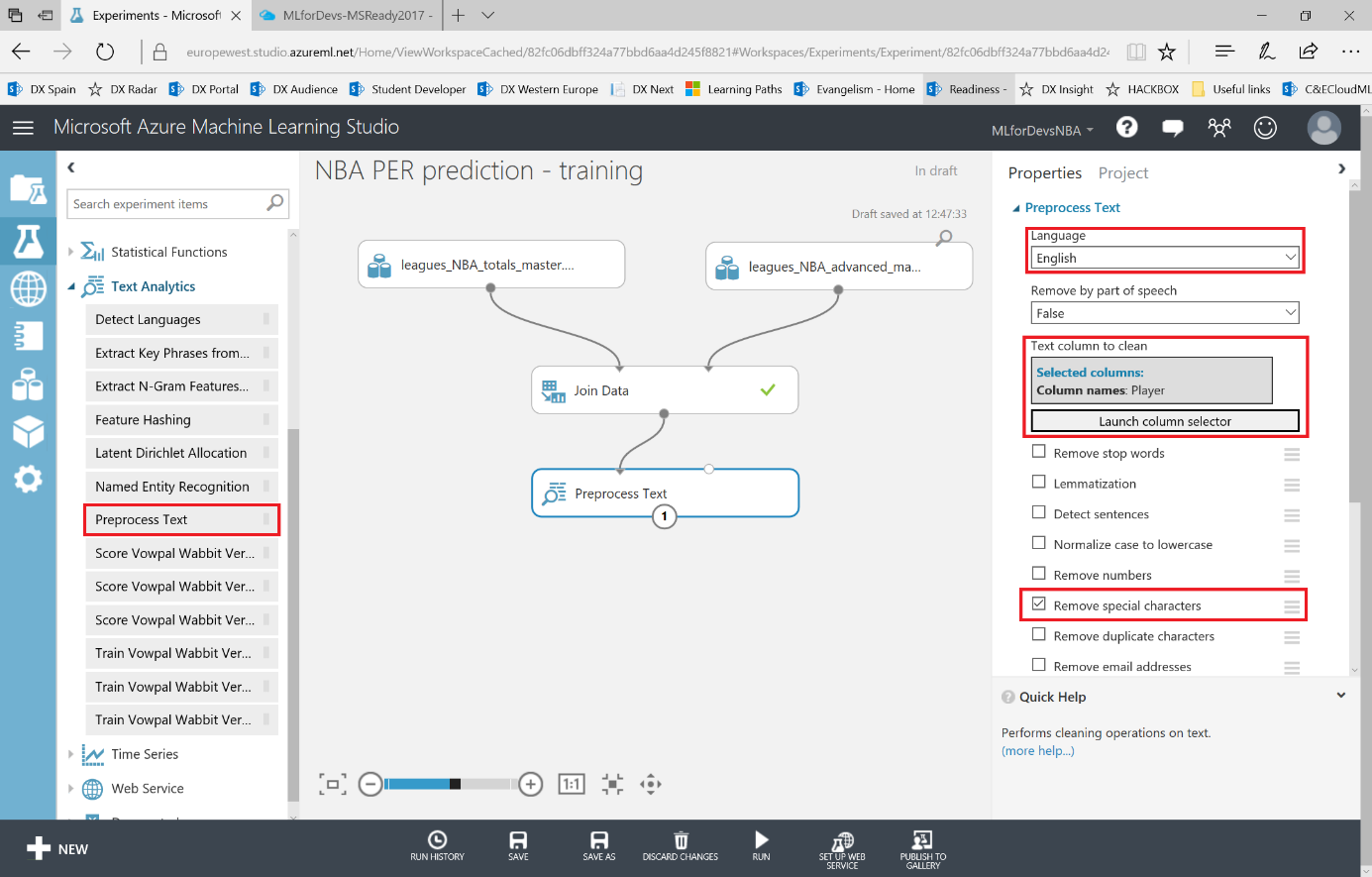
Si ejecutamos el experimento otra vez, tendremos un dataset como resultado, conteniendo tanto el nombre original del jugador (Player) como una nueva columna eliminando estos caracteres especiales (Preprocessed Player):
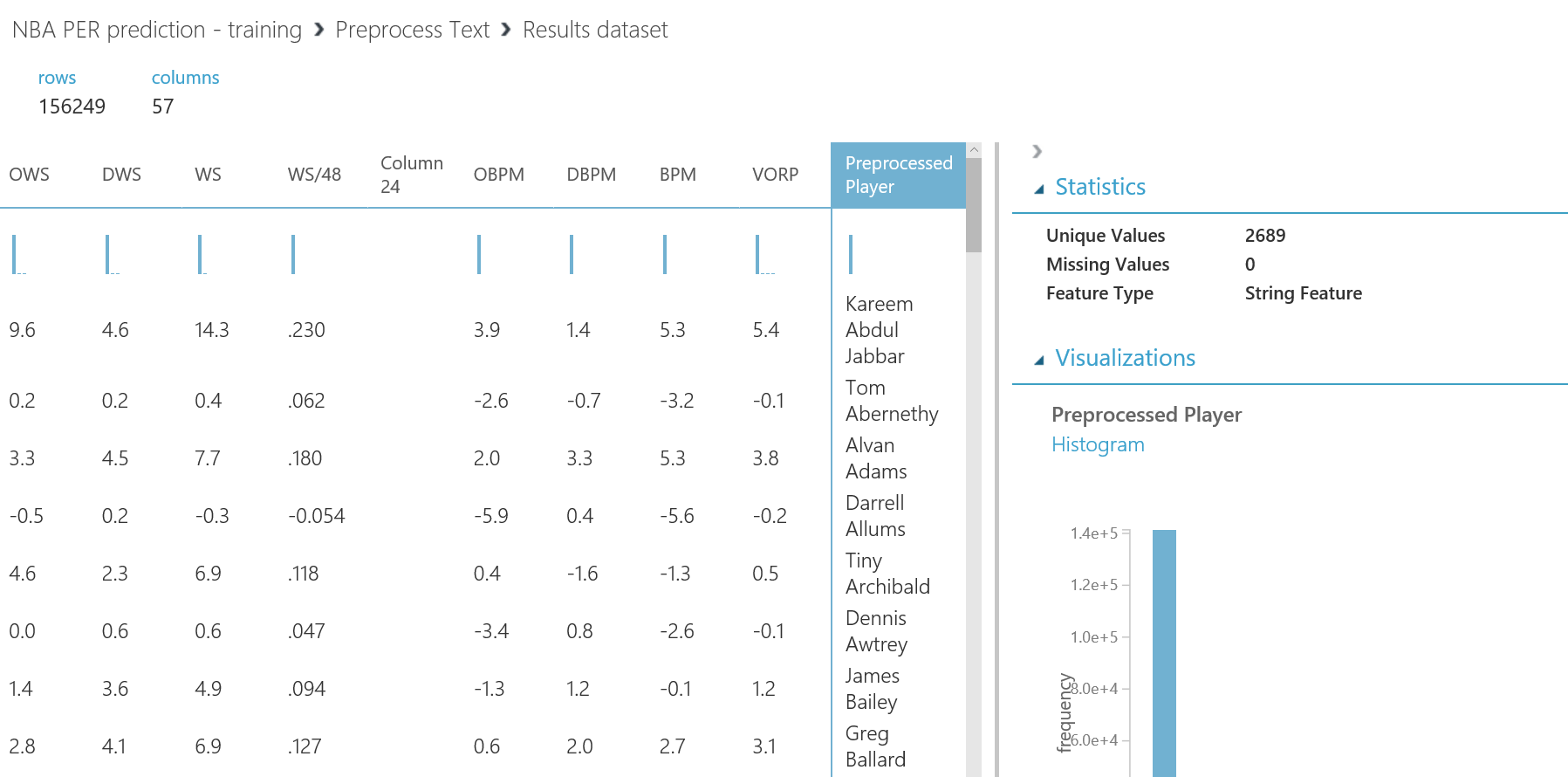
Además, para facilitarnos entender mejor el dataset, podemos cambiar los nombres de nuestras columnas usando el modulo "Edit Metadata" , para que podamos crear consultas más simples o encontrar las features de nuestro conjunto de datos con un nombre más descriptivo que el acrónimo. En este caso, cambiaremos el nombre de "Rk, Pos, Tm, G, GS, MP, FG, 3P, 2P, FT, Preprocessed Player" seleccionando las columnas del selector de columnas y escribiendo lo siguiente en el texbox de "New column names" :
Rank,Position,Team,GamesPlayed,GamesStarted,MinutesPlayed,FGM,3PM,2PM,FTM,PreprocessedPlayer
Ten en cuenta que el orden es importante, ya que lo que hace este módulo es cambiar el nombre de cada columna seleccionada con el texto en la misma posición en la lista separada por comas de nuevos nombres, por lo que ambas listas deben estar en el mismo orden y tener la misma longitud.
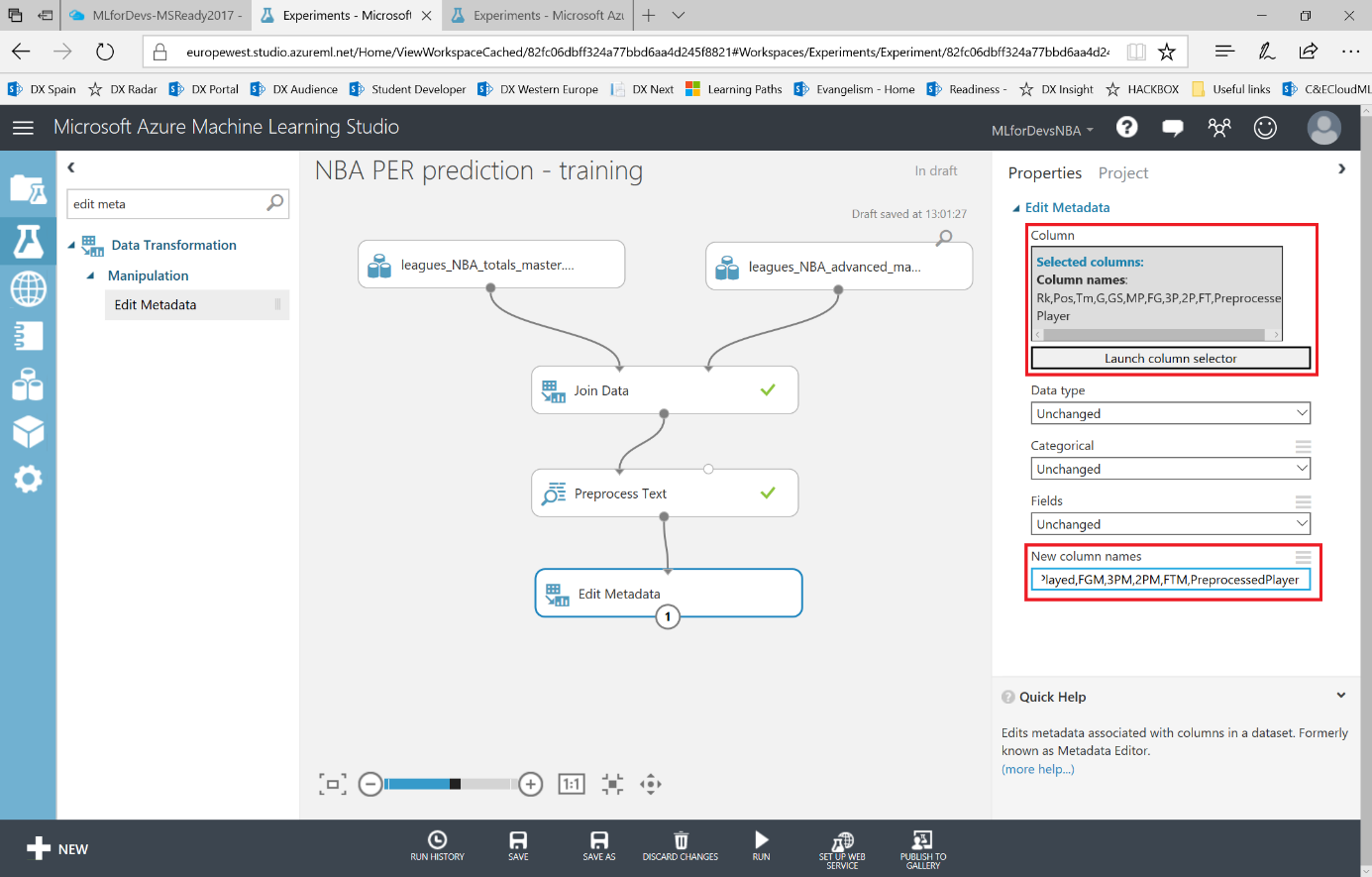
Para evitar duplicados y simplificar las cosas, asignaremos el valor "limpio" del nombre del jugador a la columna Player y también eliminaremos todas las filas de encabezado que podamos encontrar entre filas de datos. Para lograrlo, Azure ML tiene un módulo de consultas SQL que nos permitirá tratar nuestro conjunto de datos (o conjuntos de datos, hasta tres de ellos en cada módulo) como una tabla de base de datos, por lo que podemos realizar transformaciones a través de consultas t-SQL. Busca el módulo "Apply SQL transformation" en la categoría "Data Transformation > Manipulation" y conecta el conjunto de datos resultante con uno de los puntos de entrada del módulo de consultas SQL. Como tiene 3 puntos de entrada diferentes, uno para cada conjunto de datos posible, los tratará como t1/t2/t3 en la consulta. En este caso, ingresaremos una consulta simple filtrando esos valores de encabezado y reemplazando el valor Player por cada registro en nuestro dataset con la siguiente consulta:
update t1 set Player=PreprocessedPlayer;
select * from t1 where Rank<>"Rk";
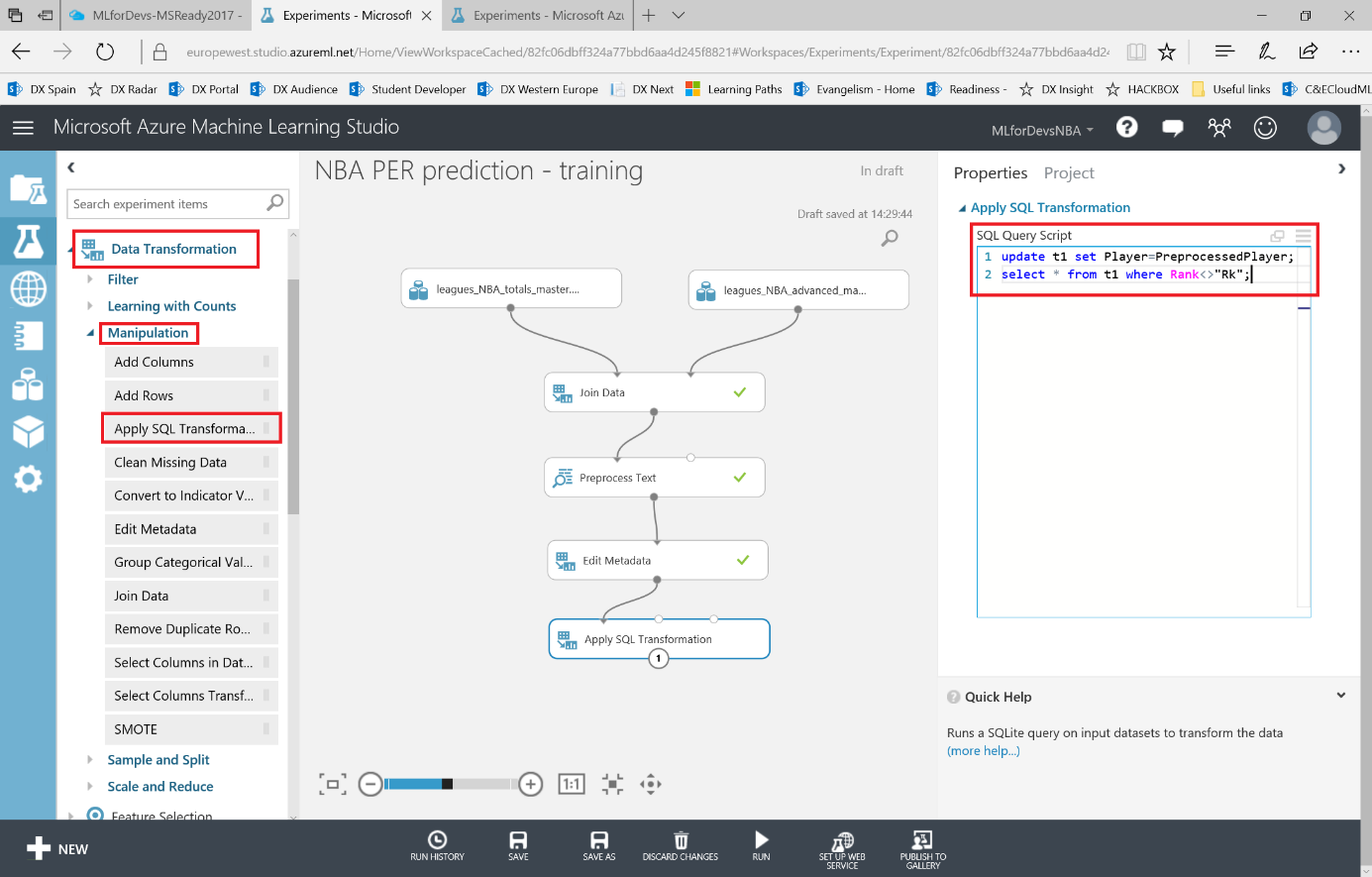
Si vuelves a ejecutar el experimento, notarás que ahora tenemos más de 14k filas en lugar de las 16k iniciales, y ninguna fila de encabezado se incluye ahora en nuestros datos.
Para realizar varias operaciones numéricas (como rangos aceptados, reemplazar valores no incluidos, etc.), debemos asegurarnos de que la herramienta esté tratando las columnas numéricas como el tipo que son (enteros o flotantes). El modulo "Edit Metadata" nos ayudará de nuevo a lograrlo, por lo que tendremos que añadir otros dos módulos, uno para las columnas de tipo Integer (Rank, Age, GamesPlayed, GamesStarted, MinutesPlayed, FGM, FGA, 3PM, 3PA, 2PM , 2PA, FTM, FTA, ORB, DRB, TRB, AST, STL, BLK, TOV, PF, PTS, Season) y otra para las columnas de tipo Floating Point (FG%,3P%,2P%,eFG%,FT%,PER,TS%,3PAr,FTr,ORB%,DRB%,TRB%,AST%,STL%,BLK%,TOV%,USG%,OWS,DWS,WS,WS/48,OBPM,DBPM,BPM,VORP), seleccionando las columnas con el selector de columnas.
Necesitamos ejecutar el experimento antes de añadir el segundo, ya que necesitará el conjunto de datos resultante anterior como entrada para el segundo, de modo que la herramienta conozca el nombre de cada columna. Una vez que tengas ambos módulos, el experimento debería tener este aspecto:
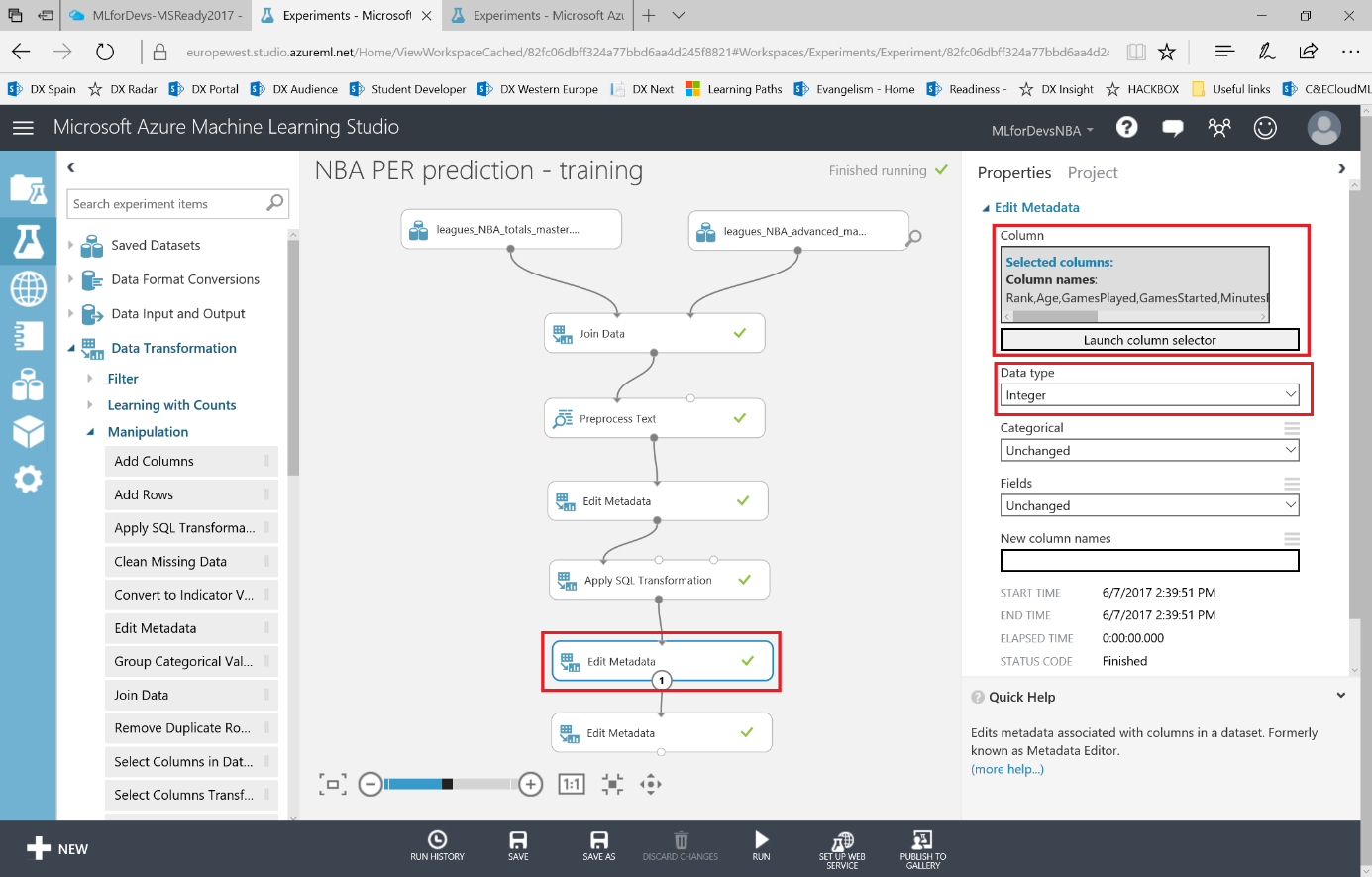
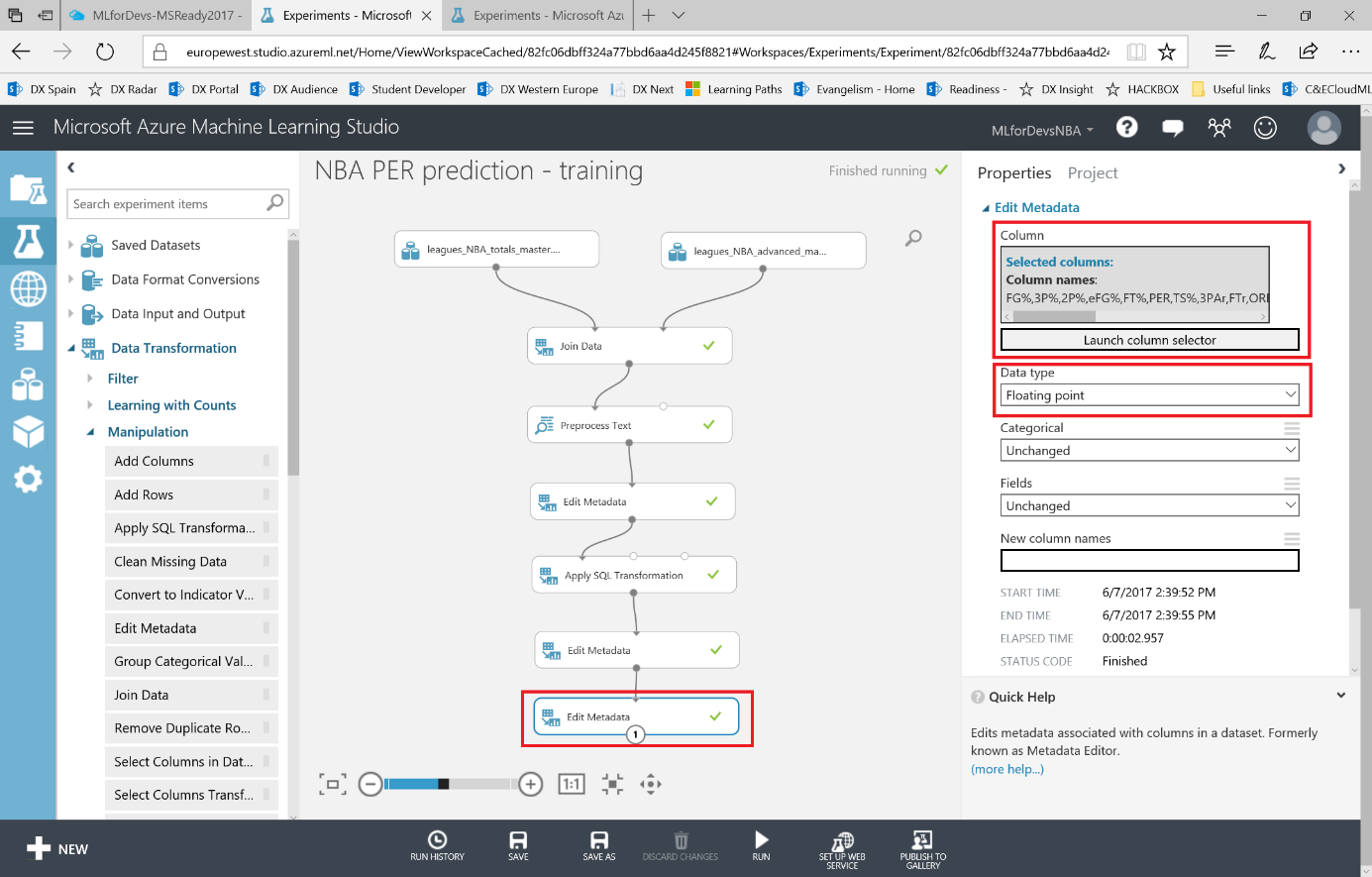
Ahora que estamos seguros de que cada columna se maneja correctamente, vamos a limpir los datos analizando cuántas veces faltan valores en las distintas columnas. Busca el modulo "Clean missing data" en el menú de la izquierda, en la categoría "Data Transformation > Manipulation" . En este caso, nos centraremos en los valores numéricos de nuestro conjunto de datos, y con este módulo podemos elegir qué hacer cuando no se encuentra un valor (podemos configurar el método de sustitución para reemplazar los valores que falten por uno de nuestra elección: media, mediana, moda, borrar la fila, borrar la columna o reemplazar usando el método Probabilistic PCA).
Normalmente, lo que debemos hacer es quitar toda la fila, pero en este caso vamos a reemplazar los valores numéricos que faltan con el valor medio seleccionando esta opción en el menú desplegable, para poder analizar cuántas veces sucedió y decidir si la característica afectada es relevante (pocas sustituciones, por lo que los datos son válidos) o no.
En este caso, ya que ya nos aseguramos de que los valores numéricos se traten como tal, podemos seleccionar las columnas por tipo en lugar de por nombre en el selector de columnas. Marca la pestaña "WITH RULES" , haz click en el botón "NO COLUMNS" y luego agrega una regla para cada tipo numérico (Numeric, Integer, Double) disponible en la lista desplegable:
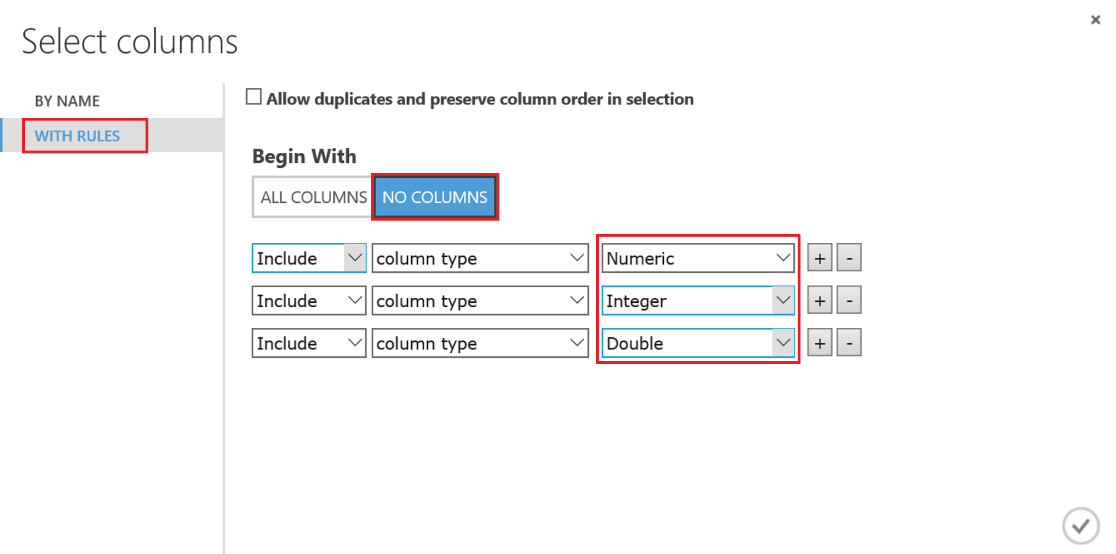
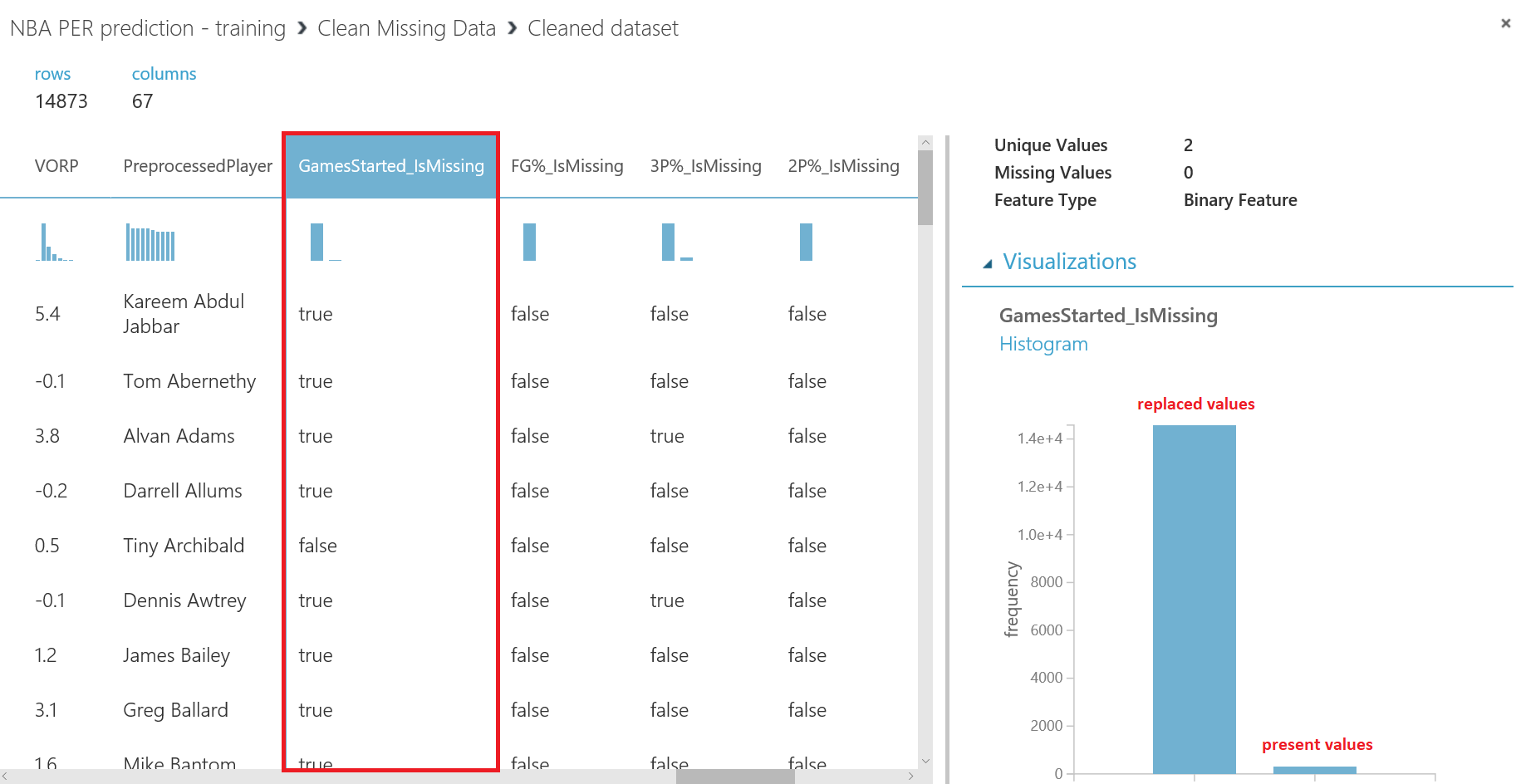
Ten en cuenta el ultimo checkbox de este módulo, llamado "Generate missing value indicator column" , ya que nos ayudará a analizar si una columna es relevante o no mediante un campo de tipo bool para ayudarnos a visualizar y entender cuántas veces se reemplazó algún dato en la columna. Marca el checkbox y ejecuta el experimento:
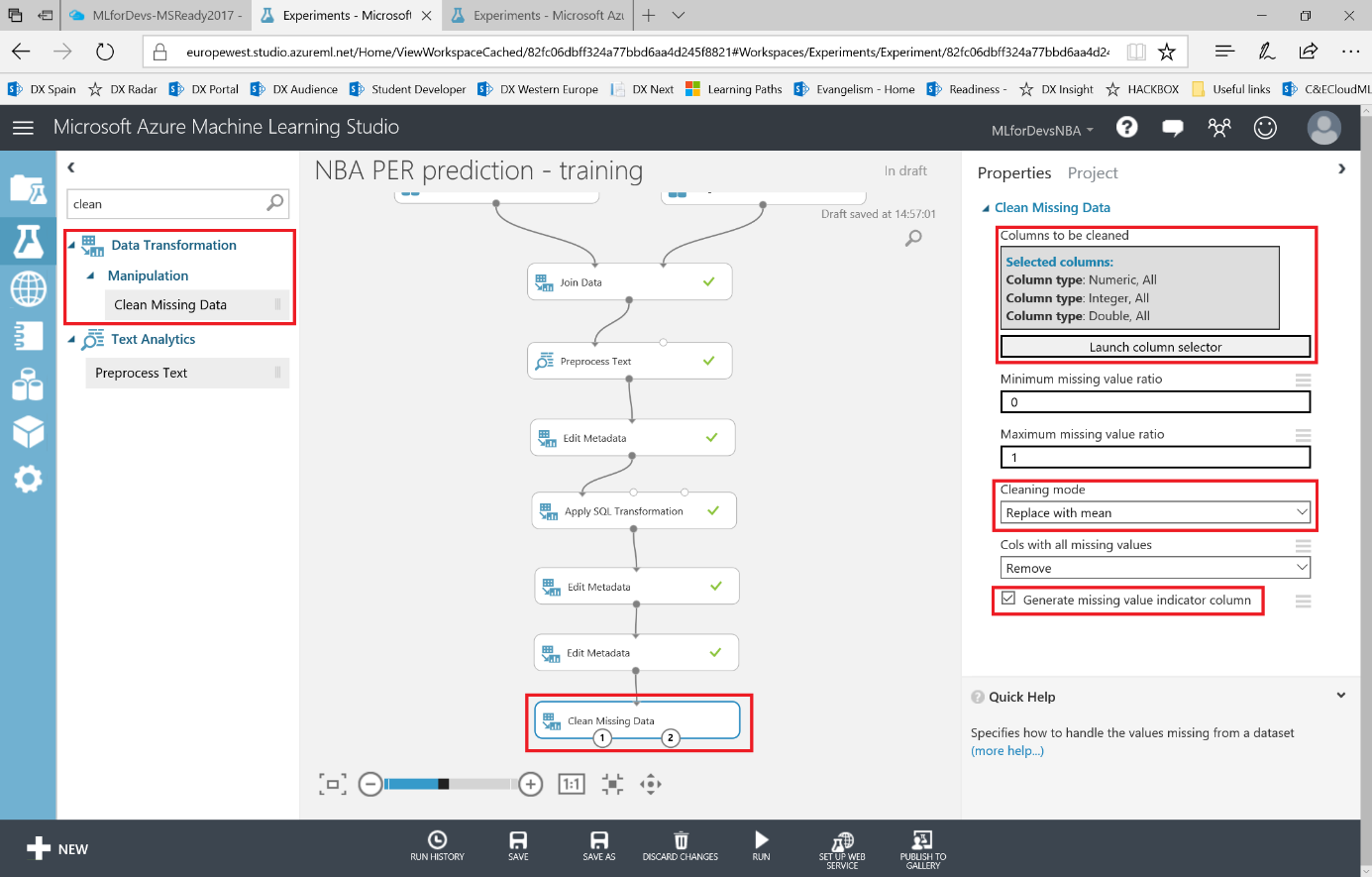
Después de ejecutar el experimento, al visualizar el dataset resultante y hacienda scroll hacia la derecha hasta las últimas columnas, podrás observar que varias columnas "<<feature_name>>_isMissing" se han añadido a su conjunto de datos, y tomando como ejemplo la columna "GamesStarted_isMissing" es fácil entender que, como los valores de esta columna han sido reemplazados la mayoría de las veces, no es relevante para nuestro experimento, ya que estaríamos utilizando más valores ficticios que reales. Para el resto de las columnas, ya que los valores reemplazados son realmente bajos, pueden seguir considerándose relevantes para el experimento:
En cualquier caso, en este experimento no usaremos todos estos valores numéricos, ya que no los conoceremos antes de la temporada y estamos buscando una predicción del PER del jugador, el valor numérico que resume su valoración y nos ayudará a seleccionar a los mejores jugadores para nuestro equipo. Seleccionaremos sólo las columnas que usaremos:
- Las entradas conocidas para nuestro experimento (Player, Position, Age, Team y Season)
- La feature a predecir (PER)
En el menu de la izquierda, busca el modulo "Select Columns in Dataset" , en la categoría "Data Transformation > Manipulation" , arrástralo al canvas y conecta su punto de entrada con el punto de salida izquierdo del módulo anterior, el que contiene el conjunto de datos resultante del paso anterior. Para seleccionar las columnas necesarias, puedes escogerlas por nombre en el selector de columnas:
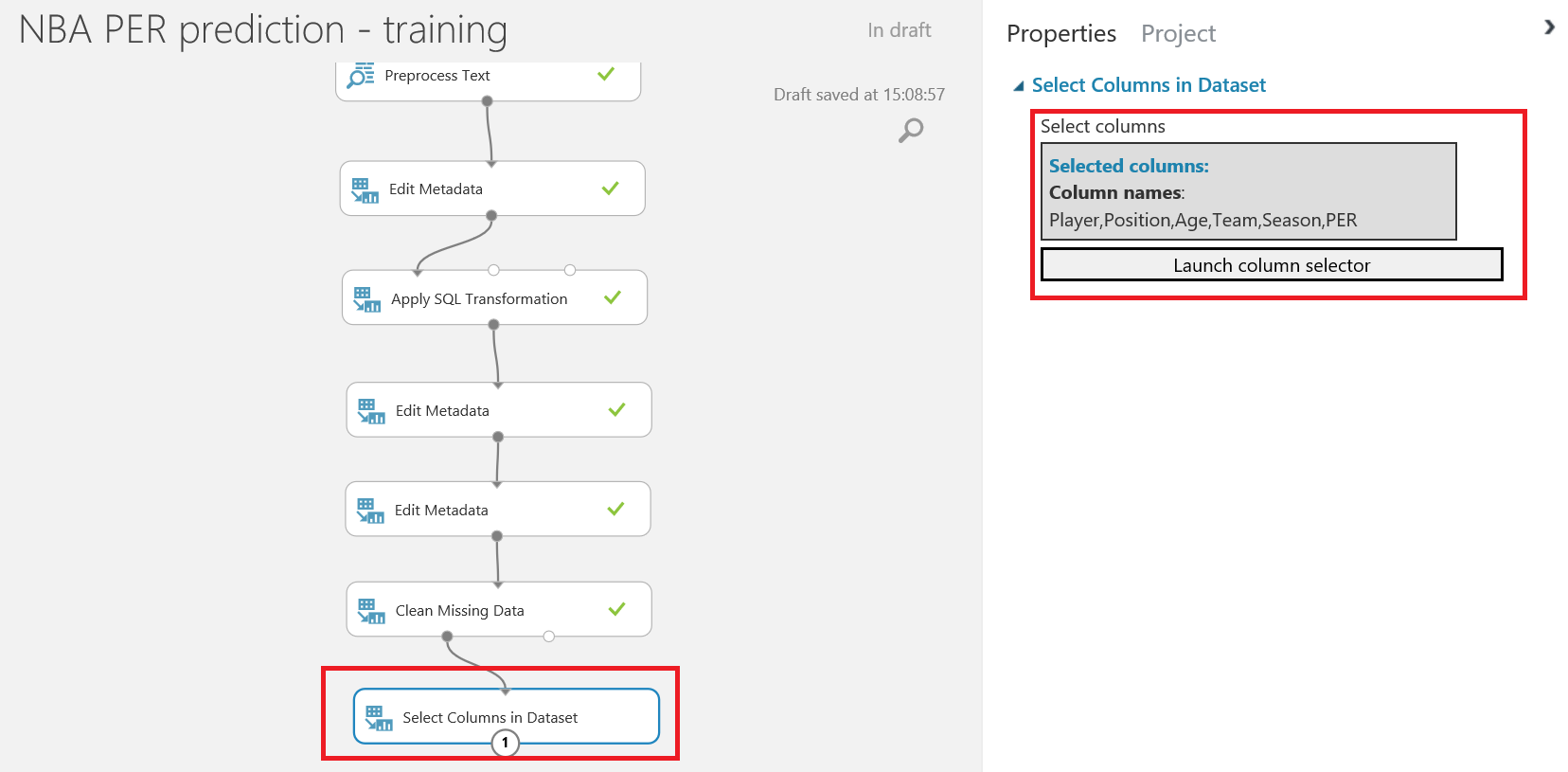
Después de ejecutar el experimento de nuevo, tendremos un conjunto de datos de 14k+ filas y 6 columnas, que utilizaremos para entrenar y evaluar nuestro modelo.
La última transformación a realizar en nuestro conjunto de datos es acotar los valores de la feature que queremos predecir, el PER (Player Efficiency Rating), ya que es una estadística bien conocida que nunca ha sido superior a 35. En este caso, también asumimos que cualquier jugador obtendrá un valor negativo de PER en una temporada completa, por lo que también recortaremos esos valores menores que cero.Lo que estamos tratando de lograr con esta acotación, tanto de peaks (valores altos por encima del umbral normal de una entidad) como de sub-peaks (valores bajos por debajo del umbral normal de la entidad), es crear un conjunto de datos normalizado, en el que la mayoría de los valores estará alrededor de la media, creando una curva de Gauss cuando se representa gráficamente. Es el mejor tipo de conjunto de datos para entrenar un modelo, ya que tendrá menos valores extremos (anómalos), y la mayor cantidad de valores será "normal", es decir, alrededor del valor promedio. Echa un vistazo a este link para aprender algo más sobre la distribución gaussiana o normal, ya que es una de las distribuciones de probabilidad de variable continua que aparece con más frecuencia en fenómenos reales.
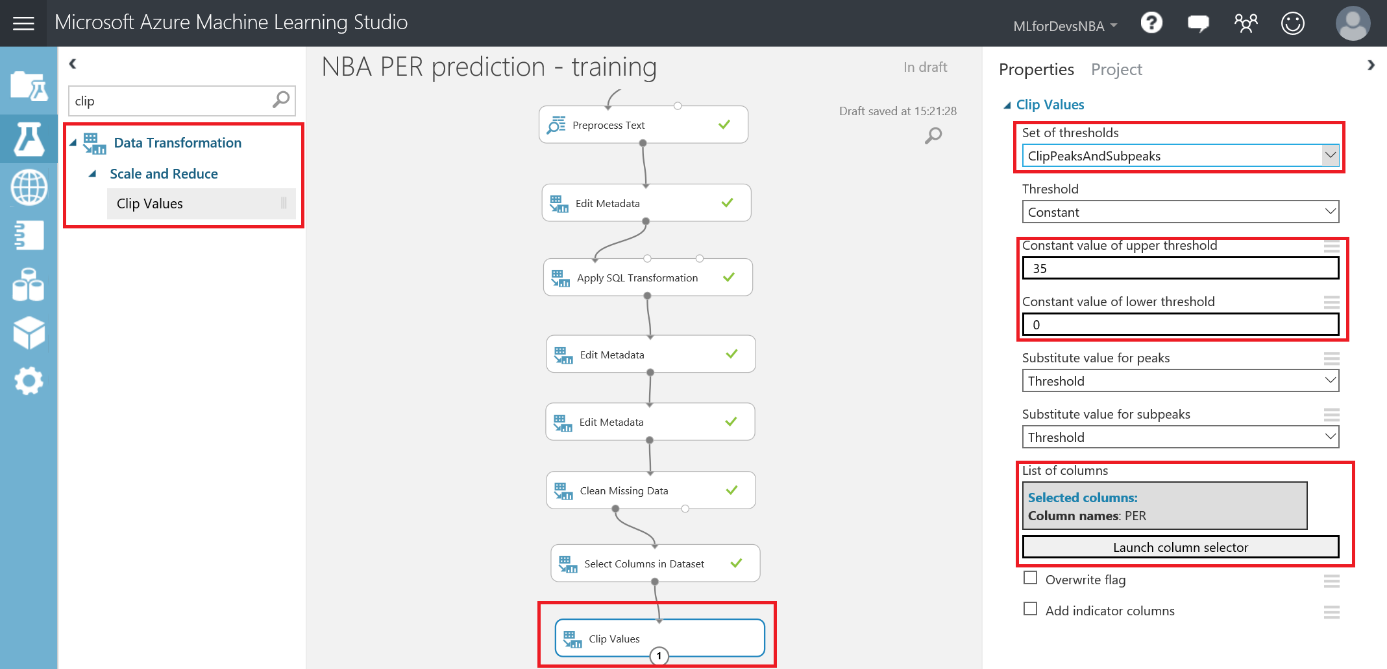
Para normalizar los valores de nuestro PER, busca el modulo "Clip Values" en la categoría "Data Transformation > Scale and Reduce" en el menú de la izquierda y arrástralo a tu canvas. Cuando lo conectes al módulo anterior, selecciona la opción "ClipPeaksAndSubpeaks" en la lista desplegable, establece los valores para el umbral superior (35) y el umbral inferior (0) ya que serán los valores máximo y mínimo aceptados, y selecciona sólo la columna PER con el selector de columnas:
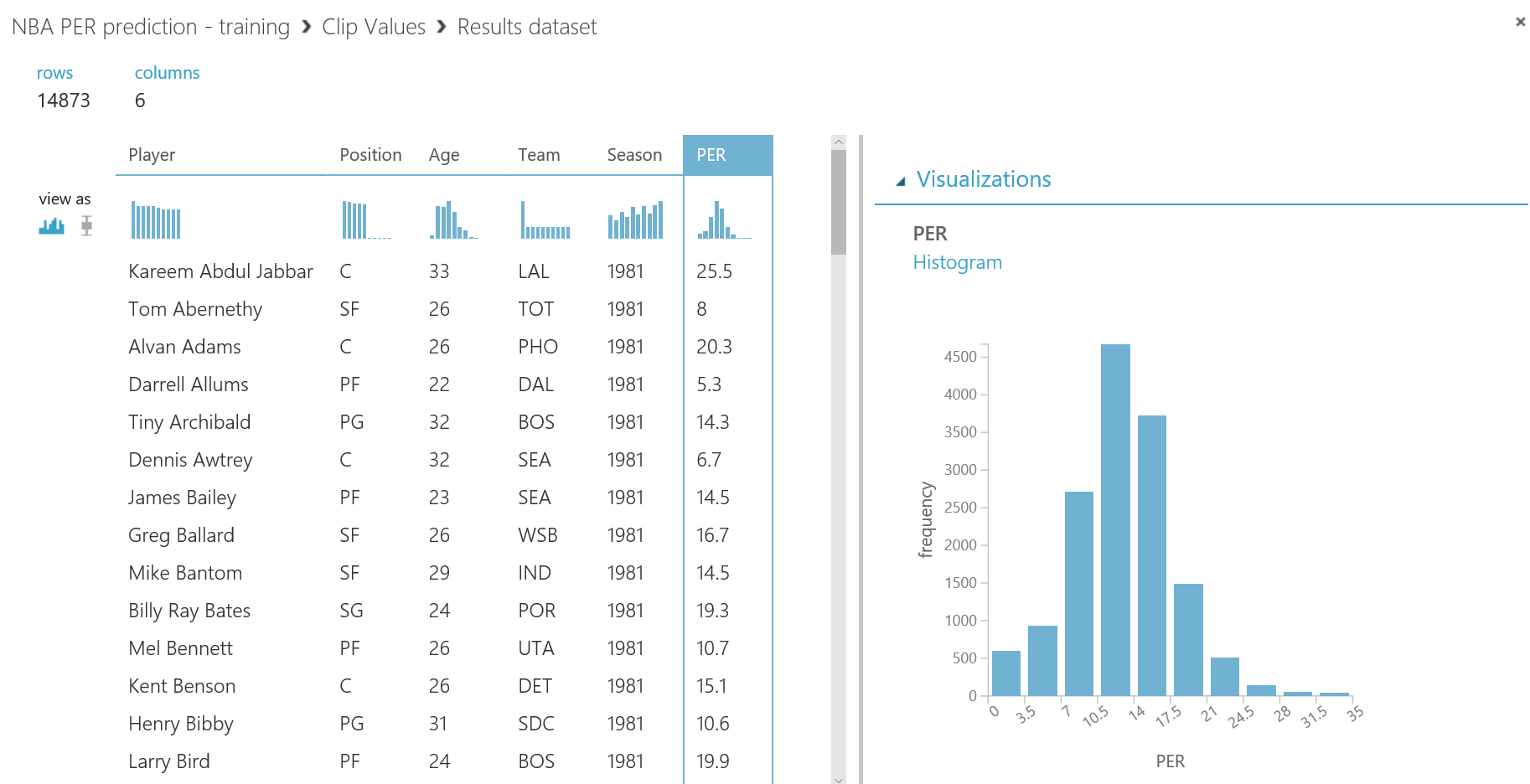
Después de ejecutar el experimento nuevamente, puedes comprobar que el PER es una distribución normal por definición. Haz click con el botón derecho en el punto de salida del modulo "Clip Values" , luego en "Visualize" , y selecciona la columna PER. En el panel derecho del pop-up de visualización, verás una representación gráfica de la columna seleccionada como un gráfico de barras verticales, mostrando una distribución normal (ligeramente sesgada a la izquierda, ya que hay más jugadores por debajo del promedio de la liga que por encima...zona también conocida como la Superstar Zone):
Con esto damos por finalizada la limpieza y preparación de nuestros datos, y en el siguiente capítulo empezaremos a entrenar nuestro modelo.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist