Agile and the Theory of Constraints - Part 1
I've been spending some time over the past few months exploring the lean side of the house and looking for things I can adapt into the agile side of the house. The most interesting thing I found was the theory of constraints.
After spending some time writing this, I realized that I need to split this into two separate posts; one where I talk about the theory of constraints in general, and the second where I talk about how I think it applies to software.
For this section, I'm going to talk about manufacturing, partly because that's where the theory was originally applied, and partly because it's more approachable. Trust me that what I write here will apply to software development.
The classic work on this is "The Goal" by Goldratt, which I highly recommend.
Let's make it better
From: Plant Manager
To: Component assembly;welding;painting;packaging
Subject: Improvement
It's time to kick off our 2016 improvement process; I would like each of you to get together with your teams and figure out what your improvement targets are going to be for next year.
Signed,
Plant Manager
If a business does improvement - and many do not - this is a pretty typical approach. And, if the word, "poorly" pops into your head, you have already figured out how well this sort of approach works. If you think we are better in the software business, you are mistaken. In general, we are quite a bit worse.
Why do these programs fail? It's very simple...
To make a process faster, you must first determine why it is slow.
I'm hoping somebody is saying, "I know why my process is slow". And you may be right, but I am also very convinced that you are also quite wrong. And that gives me a chance to introduce my first thought:
Thought 1: To improve a system, you must first understand the whole system.
If you do performance optimization of programs, you may know the first law of optimization, which is, "The part of the program that is making things slow is never the part that you think it is". If you go around optimizing the parts of the program that you think are slow, it doesn't really get much faster.
Hmm. Isn't that exactly what is happening with groups trying to get faster?
To make a program run faster, you use a tool to analyze the behavior of the whole system - a profiler. And, to make a manufacturing plant run faster,you need a similar tool.
That is what the theory of constraints can give us - a way to look at the whole system.
Our goal
When doing optimization, we need some sort of metric, or goal. In performance optimization, it's execution time.
What should our goal be? I've already asserted that "improve the output of each section" is an ineffective way to look at things, and I've said that I want to look at the overall system, so how about "improve the output of the whole plant" as a goal?
That seems good. We know how to measure it (units shipped per month), and everybody can work together to make it better. And I agree that shipping more units per month would be a good thing, but as a goal, it is an utter failure, because of a couple of simple problems.
It gives us absolutely no guidance on how to actually improve the current state; it does not tell us why the current system is slow.
It's also a bad goal for another reason; if we all pull together, we can ship a lot of really crappy product in a short period of time.
So, we need a better measure, and luckily, there is a very good one; we track the elapsed time it takes us to produce a product, from order to ship. Let's walk through how we are going to track it.
Define our process
Here is the process for our plant:
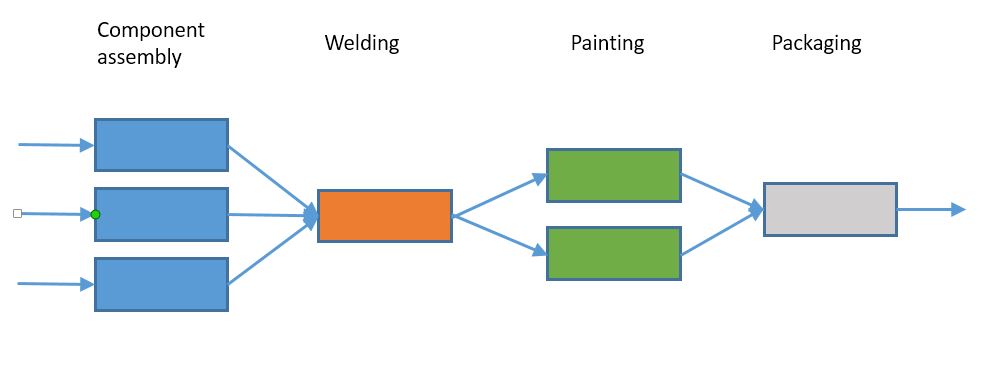
We are trying to figure out how long it takes from when we start manufacturing to when it goes out the door, so, we go out and do some measurements of how long each process takes, and add them to our diagram.
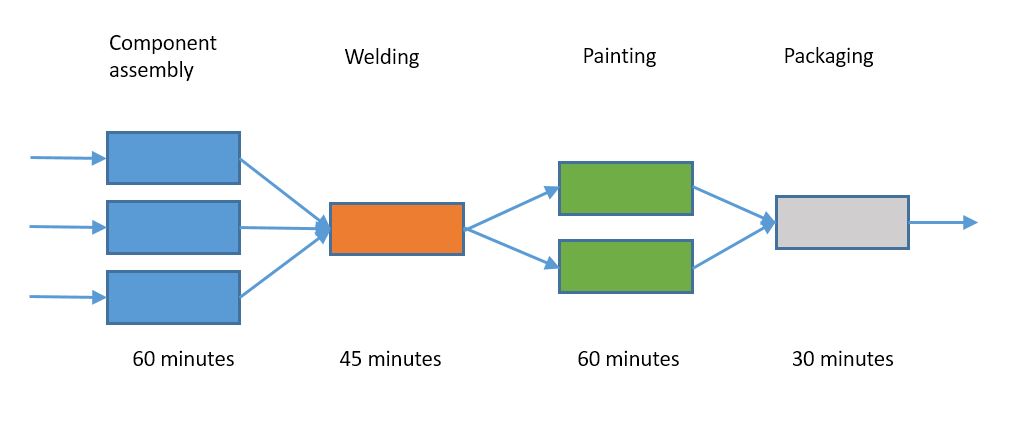
And now we know that it takes 60+45+60+30 = 195 minutes to make one item, and we can go off and start optimizing. It probably makes sense to start with component assembly and painting, since they take the longest.
Wrong.
In this scenario, the current end-to-end time for a specific item is on the order of 10 days.
Wait, what? How can it be 12 days if the process takes only a little over 3 hours to complete?
I'd like you to ruminate on the situation. There is something missing in the diagram that I drew, and it's something that I could easily have measured when I went out and measured the time each individual step. What is missing?
(spoiler space)
An improved picture
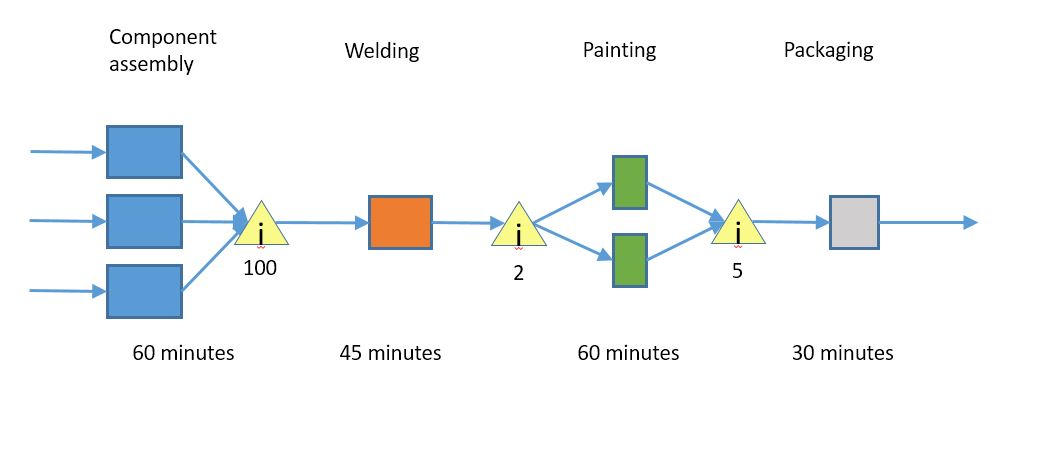
What I was missing was the concept of inventory. Whenever there is a handoff between two steps, there may be an accumulation of inventory. That is where the extra time is; we have 100 items waiting to be welded, so each item will have to wait for the 100 items in front of it to be processed first. That will take 4500 minutes, or about 75 hours. There are two items waiting for painting, so that is 1 hour of time there, and the 5 items waiting to be packed add 2.5 hours of time.
So the total time is 75 + 1 + 2.5 = 78.5 hours of lag + 3 hours of processing = 81.5 hours, or a little over 10 days.
<aside>
Why is inventory bad?
Inventory is bad, let me count the ways:
- It ties up a lot of capital; we have invested money in the raw materials and the labor to create the intermediate state. If the inventory was lower, we could deploy that capital elsewhere or we could improve our return on investment.
- We don't know how good it is. If our component assembly starts producing poor-quality items, it will be nearly 10 days until we find out, and we will have to throw away/rework a lot of expensive items.
- The items in inventory represent things that we think we need, but our plans may change during that time, leaving us with intermediate items that are of little use.
- We have to pay to store it, track it, move it around, etc.
</aside>
The diagram I've created is a very simple version of a value stream map. And the times I used are pretty conservative; it isn't uncommon for the end-to-end time of a single item to be measured in months.
We're going to put aside the amount of inventory for a moment, and focus on the steps.
Now, can we make it better?
Do we know where we are slow?
The answer is "yes". Looking at the diagram, we can tell that we have an issue with the welding process. You can do it mathematically; component assembly is capable of creating 3 items per hour, but welding can only do 1.3 items per house. Or, you can just look for the places where inventory piles up in the factory.
Saying welding is slow is really a misstatement; there may be absolutely nothing wrong with the welding process; what we have discovered is that the welding process is a bottleneck in our system. Because it is the slowest step, it is constraining the output of the system to be - at best - one item every 45 minutes.
That concept is why the theory of constraints is named what it is - we have a constraint, and it controls the output of the whole system.
Let's now cast our minds back to my earlier assertion that "everybody get better" programs don't work, and see whether this diagram can shed any light on the situation. What happens to the system if we improve the speed of component assembly, painting, or packaging?
That's right, pretty much nothing. Which leads to:
Thought #2: If you aren't addressing the bottleneck, you won't improve the overall system performance
Given that few groups know what their bottlenecks are, it's not surprising that their attempts at optimization don't improve their system performance.
Now that we have a target, it's time to talk about ways to address it. There are a few options:
- Increase capacity (buy more equipment). This is the go-to option in most cases, because most groups don't know how to optimize. It's also the priciest.
- Optimize the bottleneck. Look at the process of the bottleneck in detail, and see if there is a way to optimize it. This might mean creating a separate value stream map for the bottleneck. Can we get better utilization out of the machine?
- Subordinate the other parts of system to the constraint.
Let's talk about the third one, because it's the least obvious and therefore most interesting one. Looking at the picture again, we have a lot of excess capacity in component assembly. We do a little investigation, and discover that about 20 minutes of the welding work isn't welding work, it is "getting ready to weld" work. Let's modify our process again.
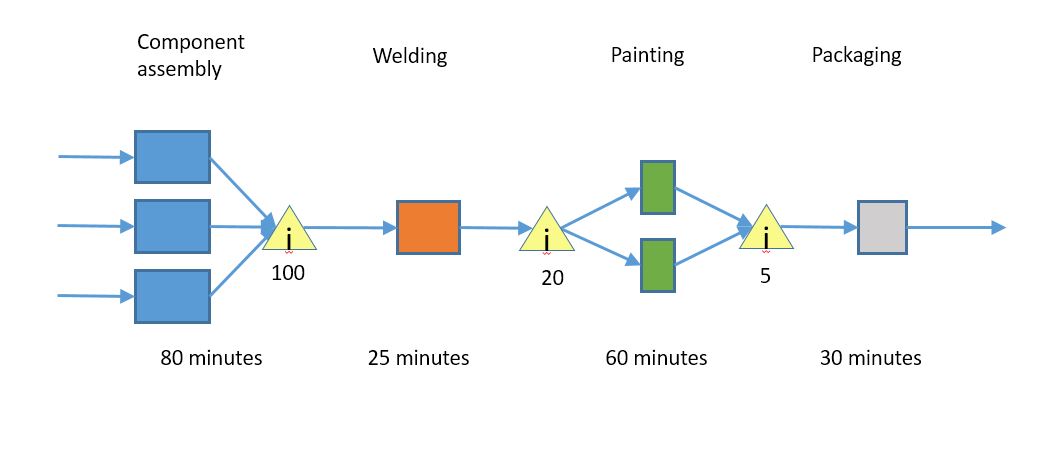
We pulled 20 minutes of work out of welding and added it to assembly. What is our total end-to-end time?
Well, our welding queue is now 100*25 = 2500 minutes, or 42 hours, but the painting queue has gotten bigger, and now has 20 hours. Total is 42 + 20 + 2.5 = 64.5 hours, a significant improvement. Note that the queue sizes I chose were for purpose of illustration.
And how did we do that? We did it by moving work to the component assembly step; it is now a full 20 minutes slower than it was before, but it being slower had no impact on the overall system, because it still produces items faster than the welding step can consume them.
Thought 3: Sometimes the best way to improve a bottleneck is to de-optimize the steps around it.
This is another "wait, what?" moment; one step got slower, and the overall system got faster. It's a little easier to see if I add in a little table:
| Step | items/hour before | items/hour after |
|---|---|---|
| Component assembly | 3 | 2.5 |
| Welding | 1.3 | 2.4 |
| Painting | 2 | 2 |
| Packaging | 2 | 2 |
It's pretty obvious why we had a big queue in front of welding in the first case. It's still slower than component assembly, but it is now faster than painting, so we are seeing a queue show up there. And we pushed our overall system performance up to 2.4 items per hour.
Which leads to another question. Is welding still the bottleneck?
The answer is obviously "no"; painting and packaging are the bottlenecks now. So, that is where we would work next.
Rework
I made a simplifying assumption for the earlier diagrams; I assumed that all of our processes were perfect. But, in reality, they aren't, so it would be good to add that to our diagram.
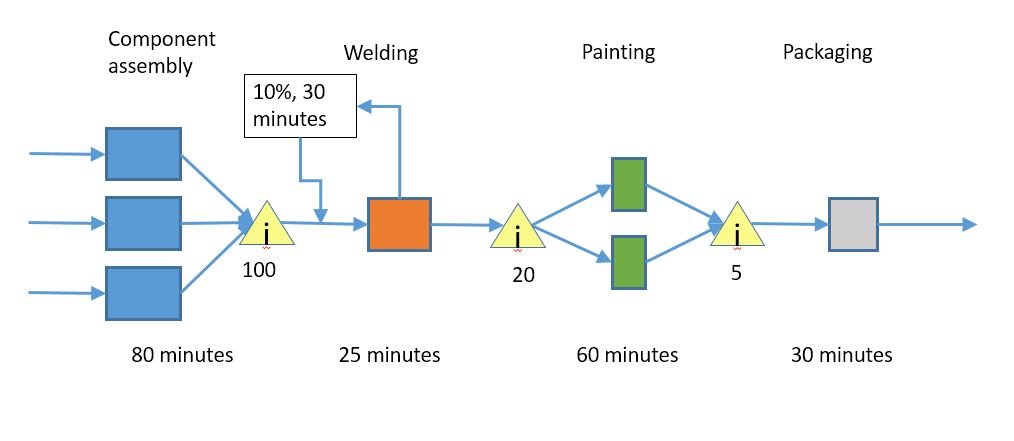
This is one way of expressing rework. It says that 10% of the time, we spend an extra 30 minutes on welding to fix issues from the previous step, so that bumps the average welding time up to 28 minutes. There can also be inventory before or after the rework part; as you might expect, this can bump up the end-to-end time significantly.
What to do with inventory
After improving our throughput, we still had one big queue and we were starting to accumulate another. In a perfect world - where every step was matched in capacity - our queues would be a fixed size, but that never really happens; there is always a bottleneck one place or another. And, as we notice, our end-to-end time is heavily dominated by the time due to the queues.
If we let the system parts free-run, that will lead to the accumulation of a ton of inventory over time, which is very bad. The most common approach is to switch from a push system - where the previous step just runs flat-out - to a pull system - where the previous step runs when the next step needs more items. This is commonly known as a "just in time" approach, and in it's simplest incarnation, you set an inventory trigger point (say, of a few hours inventory) that lets the previous step know it should start running again.
If we take our queues down to half a day, we would only end up with 1.5 days worth of inventory in the system, taking the overall end-to-end time down to around 2 days. That cuts our inventory cost down to about 20% of what we had before, and our agility is up a similar amount.
But... this change isn't free. Since we are carrying less inventory, we need to watch the system a little more closely to make sure that we don't run out.
Because our component assembly step has excess capacity, we will need to run it slightly slower so inventory doesn't build up. This approach flies in the face of traditional management philosophy; we are specifically telling a group to either slow down or do something else during the down time.
Setup time
It's pretty common for a single machine/team to do multiple things. In that case, there is a setup time overhead to switching from doing one thing to another. Implementing pull systems will tend to drive the batch size down, and it's important to remember that there is overhead to consider.
Summary
After writing this, I went out and looked at the defined steps of the theory of constraints again, to see how I did. Here are the steps:
- IDENTIFY the system's constraint.Okay, I covered that.
- EXPLOIT the constraint"Exploit" here means "do whatever you can to optimize within the constraint". I forgot this one initially but went back and added it.
- SUBORDINATE everything else to the constraintThis is the part about being willing to de-optimize another area to speed up the constrained part.
- ELEVATE the constraint.If it's still a constraint, this is when you throw money at the situation; buy new machines, that sort of thing.
- PREVENT INERTIA from becoming the constraint.If you addressed one constraint, your new constraint moved somewhere else. You'll need to think of that next.
That's all for the introduction to the theory of constraints. In my next post, I'll take the techniques that I talked about and apply them to the software world.