Public Preview of Table Variable Deferred Compilation in Azure SQL Database
Last year SQL Server 2017 and Azure SQL Database introduced query processing improvements that adapt optimization strategies to your application workload’s runtime conditions. These improvements included: batch mode adaptive joins, batch mode memory grant feedback, and interleaved execution for multi-statement table valued functions.
In Azure SQL Database, we will be further expanding query processing capabilities with several new features under the Intelligent Query Processing (QP) feature family. In this blog post we’ll discuss one of these Intelligent QP features that is now available in public preview in Azure SQL Database, table variable deferred compilation.
Table variable deferred compilation improves plan quality and overall performance for queries referencing table variables. During optimization and initial compilation, this feature will propagate cardinality estimates that are based on actual table variable row counts. This accurate row count information will be used for optimizing downstream plan operations.
What are the performance issues associated with table variables?
Years ago, table variables were originally designed to reduce excessive recompilation issues compared to temporary table equivalents. When a query that references a table variable is initially compiled, the table variable is compiled along with all other statements in the batch. Since table variables are compiled along with all other statements, we do not know the actual row count at compile-time and so a fixed guess of one row is used. Operations downstream from the table variable also assume a single row.
If the table variable ends up containing a low number of rows, typically this single row guess is not problematic. However, if the actual row count is higher, this can result in downstream inappropriate plan choices and significant performance issues.
The following example demonstrates the problem scenario. We first create a table variable containing order key rows based on specific conditions related to quantity, discount value and ship mode (populating 77,341 rows into the table variable):
DECLARE @lineitems TABLE
(L_OrderKey INT NOT NULL PRIMARY KEY,
L_Quantity INT NOT NULL
);
INSERT @lineitems
SELECT DISTINCT L_OrderKey, L_Quantity
FROM dbo.lineitem
WHERE L_Quantity > 49
AND L_Discount = 0.03
AND L_ShipMode IN ('FOB', 'TRUCK', 'RAIL', 'SHIP', 'AIR');
Within the same batch, the following query joins to the table variable, returning customer key and quantity and sorting by quantity in descending order:
SELECT O.O_CustKey, LI.L_Quantity
FROM dbo.orders AS O
INNER JOIN dbo.lineitem AS LI ON
O_OrderKey = L_OrderKey
INNER JOIN @lineitems AS TV ON
TV.L_OrderKey = LI.L_OrderKey
ORDER BY LI.L_Quantity DESC;
The execution time for this example is 5 seconds and the actual query execution plan is as follows (with numbering used to point out key areas of interest within the plan):
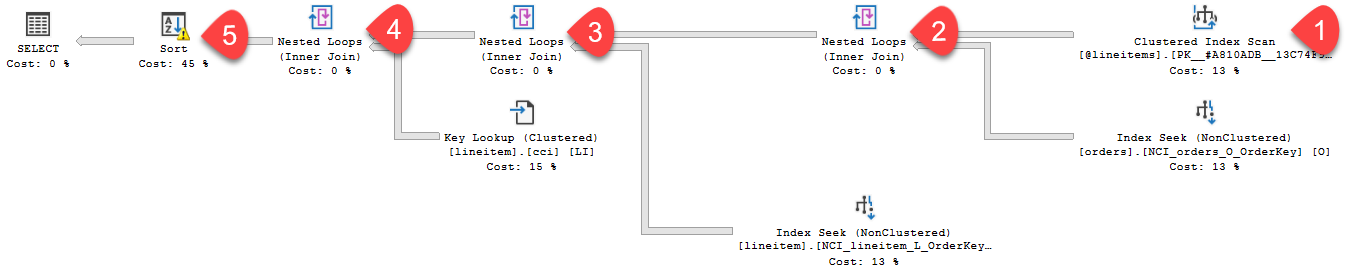
Noteworthy areas:
- In the plan – for #1 we have a clustered index scan against our table variable. We also assume in the old behavior that one row will flow from this table variable.
- This effects our downstream join algorithm choices (nested loops seen for #2, #3, and #4).
- And lastly, for #5 in the plan for the sort operation, we see a warning symbol within the operator - indicating a spill to disk due to insufficient memory grant size.
Looking at the properties of the table variable, we see an estimated number of rows equal to 1 and actual number of rows equal to 77,341:
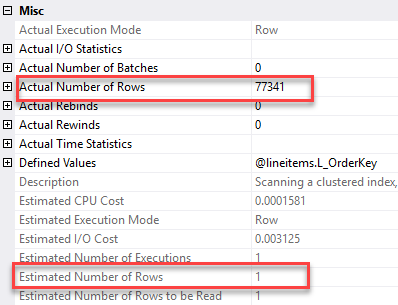
So our fixed guess assumes a low row count – and downstream operations are chosen during optimization accordingly.
How was this issue addressed in the past?
Prior to the table variable deferred compilation feature, performance issues due to table variable misestimates could be worked around using any of the following techniques:
- Using temporary tables instead of table variables (requires recoding).
- Adding OPTION(RECOMPILE) at the statement level. This can be problematic given that one of the major reasons for using table variables is to avoid recompiles (and keep CPU utilization low).
- Enabling trace flag 2453. This trace flag allows a table variable to trigger recompile when enough rows are changed.
- Use explicit plan hints, for example, hash join hints.
While these workarounds may sometimes be viable, table variable deferred compilation provides a solution that doesn’t require changes to application code and doesn’t require the use of a trace flag.
What changes with the new table variable deferred compilation feature?
With table variable deferred compilation, compilation of a statement that references a table variable is deferred until the first actual execution of the statement. This is identical to the behavior of temporary tables, and this change results in the use of actual cardinality instead of the original one-row guess.
Revisiting our prior query example, with table variable deferred compilation execution time is reduced because of improved plan quality (before it was 5 seconds, with table variable deferred compilation, execution time for this example is 1 second). The new plan is as follows:
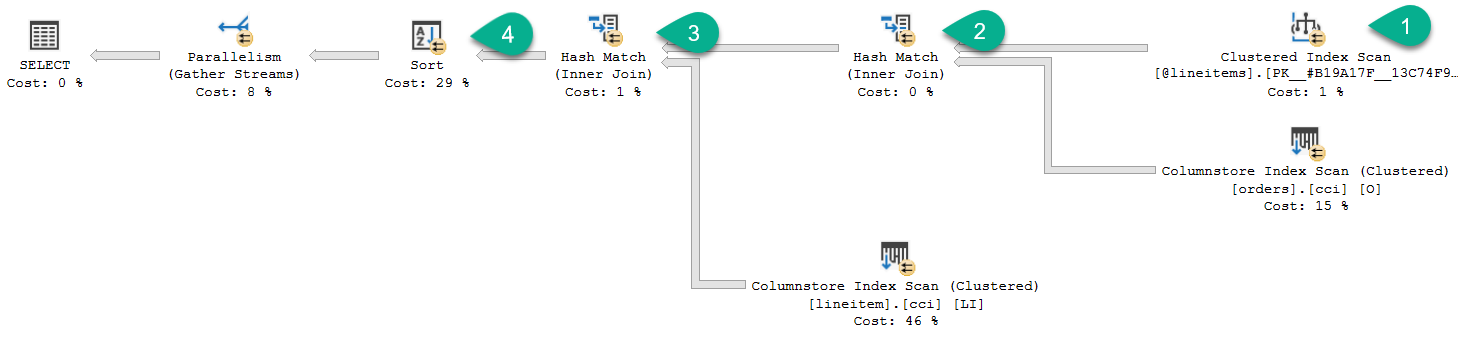
Noteworthy areas:
- In the plan – for #1 we have a clustered index scan against our table variable which is now running in parallel (indicated by the parallel symbol in the yellow circle). In fact, each operator runs in parallel vs. the prior serial plan.
- Notice for #2 and #3 we are now using a hash join.
- For #4 we no longer see a warning for our sort as we are asking for enough memory and are not spilling to disk.
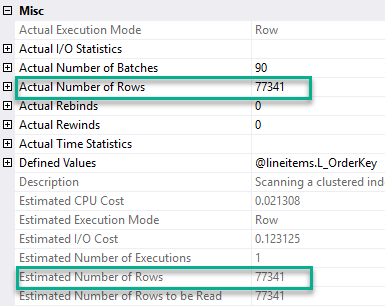
Looking at the properties of the table variable, we now see an estimated number of rows equal to 77,341 and actual number of rows equal to 77,341:
Are any other table variable characteristics changed with this feature?
We have not changed any other characteristics of table variables.
Does this improvement also add column statistics for table variables?
No. We have only changed the timing of when a table variable statement gets compiled.
I’d like to test this new feature. How do I get started?
To enable the public preview of table variable deferred compilation in Azure SQL Database, enable database compatibility level 150 for the database you are connected to when executing the query:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Where can I provide feedback?
If you have feedback on this feature, please email us at IntelligentQP@microsoft.com.