[SQL Azure] Unicode型列(NCHAR/NVARCHAR) に格納されるデータが “?” になる
みなさんこんにちは、SQL Azure サポートチームです。
SQL Azure に関するお問い合わせの中で、よくあるお問い合わせの一つを紹介したいと思います。
[質問]
SQL Azure データベース上のテーブルにUnicode 型列 (NCHAR/NVARCHAR) を作成し、日本語文字を挿入したところ、Insert コマンドは正常に完了したが、SELECT 文で挿入したデータを参照すると、”?” が表示され、挿入した日本語文字を参照することができないのは何故?
[回答]
Unicode 型列 (NCHAR/NVARCHAR) に挿入されたデータが “?” になるのは、挿入した日本語文字を非Unicode から Unicodeへ変換ができなかったためとなります。
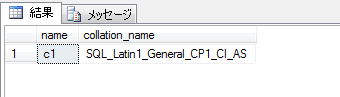
SQL Azure 上にデータベースを作成時に明示的に照合順序を指定しなかった場合、データベース照合順序は既定で “SQL_Latin1_General_CP1_CI_AS” が使用されます。また、このデータベース上に明示的に列の照合順序を指定せずテーブルを作成した場合、データベースの照合順序が引き継がれるため、列の照合順序も “SQL_Latin1_General_CP1_CI_AS” となります。



{kind=link}
上記テーブル “tab1” の Unicode型列 “c1” に対して、以下の INSERTクエリで ”あ” を挿入します。

しかしながら、テーブルには “あ” ではなく “?” が挿入されます。


Japanese_CI_AS などの日本語照合順序での文字 “あ” は、文字コード 0x82A0として表現されますが、上記の例の場合、データベースの照合順序が SQL_Latin1_General_CP1 であるため、 ”あ” を表現しているつもりの文字コード 0x82A0 は、実際には “あ” ではなく SQL_Latin1_General_CP1 の文字として扱われます。尚、SQL_Latin1_General_CP1 の文字コード 0x82A0 に対応する Unicode 文字が存在しません。その結果、 ”あ” の変換結果は “?” となり、テーブル列に “?” が格納されることになります。
[対処方法]
非 Unicode から Unicode への変換が発生しないよう、挿入する日本語文字の前に N プレフィックス を指定します。

N プレフィックスを指定することで、この “あ” は Unicode 文字 0x3042 になり、INSERT時に非Unicode から Unicode への変換が発生しないため、データベースの照合順序が何であるのかに関わらず、日本語文字の “あ” としてテーブルの列に挿入されます。
もし挿入する値をパラメータで渡している場合は、T-SQL であれば、パラメータのデータ型を VARCHAR型ではなく NVARCHAR として定義します。

[参考情報]
[SQL Azure] データベース照合順序の指定について (新機能)
※ 本Blogの内容は、 2012年5月現在の内容となっております。
--
Support Engineer
Nobushiro Takahara