Amplified Flooding Attacks
Today's article is about a classic flooding attack that relies on a receiver who isn't careful about where it sends responses. The whole article is about this next picture, so if you don't have images then you're going to miss out.
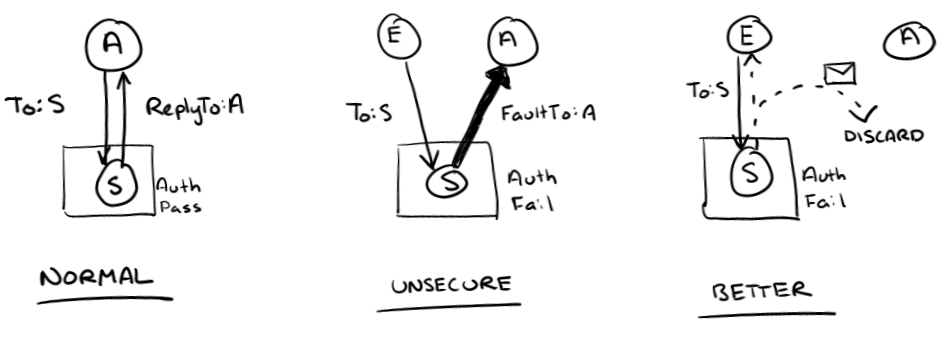
The way that the attack works is that it relies on a receiver who sends replies or faults without having verified the reply address. In the normal case, replies go to some address that is controlled by the requestor. This is okay if we know who the requestor is and trust them.
However, now suppose that we don't trust the requestor, perhaps because we've failed to authenticate them. An evil requestor can claim that replies should go off to some third-party address. There are a lot of systems where a very small request, remember it doesn't have to be valid at all, generates a much larger reply. In essence, the evil requestor is amplifying its attack power because it only needs the bandwidth for a 10 byte request to cause 1000 bytes to be thrown at the target machine.
Stopping this attack is quite simple, although it can cause problems with the design of a distributed system. The receiver only sends replies to an address that is known to be owned by the requestor. That is a very simple rule to follow. If the requestor is authenticated, then the receiver trusts its claim of owning the reply address. If the requestor is not authenticated, then the receiver only sends replies along an associated back channel. Any replies that were supposed to be directed to any machine other than the requestor's are discarded. The attack is now stopped, although it breaks scenarios where the requestor wasn't authenticated but the requestor also wasn't being evil.
Next time: Reducing Memory Usage with Large Messages